







ES&Hbase

(一)、OLTP、OLAP
数据处理大致可以分为两大类:联机事务处理OLTP、联机分析处理OLAP。
1、OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如:银行交易。
2、OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP通过多维的方式对数据进行分析、查询和报表,维指的是用户观察数据的角度,多维分析是指对以多维形式组织起来的数据采取切片、切块、钻取、旋转等各种分析动作,以求剖析数据。
- 钻取:是改变维的层次,变换分析的粒度。它包括向下钻取(Drill-down)和向上钻取(Drill-up)/上卷(Roll-up)。Drill-up是在某一维上将低层次的细节数据概括到高层次的汇总数据,或者减少维数;而Drill-down则相反,它从汇总数据深入到细节数据进行观察或增加新维。
- 切片和切块:是在一部分维上选定值后,关心度量数据在剩余维上的分布。如果剩余的维只有两个,则是切片;如果有三个或以上,则是切块。
- 旋转:是变换维的方向,即在表格中重新安排维的放置(例如行列互换)。
3、二者区别:
处理数据的时效性:OLTP时效性性更强,(实时性要求高)一般来数据便进行处理,而OLAP是天级运行,t+1类型应用(实时性要求不高)
吞吐量:OLTP几十条、OLAP达百万级
设计理念:OLTP应用范式建模,OLAP用的是维度建模中的星型模型或雪花模型
(二)、HBase、ES
1、HBase:基于HDFS,支持海量数据读写,尤其是写,支持上亿行、上百万列的分布式NoSql(非关系型数据库)数据库。天然分布式,主从架构,不支持事务,不支持二级索引,不支持sql。
- 数据存储方式:列为单位存储数据,Key-Value,不用提前定义列属性,动态扩展,
| ID | Name | Age | Sex |
| 1 | mxl | 23 | G |
以<Key>,Value形式存储,row+列名作为:key,data作为Value,依次存放,某一列无数据,直接跳过,可以节省空间。
<1,Name>,mxl
<1,Age>,23
- 容灾
HBase是采用写log的方式防止数据丢失,数据写内存的同时,同时也会写入HLog,HLog也是存储在HDFS上,写入HLog后才会认为数据写成功,某个regionserver挂掉之后,master将故障机器上的regions调度到别的regionserver上,regionserver通过回放HLog来恢复region的数据,恢复成功后,region重新上线,由于log是直接写在HDFS上,所以不用担心单个节点挂掉log数据丢失的问题。
