









文章目录
一、前言
前面已经介绍了几乎企业里使用到的绝大多数大数据组件了,这里来个简单的总结,主要针对常见的操作进行总结。也方便自己和大家在工作中快速查阅。
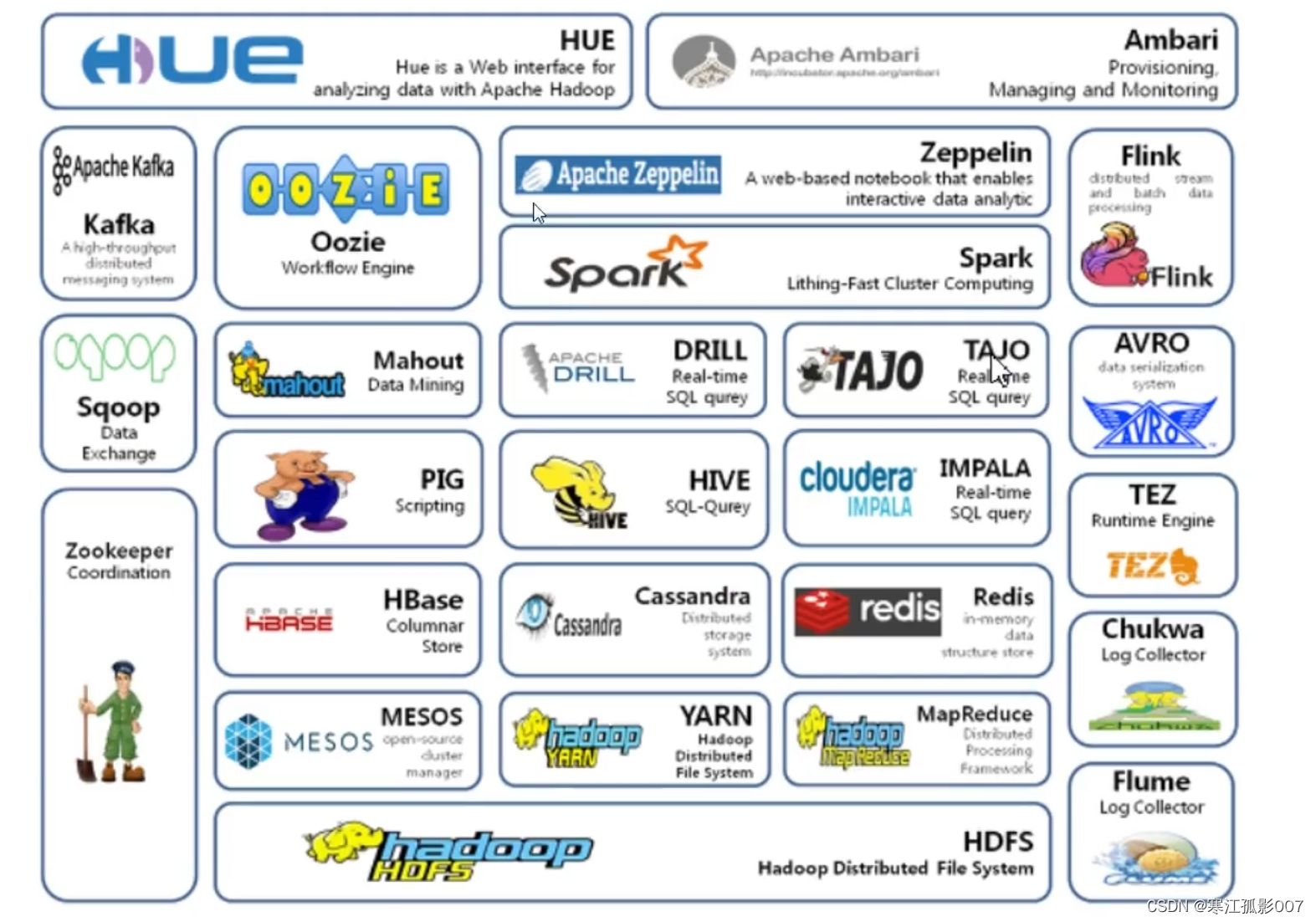
二、Hadoop
Hadoop介绍与环境部署可以参考:
- 大数据Hadoop生态系统介绍
- 大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
- 大数据Hadoop之——Hadoop 3.3.4 HA(高可用)原理与实现(QJM)
- 大数据Hadoop之——Hadoop HDFS多目录磁盘扩展与数据平衡实战操作
- 大数据Hadoop之——HDFS小文件问题与处理实战操作
1)HDFS常见操作
HDFS web地址(默认端口:9000):
http://local-168-182-110:9870/
http://local-168-182-113:9870/
1、HDFS服务启停命令
hdfs --daemon [start|stop] [namenode|datanode|secondarynamenode|journalnode]
start-dfs.sh
stop-dfs.sh
# 重启HDFS和YARN相关所有服务
start-all.sh
2、常见文件操作命令
### 访问本地文件系统
hdfs dfs -ls file:///
### 访问HDFS系统
# 默认不带协议就是访问hdfs文件系统,下面两行命令等价
hdfs dfs -ls /
hdfs dfs -ls ///
# 带协议就是访问hdfs文件系统,默认端口:9000
hdfs dfs -ls hdfs://local-168-182-110:8082/
### 创建文件
hdfs dfs -mkdir -p /test/t{1..5}
### 创建目录
hdfs dfs -touch /test/t666
### 上传文件
hdfs dfs -put anaconda-ks.cfg /test/
### 下载文件
hdfs dfs -get /test/t666 ./
3、安全模式操作命令
# 退出安装模式
hdfs dfsadmin -safemode leave
# 打开安全模式
hdfs dfsadmin -safemode enter
4、数据平衡常见操作命令
# 启动数据平衡,默认阈值为 10%
hdfs balancer
# 默认相差值为10% 带宽速率为10M/s,过程信息会直接打印在客户端 ctrl+c即可中止
hdfs balancer -Ddfs.balancer.block-move.timeout=600000
#可以手动设置相差值 一般相差值越小 需要平衡的时间就越长,//设置为20% 这个参数本身就是百分比 不用带%
hdfs balancer -threshold 20
#如果怕影响业务可以动态设置一下带宽再执行上述命令,1M/s
hdfs dfsadmin -setBalancerBandwidth 1048576
#或者直接带参运行,带宽为1M/s
hdfs balancer -Ddfs.datanode.balance.bandwidthPerSec=1048576 -Ddfs.balancer.block-move.timeout=600000
5、处理小文件常见操作命令
### 1、通过Hadoop Archive(HAR)方式进行合并小文件
# 【用法】hadoop archive -archiveName 归档名称 -p 父目录 [-r <复制因子>] 原路径(可以多个) 目的路径
# 合并/foo/bar目录下的文件,输出到/outputdir
hadoop archive -archiveName user.har -p /foo/bar /outputdir
# 执行该命令后,原输入文件不会被删除,需要手动删除
hdfs dfs -rm -r /foo/bar/user*.txt
### 2、har解压
# 按顺序解压存档(串行)
hdfs dfs -cp har:///outputdir/user.har /outputdir/newdir
# 查看
hdfs dfs -ls /outputdir/newdir
# 3、要并行解压存档,请使用DistCp,会提交MR任务进行并行解压
hadoop distcp har:///outputdir/user.har /outputdir/newdir2
# 查看
hdfs dfs -ls /outputdir/newdir2
### 4、合并本地的小文件,上传到 HDFS(appendToFile )
hdfs dfs -appendToFile user1.txt user2.txt /test/upload/merged_user.txt
# 查看
hdfs dfs -cat /test/upload/merged_user.txt
### 5、合并 HDFS 的小文件,下载到本地(getmerge)
# 先上传小文件到 HDFS:
hdfs dfs -put user1.txt user2.txt /test/upload
# 下载,同时合并:
hdfs dfs -getmerge /test/upload/user*.txt ./merged_user.txt
6、HDFS NameNode主备切换命令
