










文章目录
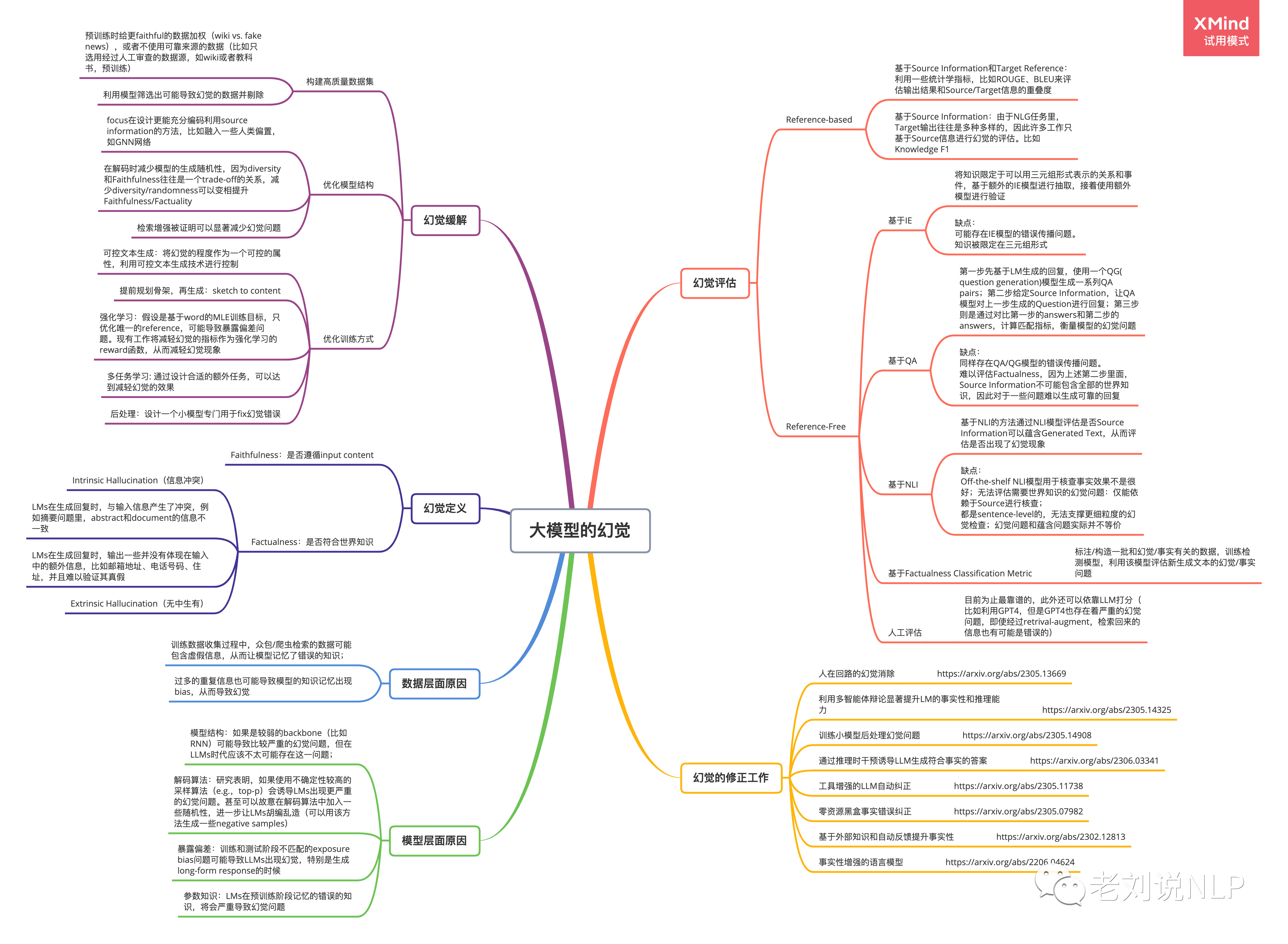
一、幻觉定义
备注(下面提及的两个名词):
- Faithfulness:是否遵循input content;
- Factualness:是否符合世界知识;
- 传统nlp任务重,幻觉大多数是faithfulness,比如Intrinsic Hallucination(冲突),摘要内容和document内容有冲突;再比如Extrinsic Hallucination(无中生有),生成内容中包含input要求的其他杂七杂八虚假信息;但LLM应该考虑的幻觉Factualness,因为数据源是Open-doman的世界知识
(1)幻觉问题:回答不准确、前后不一致等,生成内容并非基于训练数据或不符合事实。
(2)chatgpt工程师:
考虑到最大似然性目标,模型的这种选择是显而易见的,在这种情况下,模型不会太关注输出内容的正确与否,而是更看重听起来正确或看起来合理,因此,以简单方式训练出的模型常常会产生幻觉。通过微调和人类反馈,我们可以显著减少幻觉的输出,但无法完全消除。免费模型带有较多幻觉,基于GPT-4模型的幻觉输出较少,但仍偶尔出现,特别是当涉及模型未经训练、未察觉到的特定限制时。
二、幻觉的可控因素
- token限制
- 温度系数
- 训练预料不足
- 外挂知识库,索引topK
- 强化学习
二、幻觉的原因
1. 数据层面
- 数据源(source)不一致:
- 例如:摘要的数据源是document,data-to-text的数据源是data table,对话的数据源是对话历史,而开放域对话的数据源可以是世界知识。
- 容忍幻觉的程度不一致:
- 在摘要、data-to-text任务中,非常看重response的Faithfulness,因此这些任务对幻觉的容忍程度很低;
- 像开发域对话任务中,只需要response符合事实即可,容忍程度较高;
2. 模型层面
- 模型训练:
- 曝光偏差exposure bias:训练采用teacher-forcing基于ground-truth,测试基于模型生成的文本可能会积累生成误差
- 参数化知识偏差:LLM更更倾向于使用训练时存储在参数中的知识(可能出错),而非输入中包含的内容
- 参数知识:LMs在预训练阶段记忆的错误的知识,将会严重导致幻觉问题。
- Entitybased knowledge conflicts in question answering
- 模型:
- 不充分的表示学习:encoder语义理解如果不够好,错误学习数据表示会导致幻觉
- 不恰当的解码方式:decoer采用某些解码策略,如top-k采样
三、解决方法
1. 数据层面
- 人工标注
- GO FIGURE: A meta evaluation of factuality in summarization
- Evaluating factual consistency in knowledge-grounded dialogues via question generation and question answering
