







1.概述
1.1 论文相关
题目:多标签文本分类的标签特定文档表示(Label-Specific Document Representation for Multi-Label Text Classification)
发表时间:2019年
1.2 动机
多标签文本分类允许在一个文档中共存多个标签,因此,标签之间存在语义相关性,因为它们可能共享相同的文档子集。同时,文档可能较长,复杂的语义信息可能隐藏在嘈杂或冗余的内容中。此外,大多数文档属于很少的标签,而大量的“尾标签”只包含很少的积极文档。为了处理这些问题,研究人员非常关注以下三个方面:
- 如何从原始文档中充分捕获语义模式
- 如何从每个文档中提取与相应标签相关的鉴别信息
- 如何准确地挖掘标签之间的相关性。
在多标签文本分类任务中,每段文本对应一个或者多个标签,而有些标签以文本组件的形式出现在文本中.因此作者提出了一种新的标签特定注意网络模型(LSAN),通过充分利用文档内容和标签内容来学习文档表示。这个方法主要分为三个步骤:
- 为了从每个文档中获取与标签相关的组件,我们采用了自我注意机制来衡量每个单词对每个标签的贡献。
- 同时,LSAN利用标签文本将每个标签嵌入到单词嵌入等向量中,从而可以显式地计算出文档单词与标签之间的语义关系.
- 最后,设计了一种自适应融合策略,从这两个方面提取适当的信息,并为每个文档构建特定于标签的表示。
本论文的贡献:
- 提出了一种通过同时考虑文档内容和标签文本来处理多标签文本分类任务的标签特定注意网络模型。
- 首先设计了一种自适应融合策略,以自适应地提取适当的语义信息来构建特定于标签的文档表示。
- LSAN的性能在四个广泛使用的基准数据集上进行了深入的研究,表明了它相对于最先进的基线的优势。
1.3 代码
地址:https://github.com/EMNLP2019LSAN/LSAN/
2.算法
介绍一下LSAN的主要方法,主要从以下几个方面进行介绍:
- 利用文档内容和标签文本,从每个文档中捕获与标签相关的组件
- 从两个方面自适应地提取适当的信息
- 分类模型可以在融合的标签特定的文档表示上进行训练
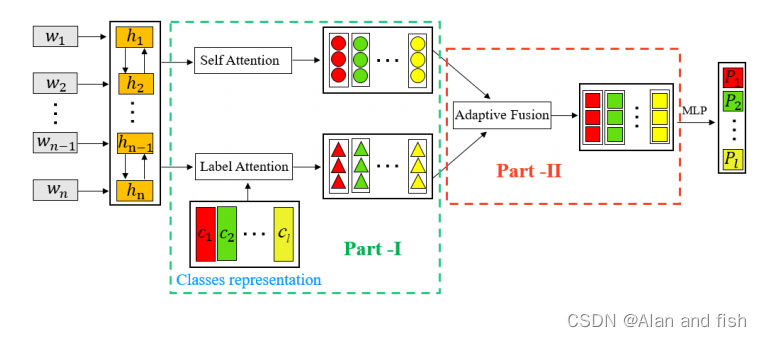
图1:所提出的标签特定注意网络模型(LSAN)的体系结构。
2.1 准备工作
2.1.1 问题定义
- D= ( x i , y i ) i = 1 N {(x_i,y_i)}^N_{i=1} (xi,yi)i=1N表示文档的集合,它由N个文档组成,对应的标签为Y={ y i ∈ { 0 , 1 } l y_i∈\{0,1\}^l yi∈{0,1}l},其中l表示总的标签数量.每个文档都包含一系列的单词。每个单词都可以被编码到一个低维空间,并通过word2vect技术表示为一个d维向量.
- x i x_i xi={ w 1 , . . . . . . , w p , . . . . . . . . . . . , w n w_1,......,w_p,...........,w_n w1,......,wp,...........,wn}表示第i个文档, w p ∈ R k w_p ∈ R^k wp∈Rk是文档中的第p个单词的向量,n为文档中的单词数.