# 设置nn1为Standby,nn2为Active
# 当HDFS的HA配置中开启了自动故障转移时,需加上--forcemanual参数(谨慎使用此参数)
hdfs haadmin -transitionToStandby --forcemanual nn1
hdfs haadmin -transitionToActive --forcemanual nn2
# 查看
#hdfs haadmin -getServiceState nn1
#hdfs haadmin -getServiceState nn2
# 查看所有节点状态
hdfs haadmin -getAllServiceState
2)YARN常见操作
YARN web地址(默认端口:8088):
http://local-168-182-110:8088/cluster/cluster
http://local-168-182-113:8088/cluster/cluster
1、YARN服务启停命令
yarn --daemon [start|stop] [resourcemanager|nodemanager]
start-yarn.sh
stop-yarn.sh
# 重启HDFS和YARN相关所有服务
start-all.sh
# 启动mapreduce任务历史服务
mapred --daemon start historyserver
2、常见操作命令
# 列出在运行的应用程序
yarn application --list
# 列出FINISHED的应用程序
yarn application -appStates FINISHED --list
### 参数
-appStates <States> #与-list一起使用,可根据输入的逗号分隔的应用程序状态列表来过滤应用程序。有效的应用程序状态可以是以下之一:ALL,NEW,NEW_SAVING,SUBMITTED,ACCEPTED,RUNNING,FINISHED,FAILED,KILLED
-appTypes <Types> #与-list一起使用,可以根据输入的逗号分隔的应用程序类型列表来过滤应用程序。
-list #列出RM中的应用程序。支持使用-appTypes来根据应用程序类型过滤应用程序,并支持使用-appStates来根据应用程序状态过滤应用程序。
-kill <ApplicationId> #终止应用程序。
-status <ApplicationId> #打印应用程序的状态。
3、YARN ResourceManager 主备切换命令
# 设置rm1为Standby,设置rm2为Active
# 当YARN的HA配置中开启了自动故障转移时,需加上-forcemanual 参数(谨慎使用此参数)
yarn rmadmin -transitionToStandby -forcemanual rm1
yarn rmadmin -transitionToActive -forcemanual rm2
# 查看
#yarn rmadmin -getServiceState rm1
#yarn rmadmin -getServiceState rm2
yarn rmadmin -getAllServiceState
三、数据仓库Hive
Hive介绍与环境部署可以参考:大数据Hadoop之——数据仓库Hive
1)Hive服务启停命令
# 启动元数据服务,默认端口:9083
nohup hive --service metastore &
# 启动hiveserver2(hs2),默认端口:10000
nohup hiveserver2 > /dev/null 2>&1 &
# 停止服务就用kill
2)Hive常见操作命令
hive --help
### 交互式命令
hive
# 查看数据库
hive> show databases;
# 查看当前库(默认是default库)的表
hive> show tables;
# 查看当前库
hive> select current_database();
### 非交互式命令
hive -e 'show databases';
# 指定本地文件
hive -f ./test001.sql
# 指定hdfs文件,hdfs默认端口:9000
hive -f hdfs://local-168-182-110:8082/test001.sql
### 配置Hive变量
hadoop fs -mkdir -p /user/hive/warehouse/test
hive -e 'select * from users' \
--hiveconf hive.exec.scratchdir=/user/hive/warehouse/test \
--hiveconf mapred.reduce.tasks=4;
3)Beeline常见操作命令
beeline --help
### 交互式命令,交互式连接
beeline
beeline> !connect jdbc:hive2://local-168-182-110:11000
Enter username for jdbc:hive2://local-168-182-110:11000: root
# 密码直接回车就行
Enter password for jdbc:hive2://local-168-182-110:11000:
0: jdbc:hive2://local-168-182-110:11000> show databases;
