






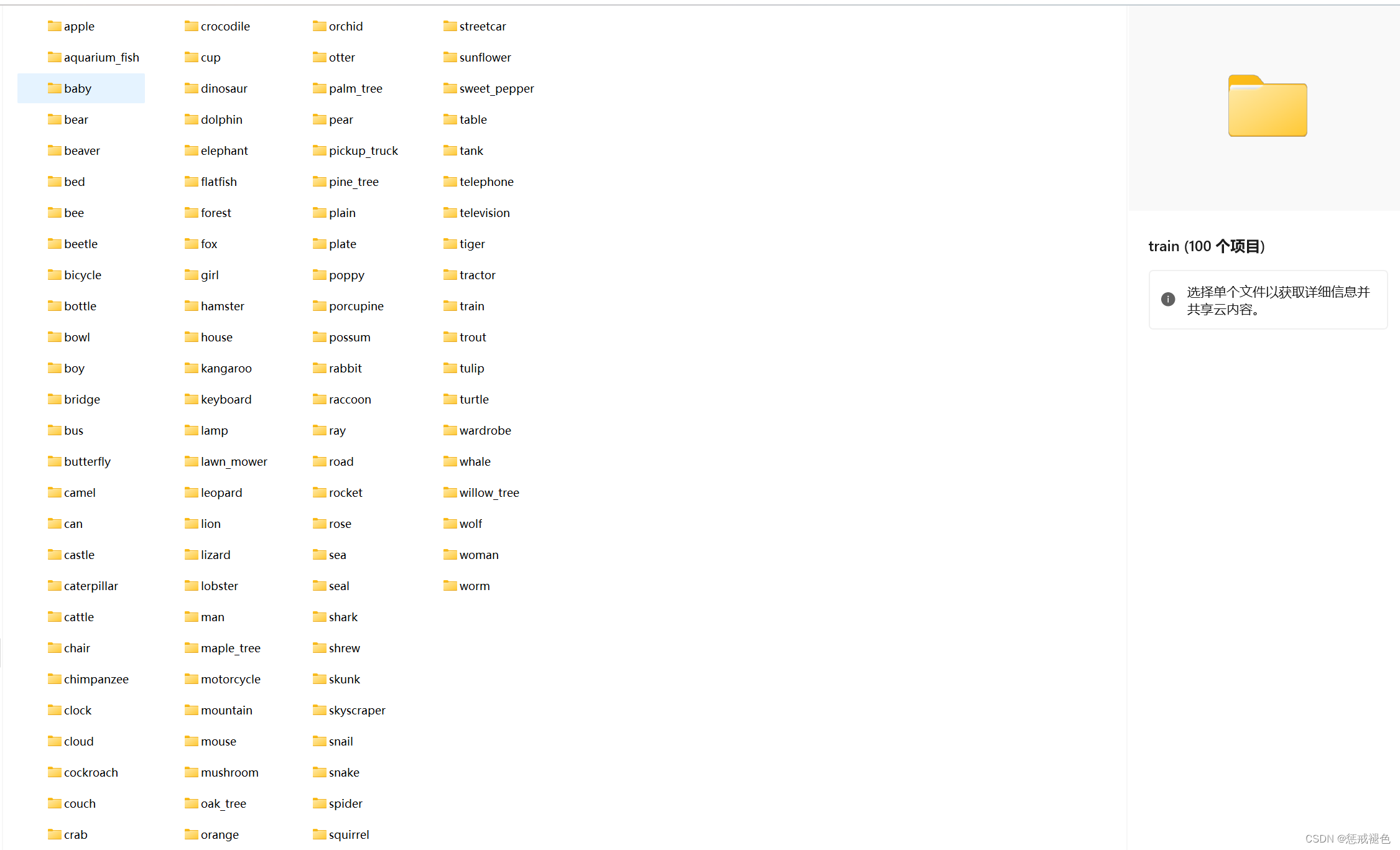
这里以cifar100数据集为例。cifar100数据集保存在train文件夹中,其中一共有100类图片,每类图片被保存在不同的子文件夹中,每类图片500张,其具体文件夹如下。
首先要引入cv2和os库,接着还要提前设置好图像保存路径和原图像文件路径。如果这里设置的不对的话程序会报错无法运行。比如这里我要调用的文件夹是train,处理后的图像保存到val文件夹中。
import os
import cv2
save_file = "val" #保存文件夹路径
directory = '.\\train' #原图像文件夹路径接着程序会使用os库对文件夹路径中的每一个子文件夹进行读取,并在处理后在保存路径文件夹中生成同名的子文件夹,并将处理后的图像保存在里面。
如果要处理的文件没有分为子文件夹的话可以将单独的一个文件夹放在另一个文件夹中,相当于做一个子文件夹只有一个的文件夹。
以下是处理后的图像文件命名,若需要修改保存的图片名称的话,从第三个'\\'后进行修改,即修改“ + filename + '_' + str(count) + '.jpg'”中的内容。
cv2.imwrite('.\\' + save_file + '\\' + filename + '\\' + filename + '_' + str(count) + '.jpg', image) #保存图片完整代码:
import os
import cv2
save_file = "save" #保存文件夹路径
directory = '.\\original' #原图像文件夹路径
filenames = os.listdir(directory) #读取原图像文件夹中的文件夹名称
count = 0
for filename in filenames:
print(filename) #打印正在处理的文件夹
if(os.path.exists(".\\" + save_file + '\\' + filename) == False): #判断子文件夹是否存在
os.makedirs(r".\\" + save_file + '\\' + filename) #创建子文件夹
img_folder = directory + "\\" + filename
image_files = os.listdir(img_folder)
for image_file in image_files:
image = cv2.imread(os.path.join(img_folder, image_file))
# 这里放对图像进行的处理
cv2.imwrite('.\\' + save_file + '\\' + filename + '\\' + filename + '_' + str(count) + '.jpg', image) #保存图片
count = count + 1
count = 0
print("done")这里我没有给出具体的图像处理代码,大家根据需要进行完形填空即可。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