- 查询引擎:Phoniex 可以让开发者在HBase数据集上使用SQL查询。Phoenix查询引擎会将SQL查询转换为一个或多个HBase scan,并编排执行以生成标准的JDBC结果集,对于简单查询来说,性能甚至胜过Hive
接入这个插件后可用标准的SQL进行查询
- Phoenix简介:
Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。
- Phoenix语法需要注意
1) Phoenix的SQL中如果表名、字段名不使用双引号标注那么默认转换成大写。
2) Phoenix中的字符串使用单引号进行标注。
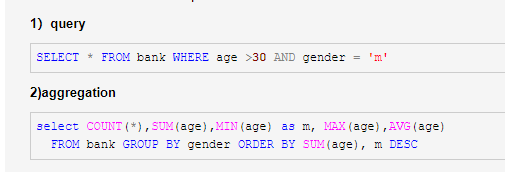
3)查询:SELECT * FROM us_population WHERE state = 'NA' AND population > 10000 ORDER BY population DESC;
在进行查询时,支持ORDER BY、GROUP BY、LIMIT、JOIN等操作,同时Phoenix提供了一系列的函数,其中包括COUNT()、MAX()、MIN()、SUM()等
2、ES(ElasticSearch): 分布式的全文检索框架,底层基于Lucene实现,天然分布式,p2p架构,不支持事务,采用倒排索引提供全文检索
- 数据存储方式:比较灵活,索引中的field类型可以提前定义(定义mapping),也可以不定义,最好关键字段提前定义好
集群、节点、索引、类型、文档、字段、分片
理解:index可以理解成数据库,假设数据库名字称为test,里面的表t1存放10条数据,那么分给A,B,C3个不同的分片,A分片存test数据库,存储t1表中的前3条数据;B分片存存test数据库,存储t1表中的中间4条数据;C分片存存test数据库,存储t1表有中的后3条数据;每个分片存储索引的结构都一样,存储数据不一样
ES-> 倒排索引(Inverted Index)
【类比目录思想:通过目录可以准确的找到对应的数据】
Eg:查询包含“搜索引擎”的文档
1)通过倒排索引获得“搜索引擎”对应的文档id列表,有1,3
2)通过正排索引查询1和3的完整内容
3)返回最终结果
倒排索引组成:单词词典+倒排列表
- 单词词典:常见数据结构:哈希加链表+树形结构
