







 本文提出了一种名为LP-MTC的多标签文本分类模型,它利用提示学习将标签信息融入到预先训练好的语言模型中,通过模板和自我注意机制捕获标签之间的相关性。模型在多个数据集上进行了实验,显示了与传统方法相比的性能优势,特别是在捕获标签关联和提高微F1分数方面。此外,研究还探讨了不同提示策略、损失函数和标签空间大小对模型性能的影响。
本文提出了一种名为LP-MTC的多标签文本分类模型,它利用提示学习将标签信息融入到预先训练好的语言模型中,通过模板和自我注意机制捕获标签之间的相关性。模型在多个数据集上进行了实验,显示了与传统方法相比的性能优势,特别是在捕获标签关联和提高微F1分数方面。此外,研究还探讨了不同提示策略、损失函数和标签空间大小对模型性能的影响。
论文相关
论文标题:Label prompt for multi-label text classification(基于提示学习的多标签文本分类)
发表时间:2023
领域:多标签文本分类
发表期刊:Applied Intelligence(SCI二区)
相关代码:无
数据集:无
摘要
多标签文本分类由于其实际应用而受到学者的广泛关注。多标签文本分类的关键挑战之一是如何提取和利用标签之间的相关性。然而,在一个复杂和未知的标签空间中,直接建模标签之间的相关性是相当具有挑战性的。在本文中,我们提出了一种标签提示多标签文本分类模型(LP-MTC),该模型受到预先训练语言模型的启发。具体来说,我们设计了一套多标签文本分类的模板,将标签集成到预先训练过的语言模型的输入中,并通过屏蔽语言模型(MLM)进行联合优化。这样,就可以在自我注意的帮助下捕获标签之间的相关性以及标签与文本之间的语义信息,从而有效地提高了模型的性能。在多个数据集上进行的大量经验实验证明了该方法的有效性。与BERT相比,LP-MTC在4个公共数据集上的平均性能比micro-F1提高了3.4%。
1.引言
文本分类是自然语言处理(NLP)中的一项基本和重要的任务,已广泛应用于情感分析、文章检索等领域。在传统的文本分类方法中,每个样本都与一个唯一的标签相称。然而,随着数据量的增加,大量的样本被分配到多个标签上,这导致了传统的单标签文本分类方法的失败。例如,在一些跨学科的研究中,一些文章可能同时涉及化学和计算机。因此,我们很自然地提出了多标签文本分类(MTC)方法。
MTC的目标是在整个标签空间中为某个文档确定适当的类别,并给该文档一个不确定数量的标签。近年来,多标签文本分类被广泛应用于情绪分析、主题分类、信息检索、和标签推荐。在实际应用中,由于文档的冗长和复杂,语义信息可能被隐藏在嘈杂或冗余的内容中。此外,标记之间可能存在一些语言相关性,并且不同的标记可能共享文档的一个子集。为了解决这些问题,对MTC的研究视角可以分为以下三类:如何从原始文档中充分捕获语义模式,如何从每个文档中提取与相应标签相关的区别信息,以及如何准确地挖掘标签之间的相关性。
