






R-CNN
Region proposals with CNNs(R-CNN)用分类的方法解决目标检测的问题。和之前的方法相比,R-CNN把mAP提高了30%多。
基本流程
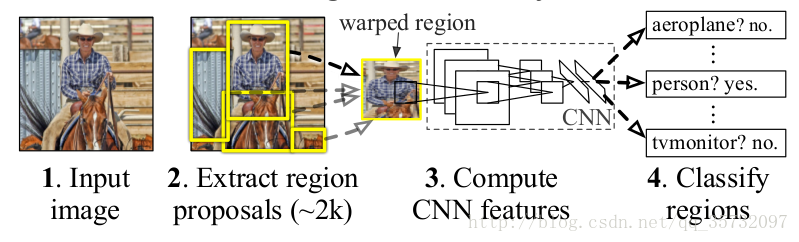
R-CNN模型分为4个步骤:
- 生成候选区域:一张原始图片生成约2000个候选区,文章采用的是Selective Search方法。
- 特征提取:把候选区域缩放到固定尺寸送入CNN做特征提取。固定尺寸取决于使用的网络模型,文章中用的是AlexNet,故缩放到227×227。
- 分类器:把提取的特征送入SVMs进行分类,判别属于哪个类别。
- 回归器:使用回归器精修候选框的四个参数。
训练
1. 有监督预训练
在数据量大的辅助数据集上(ILSVRC 2012)训练CNN网络,仅仅用分类标签训练。ILSVRC 2012数据集包含1000个类别的样本。
2. fine-tuning 微调
把1中的训练结果作为CNN的初始化参数,把CNN的输出由1000个类别改为21个类别,其他结构不变,再次进行训练。21个类别是VOC的20个类加上背景类构成。
训练数据:输入是region proposal,输出是类别。对于一个region proposal,若与任何一个ground-truth的IoU<=0.5,标记为正类,类别是IoU最大的ground-truth的类别;否则为负例,就是背景类。负例数量要远多于正例。
训练细节:随机梯度下降SGD;mini_batch = 128,其中32个正例(包含所有类别),96个背景类;步长为0.001。每个batch都偏向正例,提高了正例的比例。
3. 分类器
R-CNN又单独训练了SVMs分类器,没有直接采用2中的FC+softmax+cross entropy,并且样本正负例的划分也不同。对于一个候选框,当IoU<0.3时标记为负例(0.3这个值是在{0,0.1,…,0.5}六个阈值上做交叉验证得到的);只有ground truth被标记为正例。对于每个类别训练一个SVM分类器,由于训练数据太多,内存不够,文章采用了hard negative mining method。
如何做hard negative mining(困难样本挖掘)?
hard negative:就是false positive的样本,候选框标记为负例,预测为正例的样本。比如:一个候选框标记为背景类,但候选框中可能有一半包含了object,此时模型可能对这个框false positive,即把它预测为正例。
easy negative:候选框全是背景,模型就很容易把这样的框正确识别为背景类。
对于目标检测来说,大量的候选框为背景类,较少的框为目标类别,目标类别比较容易辨别(目标类的框IoU=1,因为只有ground truth被标记为正例),IoU接近0的背景类也容易,但是IoU不接近0的背景类容易被预测为某个目标类别,所以要重点关注。
hard negative mining方法就是在迭代中重点关注了false positive:进行一轮训练,用此时的模型对负例(背景类)进行预测,把被预测为正例的样本加入训练集合;进行新一轮的训练和关注。 为什么不直接采用fine-tuned CNN中的输出,而是又训练一个分类器?为什么在fine-tuning和SVM training阶段,正负例的划分标准不同?
作者尝试使用FC8的输出进行非极大值抑制,发现效果不如当前方法好。原因在于:训练CNN时,IoU>0.5就被标记为正例,这个条件对于分类器来说过于宽松,所以CNN不能实现精确定位;但是若把条件提高,比如阈值提高,则会减少正例的数量,不适合深度学习的训练。因此进行hard positive mining的SVM训练。训练支持向量机时,IoU=1为正例,IoU<0.3为负例,样本量减少,SVM适合小样本的分类问题。4.回归器
文章在误差分析中提到了 bounding box regression,精修之后mAP提高了3到4个百分点。
如何做bounding box regression?测试
按照开头提到的流程:SS提取候选框,缩放到227*227,送入CNN提取特征(AlexNet最后一个全连接层的输出reshape为4096-d的向量),最后分别送入分类器和回归器。
分类器输入候选框的特征向量,得到某个候选框在K=20个类别上的打分;对于2000个候选框,得到2000×20的矩阵。在矩阵的每一列上做贪婪的非极大值抑制(non-maximum suppression,NMS),即在每个类别上执行NMS,目的是去除相交的多余候选框。最后把分值小于某个阈值的的候选框剔除(文章没有提到,应该是这样),最终得到的候选框即为R-CNN检测的目标。(先剔除,再NMS应该也可以。)
如何做non-maximum suppression?
1.每一列2000个分值,按照将序排列。
2.选中得分最高的框,遍历剩下所有的框,若IoU大于某个阈值,则删除该框。
3.在剩下的proposals中,执行2,直到所有的proposals都被选中。














 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