对于文本分类,每个标签都包含文本信息。因此,有的会与文档中的单词相似,一个标签可以表示为一个embedding向量,标签集将编码成一个可训练矩阵 C ∈ R l ∗ x C∈R^{l*x} C∈Rl∗x。给定输入的文档及其相关的标签D,MLTC任务的目标是训练一个分类器来为即将到来的新文档分配最相关的标签。
2.1.2 输入文本表示
为了获取每个单词的前后边的上下文信息,我们采用双向长短期记忆(Bi-LSTM,用语言模型来学习每个输入文档的单词的embedding。在时间步长p,隐藏状态可以通过输入和(p−1)第1步输出来更新。
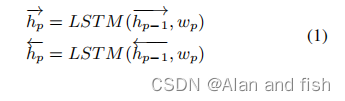
其中,
w
p
w_p
wp为对应文档中第p个单词的embedding向量,
h
p
→
\overrightarrow{h_p}
hp,
h
p
←
\overleftarrow{h_p}
hp∈
R
k
R^k
Rk分别表示正向和后向单词上下文表示。然后,整个文档可以用Bi-LSTM表示如下。
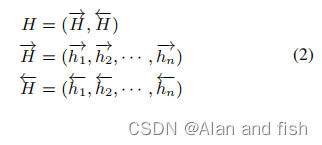
在这种情况下,整个文档集可以作为一个矩阵H ∈
R
2
k
∗
n
R^{2k*n}
R2k∗n
2.2 标签特定注意网络
在本小节中,我们将给出所提出的标签特定文档表示学习的注意网络模型.它的目的是从每个文档中确定与标签相关的组件。实际上,这种策略对于文本分类是很直观的。
举个栗子:“六月,一个星期五,在草坪上,一场足球运动开始时的小男孩之间的战争”,它被分为"青年运动"和"体育运动"两类。显然,“小男孩”一词的内容更多地与年轻人有关,而不是与体育运动有关,而“足球比赛”则应该与体育运动直接相关。接下来,我们将展示如何用我们的模型来捕获这个特征。
2.2.1自注意力机制
如上所述,多标签文档可以由多个标签进行标记,并且每个文档应该与其相应的标签具有最相对的上下文。换句话说,每个文档可能包含多个组件,并且一个文档中的单词对每个标签都有不同的贡献。为了捕捉每个标签的不同组件,我们采用了自我注意机制,它已被成功地用于各种文本挖掘任务中,标签词注意得分(
A
s
∈
R
l
×
n
A^s∈R^{l×n}
As∈Rl×n)可以通过下面的方法获得:
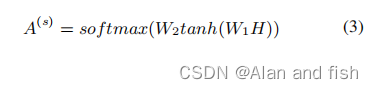
其中
W
1
∈
R
d
a
∗
2
k
W_1∈R^{d_a*2k}
W1∈Rda∗2k和
W
2
∈
R
l
∗
d
a
W_2∈R^{l*d_a}
W2∈Rl∗da被称为训练时候需要的自注意力参数.