### 交互式命令,非交互式连接
beeline -u jdbc:hive2://local-168-182-110:11000 -n root
### 非交互操作,如果有密码。加-p密码
beeline -u jdbc:hive2://local-168-182-110:11000 -n root -e "use default;show tables;"
beeline -u jdbc:hive2://local-168-182-110:11000 -n root -f hivescript.sql
beeline -u jdbc:hive2://local-168-182-110:11000 -n root -f hdfs://local-168-182-110:8082/hivescript.sql
4)Load加载数据
# 创建表
create table person_local_1(id int,name string,age int) row format delimited fields terminated by ',';
create table person_hdfs_1(id int,name string,age int) row format delimited fields terminated by ',';
show tables;
# 从local加载数据,这里的local是指hs2服务所在机器的本地linux文件系统
load data local inpath '/opt/bigdata/hadoop/data/hive-data' into table person_local_1;
# 查询
select * from person_local_1;
# 从hdfs中加载数据,这里是移动,会把hdfs上的文件mv到对应的hive的目录下
load data inpath '/person_hdfs.txt' into table person_hdfs_1;
# 查询
select * from person_hdfs_1;
四、计算引擎Spark
Spark介绍与环境部署可以参考:
- 大数据Hadoop之——计算引擎Spark
- 大数据Hadoop之——Spark集群部署(Standalone)
- 大数据Hadoop之——Spark SQL+Spark Streaming
- 大数据Hadoop之——Spark on Hive 和 Hive on Spark的区别与实现
- 大数据Hadoop之——Spark Streaming原理
Spark常见操作
【温馨提示】Spark是程序级的,是没有后台进程服务的,直接提交任务到yarn即可。如果是独立集群模式,是需要独立启动Spark集群服务的,但是一般企业里都是跑在yarn集群上。
提交Yarn任务示例:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1G \
--num-executors 3 \
--executor-memory 1G \
--executor-cores 1 \
/opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.0.jar 100
启动查看日志服务
#启动JobHistoryServer服务
mapred --daemon start historyserver
#查看进程
jps
#停止JobHistoryServer服务
mapred --daemon stop historyserver
五、实时计算流计算引擎Flink
Flink介绍与环境部署可以参考:
- 大数据Hadoop之——实时计算流计算引擎Flink(Flink环境部署)
- 大数据Hadoop之——Flink Table API 和 SQL(单机Kafka)
- 大数据Hadoop之——Flink DataStream API 和 DataSet API
- 大数据Hadoop之——Flink中的Window API+时间语义+Watermark
- 大数据Hadoop之——Flink的状态管理和容错机制(checkpoint)
- 大数据Hadoop之——Flink CEP(Complex Event Processing:复合事件处理)详解(kafka on window)
【温馨提示】Flink跟Spark一样是程序级的,是没有后台进程服务的,直接提交任务到yarn即可。
1)Session模式提交任务
$FLINK_HOME/bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 -d
### 参数解释:
#-n 2 表示指定两个容器
# -jm 1024 表示jobmanager 1024M内存
# -tm 1024表示taskmanager 1024M内存
#-d 任务后台运行
### 如果你不希望flink yarn client一直运行,也可以启动一个后台运行的yarn session。使用这个参数:-d 或者 --detached。在这种情况下,flink yarn client将会只提交任务到集群然后关闭自己。注意:在这种情况下,无法使用flink停止yarn session,必须使用yarn工具来停止yarn session。
# yarn application -kill $applicationId
#-nm,--name YARN上为一个自定义的应用设置一个名字
#-q,--query 显示yarn中可用的资源 (内存, cpu核数)
