







引言 thinkphp* 大道至简
负载均衡
分布式服务
一、读写分离
为什么要读写分离
理论上来说读写请求不要超过2000/s,如果加了缓存之后,到数据库请求还是超过2000以上考虑读写分离
使得读请求可以在不同机器并发,用了读写分离之后可以通过动态扩展读服务器增加读效率,这与redis中的主从架构读写分离、copyOnWrite机制的并发容器、以及数据库MVCC机制有点相识,都是通过读请求的数据备份增加读写并发效率。
适用于业务场景中,读请求大于写请求的情况,读写分离使得系统能够更多的容纳读请求并发
1、读写分离的实现方式
一般来说是基于mysql自带的主从复制功能。mysql主从复制的流程图如下:

总结mysql的主从复制过程大体是主库有一个进程专门是将将记录的Binlog日志发送到从库,从库有一个io线程(mysql5.6.x之后IO线程可以多线程写入relay日志)将收到的数据写入relay日志当中,另外还有一个SQL进程专门读取relay日志,根据relay日志重做命令(mysql5.7版本之后,从可以并行读取relay log重放命令(按库并行,每个库一个线程))。
2、主从同步的三种模式
2-1、异步模式(mysql async-mode)
异步模式如下图所示,这种模式下,主节点不会主动push bin log到从节点,这样有可能导致failover的情况下,也许从节点没有即时地将最新的bin log同步到本地。
2-2、半同步模式(mysql semi-sync)
这种模式下主节点只需要接收到其中一台从节点的返回信息,就会commit;否则需要等待直到超时时间然后切换成异步模式再提交;这样做的目的可以使主从数据库的数据延迟缩小,可以提高数据安全性,确保了事务提交后,binlog至少传输到了一个从节点上,不能保证从节点将此事务更新到db中。性能上会有一定的降低,响应时间会变长
2-3、同步模式(mysql semi-sync)
全同步模式是指主节点和从节点全部执行了commit并确认才会向客户端返回成功。
3、代码演示,本次演示使用thinkphp6
- 配置数据库文件database (文件目录tp6\config\database.php)
参考文章 宝塔 tp6 mysql分布式,主从同步、读写分离、保姆式教程+代码
<?php
return [
// 默认使用的数据库连接配置
'default' => env('database.driver', 'mysql'),
// 自定义时间查询规则
'time_query_rule' => [],
// 自动写入时间戳字段
// true为自动识别类型 false关闭
// 字符串则明确指定时间字段类型 支持 int timestamp datetime date
'auto_timestamp' => true,
// 时间字段取出后的默认时间格式
'datetime_format' => 'Y-m-d H:i:s',
// 时间字段配置 配置格式:create_time,update_time
'datetime_field' => '',
// 数据库连接配置信息
'connections' => [
'mysql' => [
// 数据库类型
'type' => env('database.type', 'mysql'),
// 服务器地址
'hostname' => '127.0.0.1,127.0.0.1',
// 数据库名
'database' => 'tp8,read',
// 用户名
'username' => 'root,root',
// 密码
'password' => 'root,root',
// 端口
'hostport' => env('database.hostport', '3306'),
// 数据库连接参数
'params' => [],
// 数据库编码默认采用utf8
'charset' => env('database.charset', 'utf8'),
// 数据库表前缀