d
a
d_a
da是一个我们可以任意设置的超参数。每一行
A
j
(
s
)
A^{(s)}_j
Aj(s).(一个n维的行向量,其中n是单词的总数)表示所有单词对第j个标签的贡献。然后,我们可以得到上下文词的线性组合,对于每个标签都可以得到一个标签注意力得分
A
(
s
)
A^{(s)}
A(s):
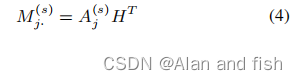
它可以作为输入文档沿第j个标签的新表示。然后整个矩阵
M
(
s
)
∈
R
l
×
2
k
M ^{(s)}∈R^{l×2k}
M(s)∈Rl×2k是自注意机制下的标签特定的文档表示。
2.2.2 标签注意力机制
自我注意机制可以作为基于内容的注意,因为它只考虑了文档的内容。众所周知,标签在文本分类中有特定的语义,这些语义隐藏在标签文本或描述中。为了利用标签的语义信息,将其进行预处理,并在与单词相同的潜在×-维度空间中表示为可训练矩阵
C
∈
R
l
×
k
C∈R^{l×k}
C∈Rl×k。一旦在(1)中embedding了来自BiLSTM的单词且这个单词的embedding也在C中,我们可以明确地确定每对单词和标签之间的语义关系。一个简单的方法就是计算
h
p
→
\overrightarrow{h_p}
hp(或者
h
p
←
\overleftarrow{h_p}
hp)与
C
j
C_j
Cj之间的点乘,如下所示:
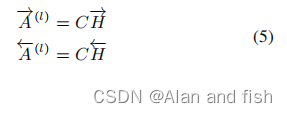
其中
A
(
l
)
→
∈
R
l
∗
n
\overrightarrow{A^{(l)}}∈R^{l*n}
A(l)∈Rl∗n和
A
(
l
)
←
∈
R
l
∗
n
\overleftarrow{A^{(l)}}∈R^{l*n}
A(l)∈Rl∗n表示单词和标签之间的前后边语义关系.类似于之前的自我注意机制,特定于标签的文档表示可以通过线性组合标签的上下文词来构建,如下所示:
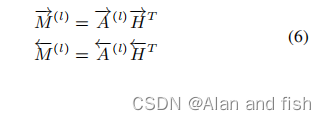
最终,该文档可以通过M(l)=(
M
(
l
→
\overrightarrow{M^{(l}}
M(l,
M
(
l
←
\overleftarrow{M^{(l}}
M(l)∈
R
l
∗
2
k
R^{l*2k}
Rl∗2k沿着所有标签重新表示,这种表示是基于标签文本的,因此它被称为标签注意力机制.
2.3 适应性注意力融合策略
M
(
s
)
M ^{(s)}
M(s)和
M
(
l
)
M ^{(l)}
M(l)都是标签的文档表示,但是他们是不同的.前者主要关注文档的内容,而后者更倾向于文档内容和标签文本之间的语义相关性.为了充分利用这两部分,在本小节中,提出了一种注意力融合策略,即自适应地从它们中提取适当的信息,并构建全面的特定于标签的文档表示。
更具体地说,我们引入了两个权重向量(
α
,
β
∈
R
l
α,β∈R^ l
α,β∈Rl)来确定上述两种机制的重要性,它可以通过输入
M
(
s
)
M ^{(s)}
M(s)和
M
(
l
)
M ^{(l)}
M(l)上的完全连接层得到。
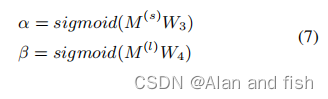
W
3
W_3
W3、
W
4
W_4
W4∈
R
2
k
R ^{2k}
R2k是需要训练的参数。
α
j
α_j
αj和
β
j
β_j
βj分别指出了自我注意和标签注意对沿着第j个标签构建最终文档表示的重要性。因此,我们对它们添加了约束条件:

然后,我们可以根据融合权值得到沿第j个标签的最终文档表示如下。
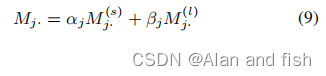
沿所有标签的标签特定文档表示可以描述为矩阵
M
∈
R
l
×
2
k
M∈R^{l×2k}
M∈Rl×2k
2.4 标签预测
一旦有了全面的特定于标签的文档表示,我们可以通过一个具有两个完全连接层的多层感知器来构建多标签文本分类器。从数学上讲,接下来的文档的每个标签的预测概率可以通过sigmoid函数得到:
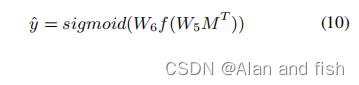
公式里的
W
5
∈
R
b
∗
2
k
W_5∈R^{b*2k}
W5∈Rb∗2k,
W
6
∈
R
b
W_6∈R^b
W6∈Rb分别为全连接层和输出层的可训练参数。f为ReLU非线性激活函数.这里的sigmoid函数被用于将输出值转换成一个概率,在这种情况下,交叉熵损失可以作为损失函数,这已被证明适用于多标签文本分类任务.