#-z,--zookeeperNamespace <arg> 针对HA模式在zookeeper上创建NameSpace
#-id,--applicationId <yarnAppId> YARN集群上的任务id,附着到一个后台运行的yarn session中
2)Per-Job 模式提交任务
$FLINK_HOME/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
3)Application模式提交任务
$FLINK_HOME/bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dparallelism.default=10 \
-Dyarn.application.name="MyFlinkApp" \
./examples/batch/WordCount.jar
六、任务调度器Azkaban
Azkaban介绍与环境部署可以参考:
Azkaban常见操作命令
### 启停AzkabanExecutorServer,端口随机,最好在配置文件中指定端口
$AZKABAN_HOME/bin/start-exec.sh
$AZKABAN_HOME/bin/shutdown-exec.sh
# AzkabanExecutorServer
telnet -tnlp|grep 12321
# 通过接口的方式去激活节点
curl -G "hadoop-node1:12321/executor?action=activate" && echo
### 启停AzkabanWebServer,http默认端口:8081,https默认端口:443
$AZKABAN_HOME/bin/start-web.sh
$AZKABAN_HOME/bin/shutdown-web.sh
netstat -tnlp|grep 443
七、基于内存型SQL查询引擎Presto
Presto介绍与环境部署可以参考:大数据Hadoop之——基于内存型SQL查询引擎Presto(Presto-Trino环境部署)))
1)Presto(Trino)服务启停
### Presto(Trino)服务启停,默认端口:8080
$PRESTO_HOME/bin/launcher start
$PRESTO_HOME/bin/launcher stop
web访问验证:http://hadoop-node1:8080
2)常见 CLI 操作
### 连接测试
$PRESTO_HOME/bin/trino --server hadoop-node1:8080
# 命令不区分大小写
show catalogs;
# 查库
show schemas from system;
# 查表
show tables from system.runtime;
# 查具体记录,查看当前node节点记录
select * from system.runtime.nodes;
八、数据同步工具Sqoop
Sqoop介绍与环境部署可以参考:大数据Hadoop之——数据同步工具Sqoop
1)Sqoop 服务启停
sqoop2-server start
sqoop2-server stop
# 查看端口,默认是12000,可以修改conf/sqoop.properties的org.apache.sqoop.jetty.port字段来修改端口
netstat -tnlp|grep 12000
2)常见CLI操作
$ sqoop2-shell
# 查看帮助
help
# 配置服务
set server --url http://hadoop-node1:12000/sqoop
show server --all
# 显示持久的作业提交对象
show submission
show submission --j jobName
show submission --job jobName --detail
# 显示所有链接
show link
# 显示连接器
show connector
九、数据同步工具DataX
DataX介绍与环境部署可以参考:大数据Hadoop之——数据同步工具DataX
# 需要注意,这里需要安装python2,虽然官网说Pytho3也可以,其实datax.py里面还是python2的语法
yum -y install python2
cd $DATAX_HOME/bin
python2 datax.py -r streamreader -w streamwriter
根据模板配置json如下:
$ cat > stream2stream.json<<EOF
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
EOF
执行
python2 datax.py ./stream2stream.json
十一、Kafka相关
Kafka介绍与环境部署可以参考:
- 分布式开源协调服务——Zookeeper
- 大数据Hadoop之——Kafka 图形化工具 EFAK(EFAK环境部署)
- Kerberos认证原理与环境部署
- 大数据Hadoop之——Kafka鉴权认证(Kafka kerberos认证+kafka账号密码认证+CDH Kerberos认证)
- 大数据Hadoop之——Zookeeper鉴权认证(Kerberos认证+账号密码认证)
- 大数据Hadoop之——Kafka Streams原理介绍与简单应用示例