'prefix' => env('database.prefix', ''),
// 数据库部署方式:0 集中式(单一服务器),1 分布式(主从服务器)
'deploy' => 1,
// 数据库读写是否分离 主从式有效
'rw_separate' => true,
// 读写分离后 主服务器数量
'master_num' => 1,
// 开启自动主库读取
'read_master' => true,
// 指定从服务器序号
'slave_no' => '',
// 是否严格检查字段是否存在
'fields_strict' => true,
// 是否需要断线重连
'break_reconnect' => true,
// 监听SQL
'trigger_sql' => env('app_debug', true),
// 开启字段缓存
'fields_cache' => false,
],
// 更多的数据库配置信息
],
];
- ss
2-4 总结
在代码中插入之后,又查询这样的操作是不可靠,可能导致插入之后,查出来的时候还没有同步到从库,所以查出来为null。如何应对这种情况了?其实并不能从根本上解决这种情况的方案。只能一定程度通过降低主从延迟来尽量避免。
降低主从延迟的方法有:
拆主库,降低主库并发,降低主库并发,此时主从延迟可以忽略不计,但并不能保证一定不会出现上述情况。
打开并行复制-但这个效果一般不大,因为写入数据可能只针对某个库并发高,而mysql的并行粒度并不小,是以库为粒度的。
但这并不能根本性解决这个问题,其实面对这种情况最好的处理方式是:
重写代码,插入之后不要更新
如果确实是存在先插入,立马就能查询到,然后立马执行一些操作,那么可以对这个查询设置直连主库(通过中间件可以办到)
二、分库分表
分表
分表分库一般分垂直和水平,垂直是指感觉业务来进行库的拆分,比如专门的用户库或者订单库这样子,但垂直还是无法解决单表数据量过大导致的性能会差的问题(这里可能会和上面矛盾,网上多数指的是 2000W 就会影响,但好像没有多少人谈过他们的表结构情况)。水平分指的是某一个表,里面的数据量非常大,我们按照一定的规则来进行一个拆分分流,比如把用户的数据由一直存放在用户表,变为可能这条数据是在用户1号表或者2号表这样子。规则可能是 范围(range)或者哈希(hash),也不知道我喜欢的取模算不算哈希。分了其实会带来一些问题的复杂性,比如分库那如何确保多库事务性的一致性、分布式锁等等很多,然后还有之前我们的 join 查询,现在可能就无法使用呢。
1、为什么要分表
当不使用分库分表的情况下,系统的性能瓶颈主要体现在:
当面临高并发场景的时候,为了避免Mysql崩溃(MySql性能一般的服务器建议2000/s读写并发以下),只能使用消息队列来削峰。
受制于单机限制。数据库磁盘容量吃紧。
数据库单表数据量太大,sql越跑越慢
而分库分表正是为了解决这些问题,提高数据库读写并发量,磁盘容量大大提高,单表数据量降低,提高查询效率。
2、垂直拆分和水平拆分
以表的维度来说:
垂直拆分 指根据表的字段进行拆分,其实很常见,有时候在数据库设计的时候就完成了,属于数据库设计范式,如订单表、订单支付表、商品表。
水平拆分 表结构一样,数据进行拆分。如原本的t_order表变为t_order_0,t_order_1,t_order_3
以库的维度来说:
垂直拆分 指把原本的大库,按业务不同拆到不同的库(微服务一般都是这么设计的,即专库专用)
水平拆分 一个服务对应多个库,每个库有相同的业务表,如库1有t_order表,库2也有t_order表。业务系统通过数据库中间件或中间层操作t_order表,分库操作对于业务代码透明。
所以,我们平常说的分库分表,一般都是指的水平拆分
分区操作(分区就是一张表)
分区和分表相似,都是按照规则分解表。不同在于分表将大表分解为若干个独立的实体表,而分区是将数据分段划分在多个位置存放,可以是同一块磁盘也可以在不同的机器。分区后,表面上还是一张表,但数据散列到多个位置了。app读写的时候操作的还是表名字,db自动去组织分区的数据。