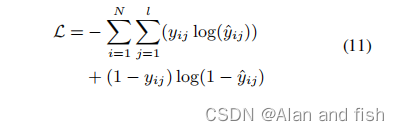
式中,N为训练文档的数量,l为标签的数量,
H
^
j
j
\hat{H}_{jj}
H^jj∈[0,1]为预测概率,
y
i
j
y_{ij}
yij表示第i个文本中的第j个标签的真实情况(即这段文本真实对应的标签).
3. 实验
在本节中,我们将在四个数据集(具有不同数量的标签从54到3956)上评估所提出的模型,通过与广泛使用的指标方面的最新方法进行比较。
3.1 实验设置
3.1.1 实验数据集
- Reuters Corpus Volume I (RCV1):包含超过80K个手动分类的新闻,属于103个类。
- AAPD:收集计算机科学领域arXiv中55840篇论文的摘要和相应的主题。
- EUR-Lex:是一个关于欧盟法律的文件的集合,属于3956个主题。公共版本包含11585个训练实例和3865个测试实例。
- KanShan-Cup:由中国最大的华人社区问题回答平台知乎发布。它包含了关于1900万个1999年的问题.
对于前三个数据集,每个文档只保留了最后500个字,而KanShan-Cup中每个文本最多只有50个字.一旦文档的单词数少于预定的数量,我们通过添加零来扩展它,所有的方法都在给定的训练和测试数据集上进行训练和测试,总结如表1所示。

表1:实验数据集汇总
其中的表头解释如下:
- N:训练集中数据的数量
- M:测试集中数据的数量
- D:文本中的最长文本长度
- L:分类标签数
- L ‾ \overline{L} L:每个文本的平均标签数
- L ~ \widetilde{L} L :每个标签的平均文档数
- W ‾ \overline{W} W:训练集中每个文档的平均单词数
- W ~ \widetilde{W} W :测试集中每个文档的平均单词数
3.1.2 评价指标
我们使用了两种度量方法:
- (P@k):Top K精度
- (nDCG@k):TOP K的归一化累积增益
P@k 和 nDCG@k是根据预测得分向量
y
^
∈
R
l
\hat{y}∈R^l
y^∈Rl和实际标签向量
y
∈
{
0
,
1
}
l
y ∈\{0, 1\}^l
y∈{0,1}l定义的,具体公式如下:
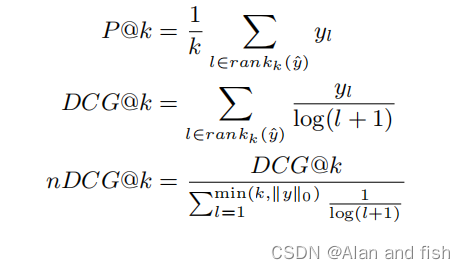