- 大数据Hadoop之——Kafka API介绍与实战操作
1)Zookeeper常见操作
### 服务启停,默认端口:2181
$ZOOKEEPER_HOME/bin/zkServer.sh start
$ZOOKEEPER_HOME/bin/zkServer.sh stop
# 查看状态
$ZOOKEEPER_HOME/bin/zkServer.sh status
#### 与kafka集成启停
./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
./bin/zookeeper-server-stop.sh
### 客户端操作
# 独立zookeeper客户端启动如下:
$ZOOKEEPER_HOME/zkCli.sh -server hadoop-node1:2181
# kafka自带的zookeeper客户端启动如下:
$KAFKA_HOME/bin/zookeeper-shell.sh hadoop-node1:2181
2)Kafka 常见操作
### kafka 启停
# 默认端口9092,这里修改成了19092,可以修改listeners和advertised.listeners
$KAFKA_HOME/bin/kafka-server-start.sh -daemon ./config/server.properties
$KAFKA_HOME/bin/kafka-server-stop.sh
Kafka CLI简单使用
- 【增】添加topic
# 创建topic,1副本,1分区,设置数据过期时间72小时(-1表示不过期),单位ms,72*3600*1000=259200000
$ kafka-topics.sh --create --topic test002 --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --partitions 1 --replication-factor 1 --config retention.ms=259200000
- 【查】
# 查看topic列表
$ kafka-topics.sh --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --list
# 查看topic列表详情
$ kafka-topics.sh --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --describe
# 指定topic
$ kafka-topics.sh --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --describe --topic test002
# 查看消费者组
$ kafka-consumer-groups.sh --bootstrap-server hadoop-node1:9092 --list
$ kafka-consumer-groups.sh --bootstrap-server hadoop-node1:9092 --describe --group test002
- 【改】这里主要是修改最常用的三个参数:分区、副本,过期时间
# 修改分区,扩分区,不能减少分区
kafka-topics.sh --alter --bootstrap-server hadoop-node1:9092 --topic test002 --partitions 2
# 修改过期时间,下面两行都可以
$ kafka-configs.sh --bootstrap-server hadoop-node1:9092 --alter --topic test002 --add-config retention.ms=86400000
$ kafka-configs.sh --bootstrap-server hadoop-node1:9092 --alter --entity-name test002 --entity-type topics --add-config retention.ms=86400000
# 修改副本数,将副本数修改成3
cat >1.json<<EOF
{"version":1,
"partitions":[
{"topic":"test002","partition":0,"replicas":[0,1,2]},
{"topic":"test002","partition":1,"replicas":[1,2,0]},
{"topic":"test002","partition":2,"replicas":[2,0,1]}
]}
EOF
kafka-topics.sh --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --describe --topic test002
- 【删】
kafka-topics.sh --delete --topic test002 --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092
- 【生成者】
kafka-console-producer.sh --broker-list hadoop-node1:9092 --topic test002
{"id":"1","name":"n1","age":"20"}
{"id":"2","name":"n2","age":"21"}
