







0、简介
-
论文名字:Label-aware Document Representation via Hybrid Attention for Extreme Multi-Label Text Classification
-
下载地址:https://arxiv.org/abs/1905.10070
-
会议:无
1、motivation
本文的任务是文本的多标签分类。之前关于文本多标签分类的工作大多集中于学习文本和label 的content,忽略了label 之间的结构信息。本文通过学习label 之间的结构信息,从而帮助模型更好的实现多标签分类任务。
2、model

本文的模型结构图如上所示。
(1)label embedding和word embedding
本文使用Bi-LSTM对文本的文字进行编码,Bi-LSTM的隐藏层输出作为word embedding。
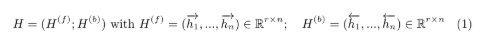
本文对labe经行构图,每个label代表一个节点,当两个label至少在同一个数据中出现,这两个label代表的节点之间有边的连接。label的图构好后使用node2vec学习节点的表示向量 L L L。
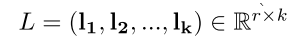
(2)self-attention学习文本内容和label的关系表示
每一条文本和其对应的label应该更有相关性,因此本文使用自注意力机制学习文本对每一个label的表示。使用下面公式计算attention值
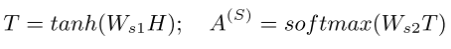
计算得到的attention值 A S A^{S} AS的维度是n*k,k是label的个数, A S A^{S} AS得到的是每个label和文本的attention值。 A S A^{S} AS和word embedding H H H相乘就得到了文本内容和每个label之间关系表示 C S C^{S} CS。
(3)Interaction-attention学习文本内容和label的关系表示
self-attention中,计算attention值的时候,key 和query都是文本自身。在Interaction-attention中query是前面用图学习到的label embedding。
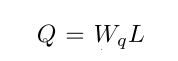
label embedding L乘以参数矩阵 W q W_{q} Wq后得到了query Q Q Q。key是word embedding H,使用下面公式可以得到attention值M
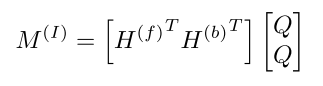
对 M M M进行归一化后得到归一化的attention值 A I A^{I} AI,下面公式为归一化公式。
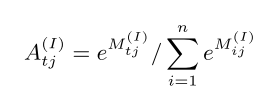
A I A^{I} AI和word embedding H H H相乘就得到了文本内容和每个label之间关系表示 C I C^{I} CI。
(4) Attention 融合
上面步骤我们计算得到两个文本内容和label之间关系表示 C S C^{S} CS和 C I C^{I} CI。本文将两个表示进行融合,融合的方法如下:

首先使用sigmoid函数将 C S C^{S} CS和 C I C^{I} CI缩小到(0,1)的范围内,分别为 α \alpha α和 β \beta β。然后将 α \alpha α和 β \beta β normalize,使其和为1,分别得到 α j \alpha_{j} αj和 β j \beta_{j} βj。通过 α j \alpha_{j} αj和 β j \beta_{j} βj,将 C S C^{S} CS和 C I C^{I} CI融合为 C C C。
(5)预测层
得到融合后的表示 C j C^{j} Cj后,将 C j C^{j} Cj连接全连接层和sigmoid,得到了输出表示,公式如下
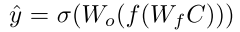
然后构造损失函数:
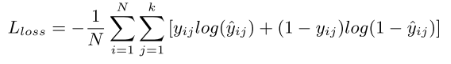
这样就可以通过最小化损失函数来优化模型。
3、我的想法
这篇论文将graph引入多标签分类任务中,使用graph学习label的embedding。但是这篇论文一直挂在arxiv上没有发表出来,我认为可能使创新性还不够,因为之前有一篇ACL2019的论文,和这篇论文思想基本差不多,都是用self-attention提取文本内容和label之间的关系,只是ACL2019那篇论文没有使用graph学习label的embedding,而是将label的文本直接编码成label embedding。















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