哈希表:每个哈希表保存一个指针,指针指向冲突链表,两个不同单词获得一个相同哈希值,就计为一次冲突,所以没来一个单词,会先获得哈希值,读取指针,再找到对应冲突链表,已存在,不保存,不存在,将其加入冲突链表中->构建词典结构
树形结构:要求数据有序,按数字或者字符
层级查找结构,中间节点指出一定顺序范围的词典存储在哪个子树中
- 容灾:
ES有很完善的容灾机制,候选master一般有多个,data节点也有多个,节点异常可以通过切换到其他节点来容灾

- ES官方查询语言:Query DSL,通过接入Elasticsearch-SQL插件,解析SQL转换成DSL语法,再通过DSL查询。
- ES,REST-API接入
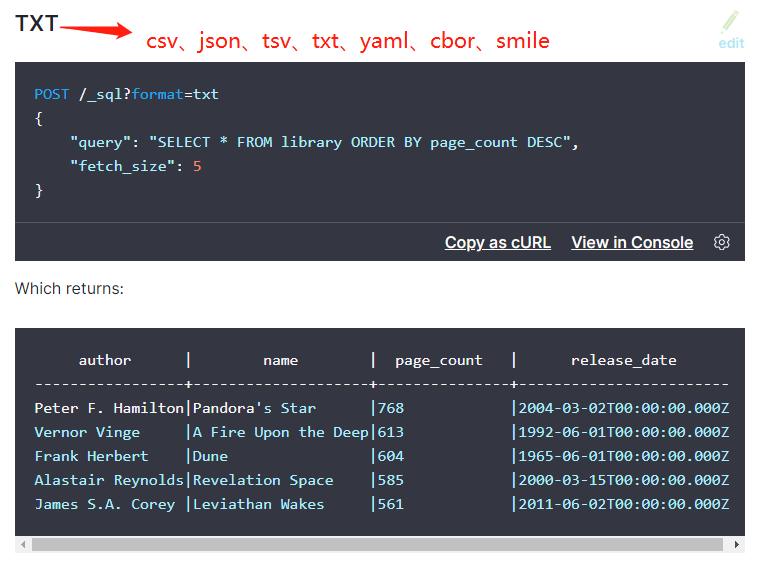
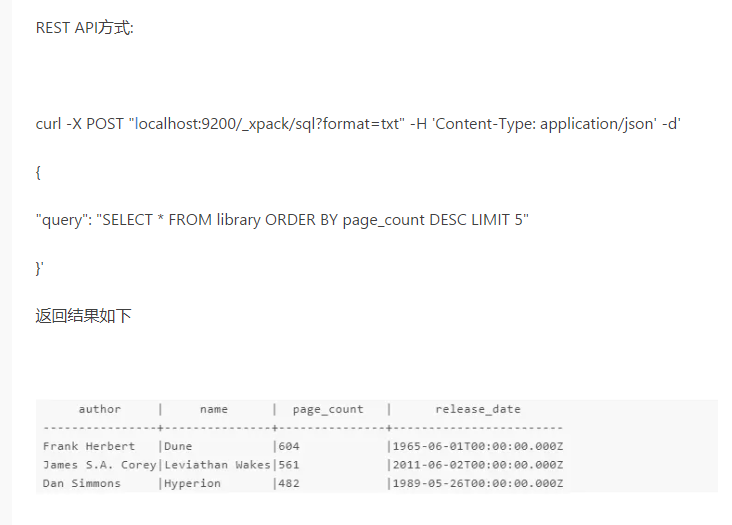
ES用Postman连接
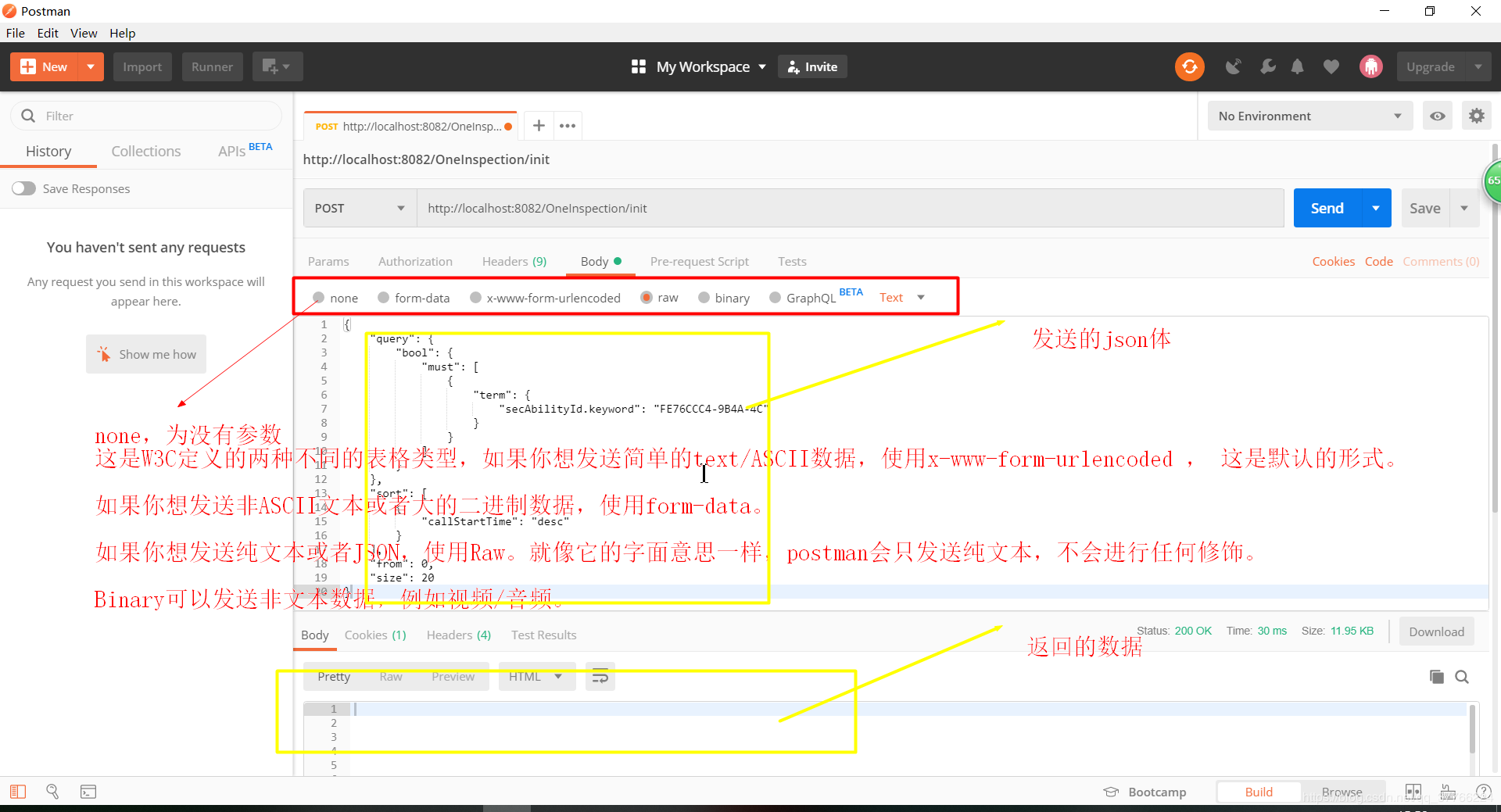
数据操作
创建索引
PUT /customer?pretty
PUT /people
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
},
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
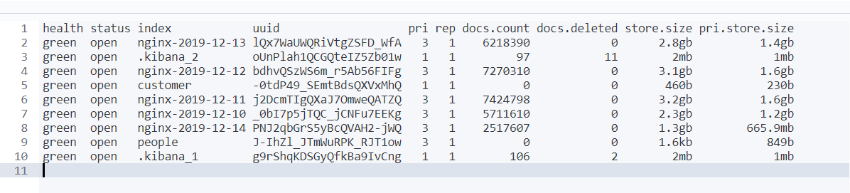
查询所有索引信息
GET /_cat/indices?v
插入指定ID文档(7.x,固定类型_doc)
PUT /customer/_doc/1?pretty
{
"name": "John Doe"
}
修改指定ID文档
PUT /customer/_doc/1?pretty
{
"name": "Hayder"
}
插入未指定ID文档
POST /customer/_doc
{
"name": "Hayder"
}
更新指定ID文档的值
POST /customer/_update/2
{
"doc": { "name": "aaaaa" }
}
更新指定ID文档的值并加新值
POST /customer/_update/1
{
"doc": { "name": "Hayder", "age": 20 }
}
简单函数:年龄+5
POST /customer/_update/1
{
"script" : "ctx._source.age += 5"
}
删除索引