- 训练数据:LLM上不可行,只适用于task-specific的幻觉问题
- 评测数据:构建细粒度的幻觉评估benchmark用于分析幻觉问题
- 自动筛选:
- 利用模型打分,筛选出可能导致幻觉的数据并剔除;
- 预训练时给更faithful的数据加权(wiki vs. fake news),或者不使用可靠来源的数据(比如只选用经过人工审查的数据源,如wiki或者教科书,预训练)
- 加入一些强事实的数据,比如RefGPT数据集进行微调训练,参考:https://github.com/sufengniu/RefGPT
2. 模型层面
(1)模型结构
- 模型结构层面的工作往往focus在设计更能充分编码利用source information的方法,比如融入一些人类偏置,如GNN网络。
- 或者在解码时减少模型的生成随机性,因为diversity和Faithfulness往往是一个trade-off的关系,减少diversity/randomness可以变相提升Faithfulness/Factuality。
- 「检索增强」被证明可以显著减少幻觉问题,e.g., LLaMA-index。
(2)训练方式
- 可控文本生成:将幻觉的程度作为一个可控的属性,利用可控文本生成技术进行控制。
- Increasing faithfulness in knowledgegrounded dialogue with controllable features
- A controllable model of grounded response generation
- 提前规划骨架,再生成:sketch to content
- Data-to-text generation with content selection and planning
- 强化学习:假设是基于word的MLE训练目标,只优化唯一的reference,可能导致暴露偏差问题。现有工作将减轻幻觉的指标作为强化学习的reward函数,从而减轻幻觉现象。
- Slot-consistent NLG for task-oriented dialogue systems with iterative rectification network
- Improving factual consistency between a response and persona facts
- 多任务学习: 通过设计合适的额外任务,可以达到减轻幻觉的效果。
- 后处理:设计小模型专门用于fix掉幻觉错误。
- Improving faithfulness in abstractive summarization with contrast candidate generation and selection
3. pretrain、sft、rlhf、inference
缓解幻觉的方法:如下图,从pretrain、sft、rlhf、inference等分别入手,下图源自论文《A Survey on Hallucination in Large Language Models》
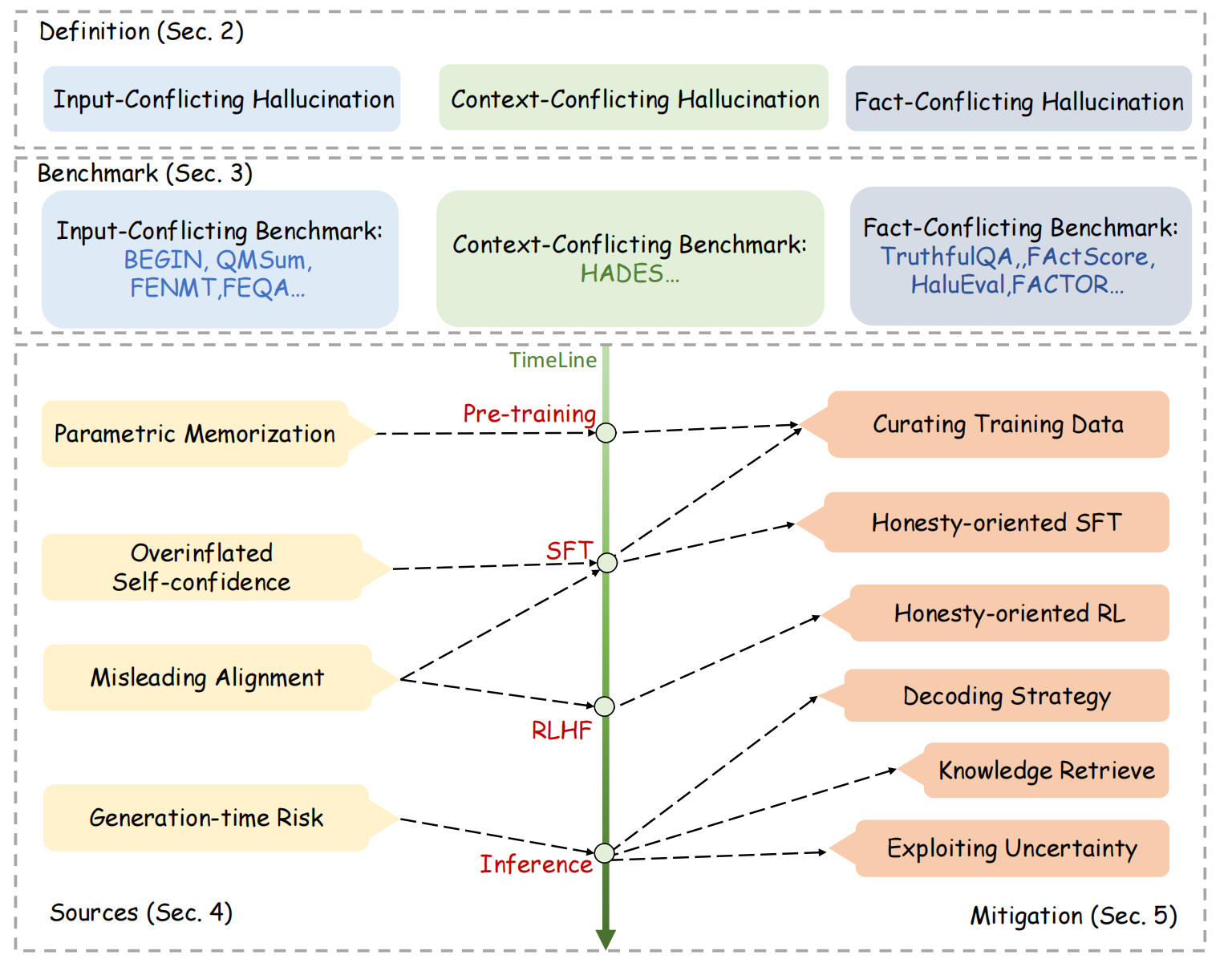