解决MTC最直接的方法之一是将多标签文本分类任务转换为几个二值分类任务,但这往往忽略了多个标签之间的关系。同样,一些深度学习方法,如CNN 和注意机制,可以有效地对文档进行建模,但仍然忽略了标签之间的关系。如图1所示,在由皮尔逊相关系数计算出的Arxiv学术论文数据集(AAPD)中,不同的标签对之间存在特定的相关性。对于标签0和标签1,相关性为1,这意味着这两个标签在所有实例中都会一起出现。因此,对于一些标签信息较少或长尾分布严重的数据集,标签之间的关联可以提供更重要的信息。
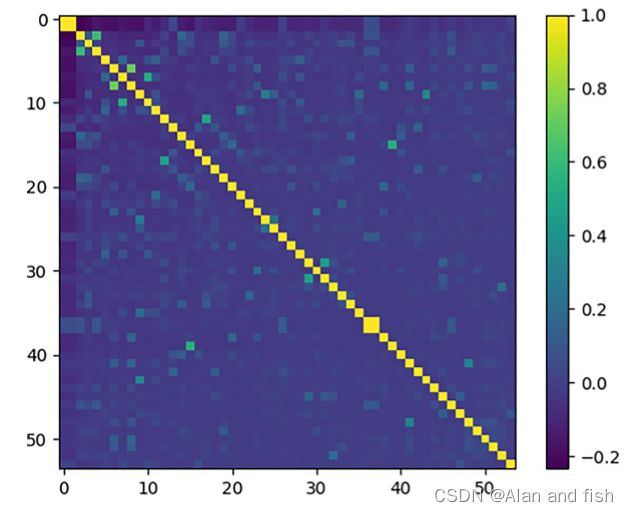
图1 AAPD列组中所有标签对之间的斯皮尔曼相关系数。颜色越浅,标签对就越相关性
近年来,一些方法利用标签结构和内容来捕获标签之间的相关性。一些研究将MTC转化为标签生成模型,以检索多标签的潜在空间。一些方法通过学习标签的表示来得到一个更一般化的分类模型。也有一些方法通过显式地建模列车集中标签之间的关联来预测测试集的标签。然而,当标签文本之间没有太大的差异或缺乏标签文本时,这些模型可能会在分类上失败。此外,在一个未知和复杂的标签空间中建模标签的关联可能是非常具有挑战性的。
大规模的预训练语言模型的出现,如BERT(来自变形金刚的双向编码器表示)和GPT-3 ,使得自然语言处理领域的知识转移更加容易。最近的一些研究表明,为预先训练过的语言模型编写提示可以更好地释放模型的优势,并实现进一步的改进。在提示学习中,任务被形式化为等效的封闭式任务,语言模型用于处理相应的封闭式任务,而不是原始任务。
受基于大规模预训练语言模型的提示学习方法的启发,我们提出了一种标签提示多标签文本分类模型(LP-MTC),通过使用语言模型学习的提示模板中的语义信息来学习标签与文本之间的关系。具体来说,我们将不同的标签映射到不同的标记上,并构建一组标记前缀模板,用于提示学习。在这里,标签可以是不包含文本信息的特殊标记,如[标签1]、[标签2],而不是文本标签,如体育、科学等。通过将前缀模板与语言模型的输入相结合,可以很自然地通过自我注意来捕获模板中包含的标签关联。此外,与现有的设计良好的基于任务的模板相比,我们的方法更为通用,不需要为不同的数据集进行定制。在训练过程中,我们将标记模板与要分类的句子拼接,并将它们输入BERT。在预测时,我们掩盖了所有的标签标记并预测它们。此外,为了更好地利用BERT的预测能力,我们还构建了一个多任务框架,即原始输入的随机掩码标记,并使用掩码语言模型(MLM)来预测掩码标记,以帮助优化多标签文本分类学习任务。我们的贡献如下:
- 提出了一种标签提示多标签文本分类模型(LP-MTC),该模型将多标签文本分类转换为提示学习任务。特别是,我们为不同的数据集设计了一个通用的提示模板,并在预先训练好的语言模型的帮助下捕获了标签和文本之间的潜在语义关系。
- 我们使用MLM为联合训练构建了额外的语言模型学习任务,进一步提高了LP-MTC的性能。
- 我们对不同的多标签文本分类任务进行了广泛的实验,证明了我们的方法在模型性能、标签相关性和时间能力方面的优越性。
2.相关工作
在本节中,我们将介绍一些与我们的研究相关的工作,包括多标签文本分类和提示学习。
2.1 多标签文本分类