其中
r
a
n
k
k
(
y
)
rank_k(y)
rankk(y)为当前预测结果得分最高的标签的索引。
∣
∣
y
∣
∣
0
||y||_0
∣∣y∣∣0计算是在真实标签向量y中相关标签的数量。
3.1.3 基线模型
所提出的LSAN是一个深度神经网络模型,因此我们选择了最近最先进的基于深度学习的MLTC方法作为基线。
- XML-CNN:采用卷积神经网络(CNN)和动态池化技术提取高级特征,进行多标签文本分类。
- SGM:应用从输入文档到输出标签的序列生成模型来构建多标签文本分类器。
- DXML:试图通过考虑标签共现图中的标签结构来探索标签的相关性。
- AttentionXML:仅基于文档内容构建具有标签感知的文档表示,因此可以作为我们提出的任意设置α = 0的LSAN的一种特殊情况。
- EXAM:是与LSAN最相似的工作,因为它们都利用标签文本来学习单词和标签之间的交互作用。然而,EXAM遭受的情况是,不同的标签有相似的文本。
3.1.4 参数设置
对于KanShan-Cup数据集,我们使用是在官方网站中预先训练好的单词embedding和标签embedding,其中embedding空间大小为256,即k = 256。
神经元间权值对应的参数:
W
1
W_1
W1和
W
2
W_2
W2的为
d
a
d_a
da=200,
W
5
W_5
W5和
W
6
W_6
W6为b = 256.对于其他三个数据集,k = 300,
d
a
d_a
da = 200和b = 300.整个模型都是通过Adam进行优化的,学习率为0.001,所有基线的参数要么取自他们原来的论文,要么由实验确定。
3.2 比较结果与讨论
在本节中,通过与P@K和nDCG@K(K = 1,3,5)方面的5个基线进行比较,在四个基准数据集上评估了建议的LSAN.表2和表3显示了所有测试文件的平均性能.根据P@K和nDCG@K的公式,我们知道P@1 = nDCG@1,因此表3中只列出了nDCG@3和nDCG@5。在每一行中,最佳结果用粗体标记。
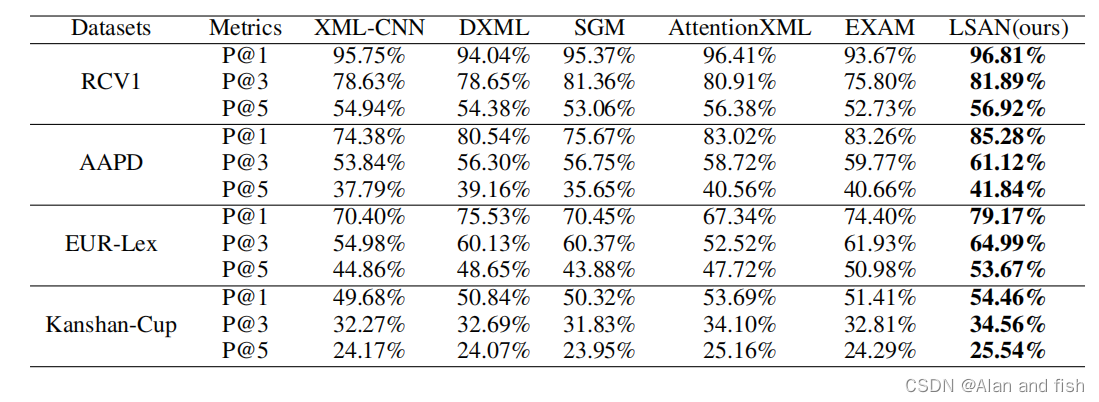 表2:在四个基准数据集上进行LSAN与P@K(K=1,3,5)的比较
表2:在四个基准数据集上进行LSAN与P@K(K=1,3,5)的比较