- 执行操作分区(分区就是一张表)
注意
Mysql 8.0版本开始,不允许创建 MyISAM 分区表
The mix of handlers in the partitions is not allowed in this version of MySQL
示例创建一个可以分区的试题表。这用的是innodb 用哈希值question_id 进行分表
CREATE TABLE `sslq_questions` (
`question_id` INT NOT NULL AUTO_INCREMENT,
`category_id` INT NOT NULL,
`question` VARCHAR(255) NOT NULL,
`created_at` DATETIME NOT NULL,
PRIMARY KEY (`question_id`, `category_id`)
) ENGINE=INNODB DEFAULT CHARSET=latin1
PARTITION BY HASH (question_id) PARTITIONS 10;
- sql 验证表分区效果
警告
验证mysql 分区,测试有一个questions表,它被分区了,且分区键是p0到p9
只对表进行了分区,并没有分表,只有一张表,不是我想要的效果。*
SELECT
TABLE_SCHEMA,
TABLE_NAME,
PARTITION_NAME,
PARTITION_METHOD
FROM
information_schema.PARTITIONS
WHERE
TABLE_SCHEMA = 'tp8';
验证结果如下图所示:
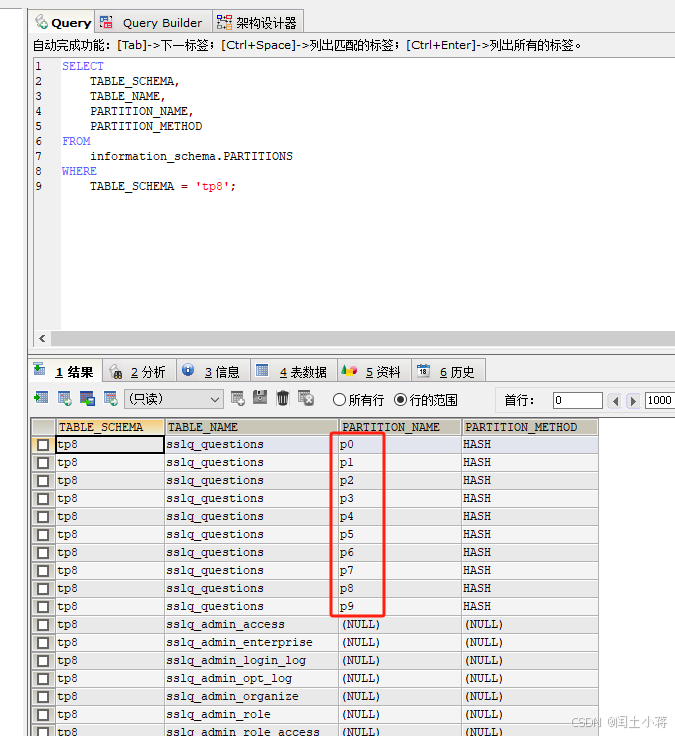
3. 执行程序验证数据的插入以及查询
thinkphp6.12 插入以及查询语句
$data['question_id'] = $uuid; //分区验证字段采用哈希值来计算,或者采用redis 配置动态uuid 来实现
Db::name('questions')
->partition(['p0','p1','p2','p3','p4','p5','p6','p7','p8','p9'])
->insert($data);
结果插入成功、查询数据
说明一下,partition 函数用的话根据p0~p9 顺序读取参数,返回的数据id 是根据p 【p0,p1、、、、】里面来返回的,导致id是错序号的,类似21、31、41、51、18、28、38、5、15、不用的话也可以就是一个select 语句而已,本来就直插入的是一张表,没有实现我要的预期是直接数据分表,看云手册里面,球都没见过,估计是没有买收费的文档吧。
return Db::name('questions')
->where([])
->partition(['p0','p1','p2','p3','p4','p5','p6','p7','p8','p9'])
->select();
分表操作(分表就是同样字段的多张表)
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,我们可以称为子表,每个表都对应三个文件,MYD数据文件,.MYI索引文件,.frm表结构文件。这些子表可以分布在同一块磁盘上,也可以在不同的机器上。app读写的时候根据事先定义好的规则得到对应的子表名,然后去操作它。
小结 不同的场景可以用不同的分库分表规则。技术无罪
分表分库的策略
- hash分法,按一个键进行hash取模,然后分发到某张表或库。优点是可以平摊每张表的压力,缺点是扩容时会存在数据迁移问题。
- range分法,按范围或时间分发,比如按某个键的值区间、或创建时间进行分发,优点是可以很方便的进行扩容,缺点是会造成数据热点问题。从分表上说还好,如果是分库,将导致某一个库节点压力过大,节点间负载不均。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