{"id":"3","name":"n3","age":"22"}
- 【消费者】
# 从头开始消费
kafka-console-consumer.sh --bootstrap-server hadoop-node1:9092 --topic test002 --from-beginning
# 指定从分区的某个位置开始消费,这里只指定了一个分区,可以多写几行或者遍历对应的所有分区
kafka-console-consumer.sh --bootstrap-server hadoop-node1:9092 --topic test002 --partition 0 --offset 100
- 【消费组】
kafka-console-consumer.sh --bootstrap-server hadoop-node1:9092 --topic test002 --group test002
- 【查看数据积压】
kafka-consumer-groups.sh --bootstrap-server hadoop-node1:9092 --describe --group test002
3)EFAK 常见操作
### 服务启停
# 单机版
$KE_HOME/bin/ke.sh start
$KE_HOME/bin/ke.sh stop
# 集群方式启动
$KE_HOME/bin/ke.sh cluster start
$KE_HOME/bin/ke.sh cluster stop
$KE_HOME/bin/ke.sh启动脚本中包含以下命令:
| 命令 | 描述 |
|---|---|
| ke.sh start | 启动 EFAK 服务器。 |
| ke.sh status | 查看 EFAK 运行状态。 |
| ke.sh stop | 停止 EFAK 服务器。 |
| ke.sh restart | 重新启动 EFAK 服务器。 |
| ke.sh stats | 查看 linux 操作系统中的 EFAK 句柄数。 |
| ke.sh find [ClassName] | 在 jar 中找到类名的位置。 |
| ke.sh gc | 查看 EFAK 进程 gc。 |
| ke.sh version | 查看 EFAK 版本。 |
| ke.sh jdk | 查看 EFAK 安装的 jdk 详细信息。 |
| ke.sh sdate | 查看 EFAK 启动日期。 |
| ke.sh cluster start | 查看 EFAK 集群分布式启动。 |
| ke.sh cluster status | 查看 EFAK 集群分布式状态。 |
| ke.sh cluster stop | 查看 EFAK 集群分布式停止。 |
| ke.sh cluster restart | 查看 EFAK 集群分布式重启。 |
4)Kerberos 常见操作
### 启停 Kerberos 服务
systemctl start krb5kdc kadmin
systemctl stop krb5kdc kadmin
# 查看服务状态
systemctl status krb5kdc kadmin
基本命令操作
管理KDC数据库有两种方式:
- 一种直接在KDC(server端)直接执行,可以不需要输入密码就可以登录【命令:kadmin.local】
- 一种则是客户端命令,需要输入密码【命令:kadmin】,在server端和client端都可以使用。
# 交互式
kadmin.local
add_principal root/admin
# 非交互式
kadmin.local -q "add_principal root/admin"
### kinit(在客户端认证用户)
kinit root/admin@HADOOP.COM
# 查看当前的认证用户
klist
### 基于密钥认证(keytab)
# 删除当前用户认证
$ kdestroy
### 导出keytab认证文件
# 使用xst命令或者ktadd命令:
# 非交互式
kadmin.local -q "ktadd -norandkey -k /root/root.keytab root/admin"
# 交互式
kadmin.local
ktadd -norandkey -k /root/root.keytab root/admin
#或xst -k /root/v.keytab root/admin
#或xst -norandkey -k /root/root.keytab root/admin
### 查看密钥文件
klist -kt /root/root.keytab
# 拿到上面生成的keytab文件
kinit -kt /root/root.keytab root/admin
klist
十二、Doris
Doris介绍与环境部署可以参考:
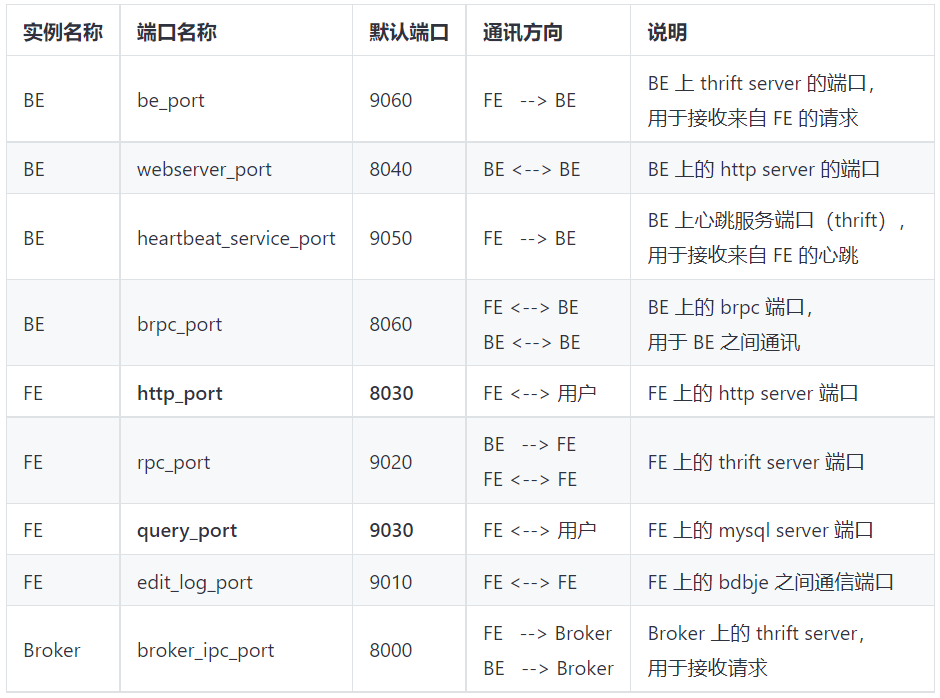
1)FE节点常见操作
### 服务启停,首次启动时,需要指定现有集群中的一个节点作为helper节点
# $STARROCKS_HOME/fe/bin/start_fe.sh --helper host:port --daemon
### 启动第一个节点
${STARROCKS_HOME}/fe/bin/start_fe.sh --daemon
### 启动其它fe节点
$STARROCKS_HOME/bin/start_fe.sh --helper 192.168.0.120:9010 --daemon