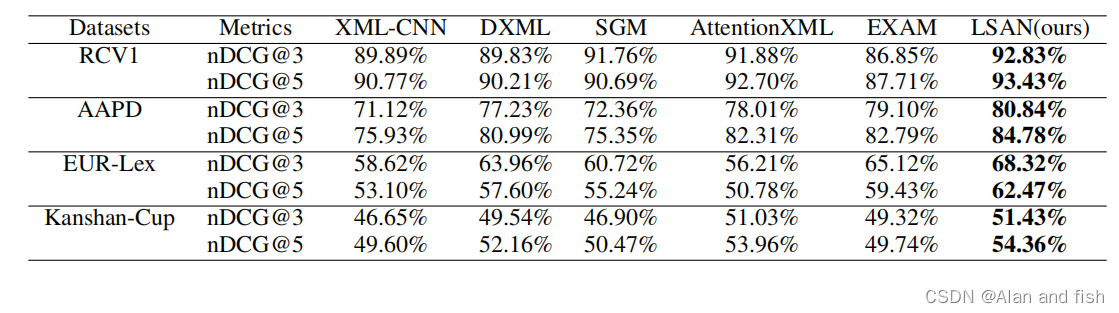
表3:在四个基准数据集上,LSAN与nDCG@K(K=3,5)的5个基线的比较。
从表2和表3中,我们可以对这些结果进行一些观察。首先,XML_CNN比其他四种方法都要差,因为它只考虑文档内容,而忽略了标签相关性,这已经被证明对多标签学习非常重要。
其次,在数据集R_CV1和Kanshan-Cup,AttentionXML优于EXAM,因为这两个数据具有分层的标签结构,在这种情况下,父标签和子标签可能包含类似的文本,这使得基于文本的embedding难以区分,进一步降低了EXAM的性能。通过比较EXAM和我提出的LSAN,然而,注意:AttentionXML在EUR-Lex数据集上的表现较差,主要原因是AttentionXMLl只关注文档内容,一旦在一些标签中只有很少的文档,这将使它没有得到足够的训练.幸运的是,EXAM和LSAN受益于标签文本。最后一个,正如预期的那样,即LSAN在所有实验数据集上始终优于所有基线.这一结果进一步证实了所提出的自适应注意融合策略对学习多标签文本分类的标签特定文档表示有重要意义。
3.3 稀疏数据比较
为了验证LSAN在低频标签上的性能,我们将EURLex中的标签根据其发生的频率分为三组。图2显示了EUR-Lex上标签频率的分布,F是标签的频率,其中,
- 组1:近55%的标签出现在1-5次之间,形成第一个标签组(组1)
- 组2:出现5-37次的标签被分配到第2组,占整个标签集的35%.
- 组3:其余10%的频繁标签构成最后一组(第3组)。
显然,由于缺乏训练文件,第一组比其他两组要困难得多。
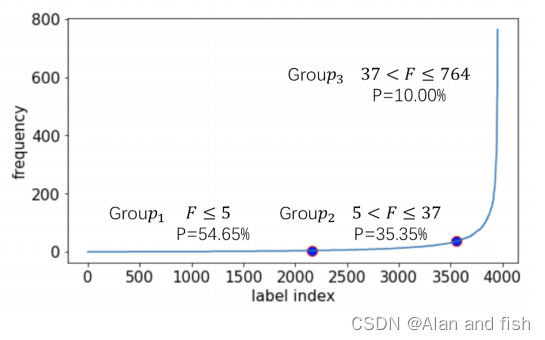
图2:EUR-Lex的标签分布
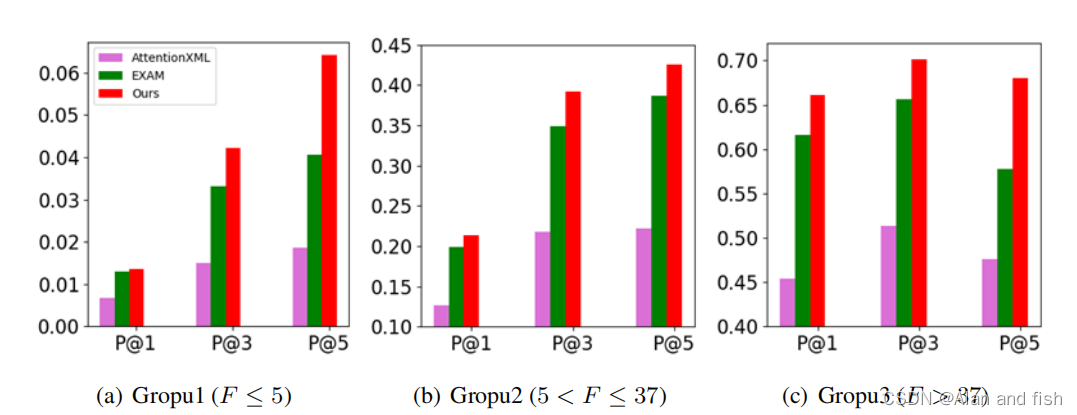
图3:三组在EUR-Lex的精度@k
图3为AttentionXML,EXAM 和 LSAN得到的P@1、P@3和P@5的预测结果,从组1到组3,三种方法越来越好,这是合理的,因为从组1到组3的每个标签中都包含了越来越多的文档。LSAN显著提高了第1组的预测性能。特别是 LSAN在第1组得到的三个指标
- 超过AttentionXML 83.82%、182.55%、244.62%的平均收益.
