







1、SRCNN在干什么
1、将高分辨率(HR)图像经过多次插值转换为低分辨率(LR)图像.
2、将LR送入NN进行特征提取、转换、重构图像
3、将重构的超分辨率图像与HR做对比判断效果好坏
2、SRCNN评判标准
1、MSE(均方根误差)作为损失计算值
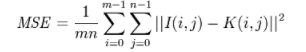
2、峰值信噪比PSNR作为图像重构质量的判断
![]()
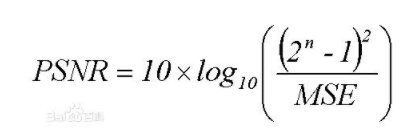
PSNR>40dB说明图像质量极好(即非常接近原始图像),
30到40dB通常表示图像质量是好的(即失真可以察觉但可以接受),
20到30dB说明图像质量差;
PSNR低于20dB图像不可接受
3、SSIM 结构相似性 利用像素值差异进行判断

3、说说代码几个关键细节
1、prepare.py
增加default=False 便于控制训练集和测试集h5文件的生成
parser.add_argument('--eval', action='store_true', default=False) if not args.eval:
train(args)
print("OK1")
else:
eval(args)
print("OK2")这里是在对数据集进行截取、使相同尺寸的LR HR 获取多个对应的33x33的区域快 用于训练学习
2、train.py test.py models.py dataset.py utils.py
models.py dataset.py utils.py 比较简单没有值得强调的地方
当你用完train.py 训练完模型,基线代码中只有高清图像所以进行测试时还是要进行双三次插值降低分辨率并进行重构、但是实际应用中我们是低分辨率重构、如果有高分辨率图像就没必要多此一举了。所以当你要把自己的低分辨率数据重构为SR时不要在进行插值降低分辨率。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









