







《Machine Learning Yearning》
建立baseline控制在一周以内
数据集
1、传统机器学习中一般采用train/test set按照70%/30%划分,但是在大规模数据集的深度学习中,不需要按照这个比例,test比例可以更低一些。
2、确保train和test数据集是属于同分布的,如果实在找不到与test数据集相同分布的train set,可以采用分布不同的train,但是这很有可能导致在test上泛化不好,通常的做法可以是把test中一部分拿出来,在train set训练后做fine tune。
3、一般1000到10000 examples用来做dev set (val set)比较常见,对于100到10000 example的数据集,一般30%用来做test set比较常见,对于规模很大的数据集,比例一般在减少。
评估
1、建立一个single-number的metric,例如准确度,或者将precision和recall计算为F1-score, 公式如下:
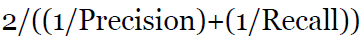
2、Optimizing and satisficing metrics:有时候有一些metric没法合并为一个有实际物理意义的single metric,例如准确度和运行时间,这个时候需要把其它metric定义为satisficing metrics(例如,运行时间),accuracy定义为要优化的metric。例如我们必须要规定infernece在200 ms内,那就需要在200 ms选择方法,比较或者优化accuracy。
错误分析
1、将错分的图片人工检查,并定义一些错误类。在识别猫任务中,比如图片模糊,误将狗识别为猫,误将大猫(狮子,豹子等)识别为猫、猫有物体遮挡等,看一下哪些问题占比重较大,从而确定解决问题的优先级。
2、错标注是否修改?当misclassifacation中错误标注比例较大,比如20%,需要修改,而比例较小的时候,比如5%可能就不需要修改,一些研究也表明,当标签有适度的噪声通常不会过于影响模型性能,且有助于增加模型泛化能力。
3、当dev set很大时,可以均分为两个,因为一般情况下对dev set做错误分析并提高效果,本质上可能是对dev set的overfit,这时可以用另一半来调整参数。可以用人眼看并进行错误分析的称为Eyeball dev set,剩下的sev set的部分称为Blackbox dev set。一般我们需要有100个mistakes才能感受到一些sense,所以Eyeball dev set的大小一般为100/ error rate,对于一些人在经过一定训练前很难感受的任务,比如推荐、医学图像等,可能不需要Eyeball dev set。对于dev set比较小的情况,且error rate也比较小,可能没有剩余sev set用来做Blackbox dev set,这个时候就不用Blackbox dev set。
Bias & Variance
这里的bias和variance不是统计学上的概念,而是针对train set和dev set error rate的定义
1、定义:bias的定义为train set的error rate, variance定义为dev error rate - train error rate。low bias + high variance定义为overfitting, high bias + low variance定义为underfitting。high bias + high variance既有overfitting又有underfitting,这个目前不太理解,之前觉得要么overfitting要么underfitting。
2、bias又分为avoidable和unvoidable两种,这个时候需要和human performance做一些比较。例如,对于一个train set,让一个正常人来做分类的accuracy是90%,也就是10%的error rate。如果一个模型train error rate为15%,那么avoidable bias = 5%, unvoidable bias = 10%。 variance仍为dev error rate - train error rate。
3、降低bias或variance方法:一般bias和variance是有一个balance,也就是“此消彼长”(除去大刀阔斧的改变网络结构可以同时降低)。降低bias方法:增加模型大小,根据错误分析增加特征,减少正则或者直接去掉,一般这些方法都会增加variance,可以通过加正则来适当缓解。增加训练数据可能既不能降低bias,一般能够降低variance。降低varicace方法:增加训练数据,early stop, 特征选择(small train set,DL一般不用),减少模型大小,这些方法一般都会增加bias。
4、学习曲线可以辅助分析:

我们可以用不同size的train set来画出 dev/training error curve,如上图所示,这样我们可以很确定的知道,desired performance无法达到,因为training error (bias) 是随着set size增加而增加的,而一般training error会永远在dev error下方。
train set和test set不同分布
1、将test set一部分重新划分为dev set和test set,剩下的加入给train set
2、有些情况,需要把不一致的数据替换,例如网站的猫和手机app获取的猫图片输入不同分布,但是都是猫,识别任务也是猫,就不要剔除;而预测纽约房价,就应该把别的城市的数据替换掉。
3、当数据类别分布不均衡时,可以通过weight data来缓解,即在loss上面对不同类的数据的loss加不同weight。
4、data mismatch:当train set和test set分布不同时,对于问题的分析可能更为复杂,这个时候可能有三种情况:bias,variance,data mismatch,我们需要确定是哪方面的问题。这个时候需要引入一个training dev set,这个与training set的分布是一致的。下面给出三个例子:
high variance

high bias

high bias + data mismatch

5、当没有办法得到足够多的match的train data时,可以采用noise进行一些数据合成,得到一些和dev/test set尽可能相似的合成数据(例如口罩人脸识别)
Optimization Verification test
以强化学习为例,我们在做inference时候,通常包含两步:第一步对不同状态打分出一个score,然后再通过search算法找到最优状态并转到这个状态。那我们就可以借鉴这个进行debug。首先对于两个状态,人可以给出谁好谁坏的评价,然后通过算法出的score是否也是这样,如果是,则问题出在search algorithm,如果不是,score calculation有问题。
End to end DL
要想分析哪个component出了问题,需要这个component的output和人标注的结果同时输送给下游components,如果结果都很差,是下游中components出现了问题,如果这个component的output结果差,人标注的结果符合预期,则是这个component出了问题。















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