- 超过 EXAM 3.85%,27.19%,58.27%
这一结果表明了该模型在尾标签多标签文本数据上的优越性
3.4 消融实验
所提出的LSAN可以作为一种联合注意策略,包括三部分。
- A:基于文档内容的self_attention
- L:基于标签文本的 label-attention
- W:通过用适当的权值对A和L进行自适应积分来实现融合注意机制
在这部分我通过消融试验来演示每个成分的效果.
图4列出了四个基于P@1、P@3和P@5的数据集的预测结果。(即,S+L比S和L得到更好的结果)。
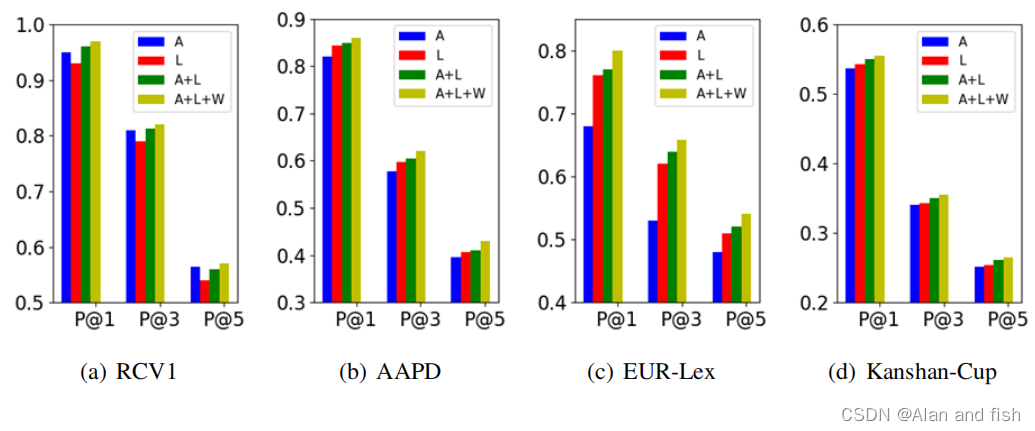
图4:消融试验的结果。“A”表示self-attention,“L”表示label-attenton,“W”表示具有适应性权重的融合注意力机制。
图4列出了对P@1、P@3和P@5这四个数据集的预测结果。(即,S+L比S和L得到更好的结果).S更倾向于在构建特定于标签的文档表示时找到有用的内容,但它忽略了标签信息。L利用标签文本来明确地确定文档和标签之间的语义关系,然而,标签文本并不容易区分标签之间的区别(例如,管理 VS 管理电影)。因此,与这两种注意力的结合是非常合理的。此外,自适应地从这两种注意力中提取适当的信息量,有利于最终的多标签文本分类。
为了进一步验证注意力适应性融合的有效性,图5列出了两个代表性数据集上的自我注意和标签注意的权重分布,一个用于稀疏数据(EUR-Lex),另一个用于密集数据(AAPD),正如预期的那样,对于稀疏的数据,标签注意比自我注意更有用.相反对于密集数据,每个标签都有足够的文档,因此,自我注意可以有效地获得特定于标签的文档表示。另一方面,标签文本有助于提取标签与文档之间的语义关系。在其他两个数据集上的结果也有类似的趋势,但由于页面的限制而被省略了。
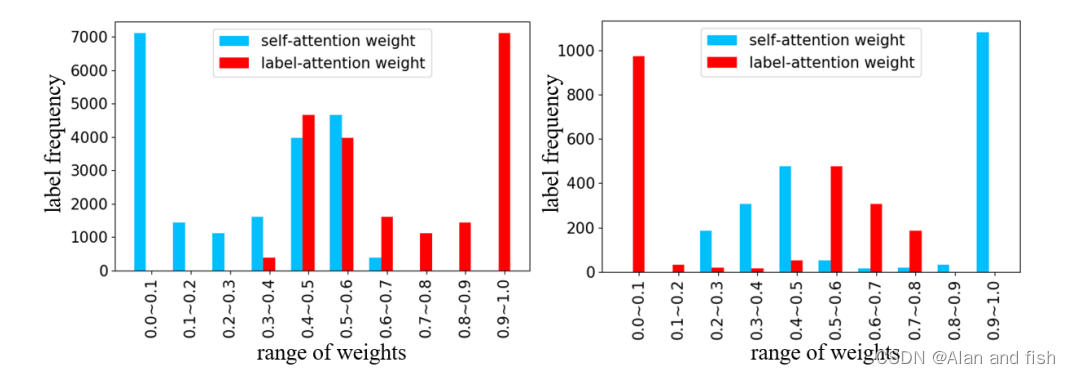
图5:EUR-Lex(左子图)和AAPD(右子图)上的两个组件的重量分布。横轴是指重量从0到1且间隙为0.1的重量范围。纵轴是在当前标签组中出现特定范围的频率
为了研究标签注意的影响,我们使用热图将原始文档上的注意权重可视化,如图6所示。

图6:在一个AAPD文档中具有最大标签注意权重
(
A
(
l
)
)
(A ^{(l)})
(A(l))的单词,属于两类:计算机视觉和神经和进化计算
