







1.在Master节点机器上 安装spark
2 配置环境变量
vim /etc/profile
添加以下:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
刷新:
source /etc/profile
3 Spark配置
在Master节点主机上进行如下操作:
- 配置slaves文件
- 将 slaves.template 拷贝到 slaves
cd /usr/local/spark/
cp ./conf/slaves.template ./conf/slaves
slaves文件设置Worker节点。编辑slaves内容
vim ./conf/slaves
把默认内容localhost替换成如下内容:
slave01
slave02
配置spark-env.sh文件
将 spark-env.sh.template 拷贝到 spark-env.sh
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh
vim ./conf/spark-env.sh
添加如下内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=172.17.0.2
SPARK_MASTER_IP 指定 Spark 集群 Master 节点的 IP 地址;
配置好后,将Master主机上的/usr/local/spark文件夹复制到各个节点上。在Master主机上执行如下命令:
cd /usr/local/
tar -zcf ~/spark.master.tar.gz ./spark
cd ~
scp ./spark.master.tar.gz slave01:/home/spark.tar.gz
scp ./spark.master.tar.gz slave02:/home/spark.tar.gz
在slave01,slave02节点上分别执行下面同样的操作:
rm -rf /usr/local/spark/
cd /home
tar -zxvf spark.tar.gz
mv spark/ /usr/local/
4 启动Spark集群
启动Spark集群前,要先启动Hadoop集群。在Master节点主机上运行如下命令:
cd /usr/local/hadoop/
.sbin/start-all.sh
然后启动Spark
启动Master节点
在Master节点主机上运行如下命令:
cd /usr/local/spark/
.sbin/start-master.sh
在Master节点上运行jps命令,可以看到多了个Master进程:
启动所有Slave节点
在Master节点主机上运行如下命令:
.sbin/start-slaves.sh
报错:

spark slave01: JAVA_HOME is not set
解决:
进入对应的slave的spark根目录
cd /usr/local/spark/sbin
在sbin目录下的spark-config.sh 中添加对应的jdk路径!
## JAVA 添加java_home路径
export JAVA_HOME=/usr/java/jdk
export PATH=$PATH:$JAVA_HOME/bin

Shell 命令
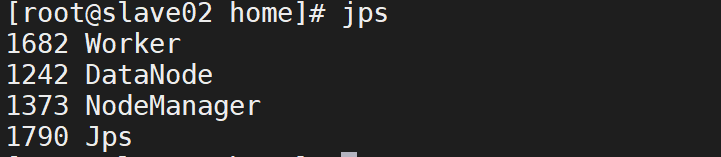
分别在slave01、slave02节点上运行jps命令,可以看到多了个Worker进程

5 关闭Spark集群
关闭Master节点
.sbin/stop-master.sh
Shell 命令
关闭Worker节点
.sbin/stop-slaves.sh
Shell 命令
关闭Hadoop集群
cd /usr/local/hadoop/
.sbin/stop-all.sh















 3903
3903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