DELETE /customer?pretty
删除指定ID文档
DELETE /customer/_doc/2?pretty
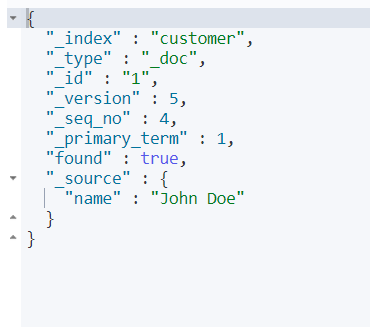
查询指定ID文档
GET /customer/_doc/1?pretty
批量插入指定ID文档
POST /customer/_doc/_bulk?pretty
{"index":{"_id":"11"}}
{"name": "test11" }
{"index":{"_id":"12"}}
{"name": "test12" }
更新ID11文档,删除ID12文档
POST /customer/_doc/_bulk?pretty
{"update":{"_id":"11"}}
{"doc": { "name": "test_update" } }
{"delete":{"_id":"12"}}
查询操作
全局搜索
GET /customer/_search
条件查询
GET /customer/_search?q=Hayder
GET /customer/_search?q=Hayder*
条件查询并根据指定列排序
GET /customer/_search?q=*&sort=age:desc&pretty
---------------------------------------------------
GET /customer/_search
{
"query": { "match_all": {} },
"sort": [
{ "age": "desc" }
]
}
只返回所查的字段
GET /customer/_search
{
"query":{
"match_all": {}},
"_source":["name","age"]
}
包含术语 (命中:zhu , hai , zhu hai)
GET /customer/_search
{
"query": {"match": {"name":"zhu hai"}}
}
包含短语 (命中: zhu hai)
GET /customer/_search
{
"query": {"match_phrase": {"name":"zhu hai"}}
}

查询mapping
GET /people/_mapping















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