### 添加 FE 节点
mysql -h 192.168.0.113 -P9030 -uroot
ALTER SYSTEM ADD FOLLOWER "192.168.0.116:9010";
### 停止FE
${STARROCKS_HOME}/bin/stop_fe.sh --daemon
### 查看FE 状态
mysql -h 192.168.0.120 -P9030 -uroot
SHOW PROC '/frontends'\G
2)BE节点常见操作
### 启停BE
$STARROCKS_HOME/be/bin/start_be.sh --daemon
$STARROCKS_HOME/be/bin/stop_be.sh --daemon
### 添加BE节点
mysql -h 192.168.0.113 -P9030 -uroot
# ALTER SYSTEM ADD BACKEND "host:port";
ALTER SYSTEM ADD BACKEND "192.168.0.114:9050";
### BE 节点从集群移除
ALTER SYSTEM decommission BACKEND "192.168.0.114:9050";
### 查看BE状态
mysql -h 192.168.0.113 -P9030 -uroot
SHOW PROC '/backends'\G
3)Borker节点常见操作
### 启停 Broker
$STARROCKS_HOME/apache_hdfs_broker/bin/start_broker.sh --daemon
$STARROCKS_HOME/apache_hdfs_broker/bin/stop_broker.sh --daemon
### 添加 Broker 节点
mysql -h 192.168.0.113 -P9030 -uroot
# ALTER SYSTEM ADD BROKER broker1 "172.16.xxx.xx:8000";
# 说明:默认配置中,Broker 节点的端口为 8000。
ALTER SYSTEM ADD BROKER broker1 "192.168.0.113:8000";
ALTER SYSTEM ADD BROKER broker2 "192.168.0.114:8000";
ALTER SYSTEM ADD BROKER broker3 "192.168.0.115:8000";
ALTER SYSTEM ADD BROKER broker4 "192.168.0.116:8000";
### 查看Broker节点状态
mysql -h 192.168.0.113 -P9030 -uroot
SHOW PROC "/brokers"\G
十三、ClickHouse
ClickHouse介绍与环境部署可以参考:
ClickHouse 常见操作
### 服务启停
systemctl start clickhouse-server
systemctl stop clickhouse-server
### CLI 操作,查看集群状态
clickhouse-client -u default --password 123456 --port 9000 -h local-168-182-110 --multiquery
select * from system.clusters;
十四、MinIO
MinIO介绍与环境部署可以参考:
MinIO常见操作
编写启动脚本(/opt/bigdata/minio/run.sh)
#!/bin/bash
# 创建日志存储目录
mkdir -p /opt/bigdata/minio/logs
# 分别在三个节点上创建存储目录
mkdir -p /opt/bigdata/minio/data/export{1,2,3,4}
# 创建配置目录
mkdir -p /etc/minio
export MINIO_ROOT_USER=admin
export MINIO_ROOT_PASSWORD=admin123456
# 在三台机器上都执行该文件,即以分布式的方式启动了MINIO
# --address "0.0.0.0:9000" 挂载9001端口为api端口(如Java客户端)访问的端口
# --console-address ":9000" 挂载9000端口为web端口;
/opt/bigdata/minio/minio server --address 0.0.0.0:9000 --console-address 0.0.0.0:9001 --config-dir /etc/minio \
http://local-168-182-110/opt/bigdata/minio/data/export1 \
http://local-168-182-110/opt/bigdata/minio/data/export2 \
http://local-168-182-110/opt/bigdata/minio/data/export3 \
http://local-168-182-110/opt/bigdata/minio/data/export4 \
http://local-168-182-111/opt/bigdata/minio/data/export1 \
http://local-168-182-111/opt/bigdata/minio/data/export2 \