(1)pretrain
GPT-3的预训练数据就是通过与一系列高质量参考数据的相似性进行清理。
Falcon通过启发式规则从网络中仔细提取高质量数据,并证明了经过适当分级的相关语料库可以产生强大的LLM。为了减少幻觉,目前的LLM通常会从可靠的文本来源收集预训练数据。
Llama2在构建预训练语料库时,从维基百科等高度事实性的来源中向上抽取数据
(2)sft
- sft:sft中加入诚实样本,诚实样本指的是承认自己无能的回答,如"对不起,我不知道"。【也就是我们常说的拒答】,这块可以看看Moss项目开源的SFT数据,其中就包括此类诚实样本。
- 像alpaca使用self-instruct构造sft数据时,没有太多人工检查,有引入一些幻觉问答,即强迫大模型回答超过LLM知识边界的问题,所以可以加入诚实样本
(3)rl
- RLHF:GPT4使用合成幻觉数据来训练奖励模型并执行RL,从而将Truth-fulQA的准确率从约30%提高到60%。
- RL可以引导LLM探索知识边界,难点是防止RL调整后的LLM过于保守
(4)inference
- 设计解码策略
- 借助外部知识:如从外部知识库(如大规模非结构化语料库、结构化数据库、维基百科等),或者通过外部工具,如FacTool用于代码生成的代码执行器和用于科学文献审查的谷歌学术API,检测幻觉后响应修改
在封神榜的姜子牙写作模型(https://huggingface.co/IDEA-CCNL/Ziya-Writing-LLaMa-13B-v1)中,建议的解码参数如下:
- temperature:0.85,温度系数越大则文本越多样化
- do_sample:是否使用采样方法,如果为True则使用采样方法,如果为False则使用Greedy Search,后者是生成模型会选择每一步最有可能的标记作为生成的下一个标记,而不考虑其他可能的选择,可能会导致生成重复词语等,缺乏多样性
- top_p:用于采样的一个概率阈值。在采样过程中,会筛选掉累计概率超过 top_p 的标记,比如0.1 意味着模型解码器只考虑从前 10% 的概率的候选集中取tokens
- repetition_penalty:一个惩罚系数,用于抑制重复生成相同标记的倾向。较高的惩罚系数将更强烈地抑制重复
- eos_token_id:表示终止生成的特殊标记的ID。当生成的文本中出现这个标记时,生成过程会停止。
- bos_token_id:表示生成文本起始的特殊标记的ID。
- pad_token_id:表示填充标记的特殊标记的ID。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
device = torch.device("cuda")
query="帮我写一份去西安的旅游计划"
model = AutoModelForCausalLM.from_pretrained("IDEA-CCNL/Ziya-Writing-LLaMa-13B-v1", torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("IDEA-CCNL/Ziya-Writing-LLaMa-13B-v1", use_fast=False)