其中,示例AAPD文档属于计算机视觉、神经计算和进化计算两类.从注意力的权重中,我们可以看到每个类别都有自己最相关的词,这证实了所提出的标签特定注意网络能够提取标签感知内容,并进一步构建标签特定的文档表示。
4.相关工作
在多标签文本分类领域(MLTC)中,很多工作只是针对两个方面,第一个方面就是文档表示学习,另外一个就是标签相关性检测。
对于文档表示,随着最近CNN的成功,许多基于CNN的工作,它可以从连续的上下文窗口中捕获局部相关性。虽然这些方法获得了很好的结果,但它们受到窗口大小的限制,因此不能确定文本的长距离依赖性。与此同时,他们平等地对待所有的单词,不管这个单词有多么嘈杂.随后,引入了RNN和注意机制,得到了良好的效果.为了隐式学习每个标签的文档表示,采用自我注意机制进行多标签分类.
为了确定多标签数据之间的标签相关性,在文献中,研究人员提出了多种方法.Kurata等人(2016)采用了一种初始化方法来利用标签共现信息.SLEEC(Bhatia et al.,2015)将数据集划分为多个聚类,并在每个聚类中通过捕获非线性标签相关性来检测嵌入向量。DXML(Zhang et al.,2018)建立了一个显式的标签共现图来探索标签在低维潜在空间中的嵌入。Yang等人(2018)使用序列到序列(Seq2Seq)模型来考虑标签之间的相关性。最近,标签的文本信息被用来指导MLTC。EXAM(Du et al.,2018)引入了交互机制,将词级匹配信号纳入文本分类任务中。GILE(Pappas和Henderson,2019)提出了一种用于神经文本分类的联合输入标签嵌入模型。不幸的是,当标签文本之间没有很大的区别时,它们就不能很好地工作.
5.阅读心得
阅读这篇文章除了收获了一种新的多标签文本分类的方法,还收获了写论文的方法:
- 感悟1:作者的论文写的非常清晰,他的这三种方法的介绍基本都可以在他的代码中找到对应的源码
- 感悟2: 实验分析非常完整,作者借助了稀疏数据比较和消融实验分析佐证了自己的工作有用,并且还分析了前人工作的不足
- 感悟3:如果想发表一篇优秀的论文非常不容易,不仅需要有很强的代码能力,好需要很好的论文写作能力,最主要的就是能够清楚的表达自己的意思,很多论文华而不实,通过华丽的辞藻包装自己的工作,让人看不懂.
















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