多标签文本分类是自然语言处理中的一项基本任务。现有的方法倾向于通过将多标签文本分类任务转换为多个二元分类任务来解决它。有些方法利用了标签之间的配对关联或互作关联。两两比较(RPC)利用两两分类的自然扩展,产生了一种二元偏好关系,将多标签学习任务转化为标签排序任务。
然而,假设一个标签可以与多个标签相关,并利用标签的高阶依赖关系更有效。分类器链(CC)将MTC的任务转换为一组二元分类任务链。k-标签集(RAkEL)构建小的标签随机子集,并将MTC转换为随机子集的单标签分类任务。近年来,随着深度学习的发展,一些研究采用序列学习模型来解决MTC,如序列生成模型(SGM),它们通过RNN解码器生成一个潜在的标签序列。然而序列模型需要在潜在的空间中寻找最优解,当标签太多时,这就太耗时了。
有些方法对标签的联合概率分布进行建模,而不是对特定标签的关联,如贝叶斯网络和无向图模型。Wang等人,通过不良学习框架,加强了多标签的联合分布与预测的多标签之间的相似性。由于图神经网络(GNN)在非欧几里得空间数据建模中的有效性,有些方法使用GNN来捕获标签之间的相关性。标签特定注意网络(LSAN)提出了一种同时考虑文档内容和标签文本的标签注意网络模型,并使用自我注意机制来衡量每个单词对每个标签的贡献。磁铁使用一个特征矩阵和一个相关矩阵来捕获和探索标签之间的关键依赖关系。与上述研究不同,我们的方法采用预先训练好的语言模型,通过即时学习来捕捉标签之间的相关性,从而提高多标签分类的效果。通过自我注意,我们不是明确地表示标签之间的关系,而是直接将带有标签模板的标记输入BERT,让模型自动学习相关性
2.2 提示学习
近年来,提示学习被用来填补预先训练好的语言模型与下游任务之间的客观差异,并充分利用语言模型的可转移性。通过利用语言提示作为上下文,提示学习将下游任务转换为阻塞式任务。
少样本分类学习分类器只给出每个类的少数标记的例子。一些最早的研究旨在通过在很少样本的情况下迅速学习来解放语言模型的能力。基于层次的优化相结合的完草问题,并展示了提示学习与BERT、GPT-3和其他语言模型相结合的能力。渐渐地,一些手工提示被广泛探索,例如,在神经语言推理和情绪分类。PTE利用完形填空法成功地解决了小样本中的文本分类和自然语言推理问题。Chen和Zhang 提出了一种基于问题的方法,将与标签相关的问题与每个候选句子联系起来,以帮助语言模型更好地理解少样本学习中的文本分类任务。
为了避免劳动密集型的提示设计,自动提示搜索已被广泛探索。自动提示自动创建一组不同任务的提示,并显示MLM执行情绪分析和自然语言推理的内在能力。有些方法还使用了一种自动的方式来将提示符中的单词映射到适当的类别。LM-BFF采用Seq-to-Seq模型来生成提示学习的候选对象。也有研究直接使用一系列可学习的顺序嵌入作为提示,而不是离散的语言短语。但是大多数自动生成的提示的性能不如手动选择的提示。
与以往的其他研究不同,我们的方法旨在探索提示学习在多标签文本分类中的应用,而不是专注于少样本学习。此外,我们的方法不需要为每个数据集构建由自然语言短语或单词组成的不同模板。相反,我们使用一系列专门定义的token来表示标签提示符。
3.初步准备工作