http://local-168-182-111/opt/bigdata/minio/data/export3 \
http://local-168-182-111/opt/bigdata/minio/data/export4 \
http://local-168-182-112/opt/bigdata/minio/data/export1 \
http://local-168-182-112/opt/bigdata/minio/data/export2 \
http://local-168-182-112/opt/bigdata/minio/data/export3 \
http://local-168-182-112/opt/bigdata/minio/data/export4 > /opt/bigdata/minio/logs/minio_server.log
启动服务
# 在三台机器上都执行该文件,即以分布式的方式启动了MINIO
sh /opt/bigdata/minio/run.sh
添加或修改minio.service,通过systemctl启停服务(推荐)
# 如果使用rpm安装,minio.service就会自动生成,只要修改就行
cat > /usr/lib/systemd/system/minio.service <<EOF
[Unit]
Description=Minio service
Documentation=https://docs.minio.io/
[Service]
WorkingDirectory=/opt/bigdata/minio
ExecStart=/opt/bigdata/minio/run.sh
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
启动集群
#重新加载服务
systemctl daemon-reload
#启动服务
systemctl start minio
#加入自启动
systemctl enable minio
十五、HBase
HBase介绍与环境部署可以参考:
HBase常见操作
### 启动和停止HBase
start-hbase.sh
stop-hbase.sh
### CLI操作
#登入HBase(跟MySQL类似)
hbase shell
create 'test', 'cf'
# 使用list命令确认您的表存在
list 'test'
# 现在使用describe命令查看详细信息,包括配置默认值
describe 'test'
十六、Apache Livy
Livy介绍与环境部署可以参考:Spark开源REST服务——Apache Livy(Spark 客户端)
Apache Livy常见操作
### 服务启停
sh $LIVY_HOME/bin/livy-server start
netstat -tnlp|grep 8998
sh $LIVY_HOME/bin/livy-server stop
【示例】创建交互式会话
# 新建Session
curl -XPOST -d '{"kind": "spark"}' -H "Content-Type: application/json" http://local-168-182-110:8998/sessions
#执行结果为:
{
"id":0, -- session id
"name":null,
"appId":null,
"owner":null,
"proxyUser":null,
"state":"starting", -- session 状态
"kind":"spark",
"appInfo":{ -- app 信息
"driverLogUrl":null,
"sparkUiUrl":null
},
"log":[
"stdout: ",
"\nstderr: ",
"\nYARN Diagnostics: "
]
}
【示例】批处理会话(Batch Session)
# POST http://local-168-182-110:8998/batches
curl -XPOST -d '{"file":"hdfs://local-168-182-110:8082/user/livy/spark-examples_2.12-3.3.0.jar","className":"org.apache.spark.examples.SparkPi","name":"SparkPi"}' -H "Content-Type: application/json" http://local-168-182-110:8998/batches
# 输出:
{
"id":0,
"name":"SparkPi",
"owner":null,
"proxyUser":null,
"state":"starting",
"appId":null,
"appInfo":{
"driverLogUrl":null,
"sparkUiUrl":null
},
"log":[
"stdout: ",
"\nstderr: ",
"\nYARN Diagnostics: "
]
}
大数据组件相关的总结就先到这里了,还有一些不常用,或者是图形化界面操作的就没列在这里,有疑问的小伙伴欢迎给我留言哦~



















 1917
1917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