inputs = ': ' + query.strip() + '\n:'
# 对输入进行分词和编码
input_ids = tokenizer(inputs, return_tensors="pt").input_ids.to(device)
generate_ids = model.generate(
input_ids,
max_new_tokens=2048,
do_sample = True,
top_p = 0.85,
temperature = 0.85,
repetition_penalty=1.,
eos_token_id=2,
bos_token_id=1,
pad_token_id=0)
# 对生成文本进行解码
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
(5)多代理互动
多个LLM(agent)独立提出建议,进行协作辩论,达成单一共识。

四、幻觉的评估基准
TruthfulQA:https://aclanthology.org/2022.acl-long.229/
TruthfulQA介绍:一个很重要的用于评估LLM是否能够生成符合事实的答案的QA基准,被后续的LLM工作,如GPT4采用评估。包含了817个作者手写的问题,这些问题是精心设计,往往是模型或者人类都很容易回答错误的陈述。作者发现:
- 与人类相比(94%),当前较好的LLMs(GPT3)也只能诚实地回答58%的问题而不进行编造。
- 更大的模型更容易编造回答。
- 微调后的GPT3可以有效分辨是否回答是truthful的。
Reference
[1] 大模型中的幻觉性问题.thu知识工程实验室
[2] 大模型幻觉问题调研.李rumor
[3] 大型语言模型LLM中的幻觉研究综述(一)
[4] 减轻及避免大模型LLM幻觉(二)
[5] 大模型生成幻觉研究综述:大模型幻觉的起因、评估以及减轻策略总结.老刘说NLP
[6] DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
[7] 大模型幻觉缓解前沿方案DoLa:通过对比层解码缓解大模型幻觉工作介绍.老刘说NLP
[8] A Survey on Hallucination in Large Language Models:https://arxiv.org/abs/2309.01219
[9] 论文解读:Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models
[10] https://github.com/sufengniu/RefGPT
[11] 也看大模型幻觉的脑图总结:详解RefGPT事实性数据集、KoLA知识图谱大模型评测及HaluEval幻觉评估实现


















 3415
3415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