首先,我们出发并描述了MTC任务和提示学习。对于一个给定的文本x = {w1,w2,…,wm}和它的真实标签y = {y1,y2,…,yL},L表示标签的数量,那么MTC任务的目标是学习一个映射函数 χ : x → y : { 0 , 1 } L χ: x→y:\lbrace 0,1\rbrace^L χ:x→y:{
0,1}L。
在提示学习中,通常需要以下三个步骤来构建一个提示学习的管道:
- 为不同的任务构建提示式模板。以电影情感二分句为例,“这部电影太感人了!”,提示学习或称为提示调优,通常生成一个新的句子,由前缀/后缀模板τ输入:
“这部电影太感人了!”我[Mask]它!”[Mask]可以是“爱”或“恨”,分别表示积极或消极的情绪。带有前缀模板的新输入可以表示为:

其中||表示连接。 - 通过语言模型搜索模板的最优答案。在训练过程中,提示学习通常与语言模型相结合来预测掩码标记信息。形式上,给定一个带有词汇表V的语言模型M和带有掩码m的新输入x,提示学习的目标是预测掩码token w的概率 p M m ( w ∣ x ′ ) p^m_M(w|x') pMm(w∣x′),其中w∈V和 p M m ( w ∣ x ′ ) ∈ R ∣ V ∣ p^m_M(w|x')∈R^{|V |} pMm(w∣x′)∈R∣V∣表示token的概率分布向量。要预测的标记通常反映了句子的分类。
- 将搜索到的答案映射到标签空间。一般来说,预测的标记与实际的类别不同,因此需要通过
映射或称为表达器的方法将特定的标记分配给相应的类别。例如,在图2中,爱被映射为一个积极的类别,恨被映射为一个消极的类别。通过这种方式,即时学习可以将二元情绪分类任务转换为封闭式的任务。
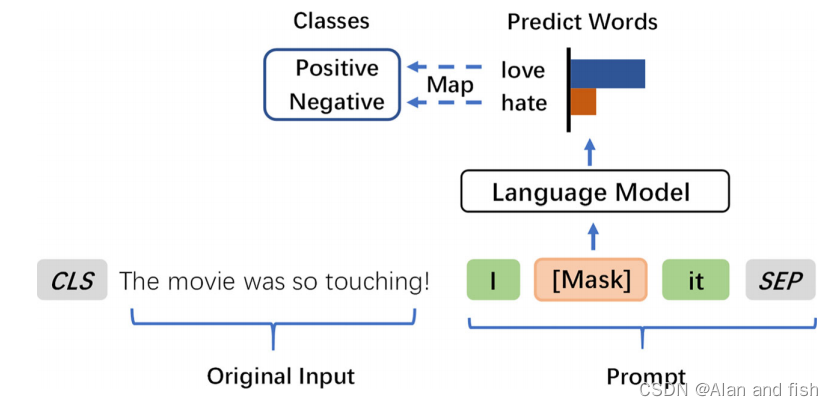
图2:构建输入的提示示例
4.方法
在本节中,我们详细描述了所提出的模型,如图3所示。首先,我们需要设计一套提示模板,可以用于多个标签任务,以便在输入中显示标签信息。在此之后,我们需要使用语言模型在模板中学习[Mask]标记。然后,我们还通过随机掩蔽原始输入的标记来构建一个多任务框架,并使用MLM来预测掩蔽标记。
4.1提示模板
对于提示学习,虽然一些研究已经证明了模板方法的优势,但不清楚相同的模板是否适用于每个模型,也不清楚哪样的模板更适合模型。对于MTC,由于不同的文档包含不同数量的真标签,并且不同数据集的标签空间大小不一致,所以很难为每个标签构建特定的模板。为此,我们为整个标签空间构建了一个模板系统。首先,每个位置上的不同标签应该有三种不同的状态:1、0或掩码。为了方便起见,让我们把它们写成Y,N和M。我们强调不同标签的顺序,这对标签的预测非常重要。此外,我们还引入了一个基于位置的提示,允许BERT清楚地识别当前标签的位置。具体来说,我们对每个标签token l∈{Y,N,M}采用以下生成方法Γ:
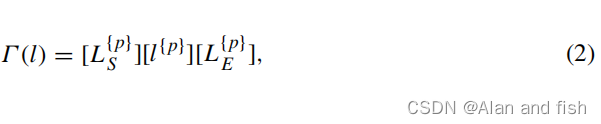
其中[.]表示BERT的特殊标记, [ L S ] [L_S] [L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









