







译文:https://www.jianshu.com/p/f71ba99157c7
文中将identity mapping翻译为自身映射,个人认为翻译为恒等映射更准确,即
f
(
x
)
=
x
f(x)=x
f(x)=x。
ResNet,残差网络。
在叠加网络深度的时候,会暴露出退化问题:随着神经网络深度的增加,准确度趋近于饱和,然后迅速下降。这种退化问题并不是过拟合导致的。
作者提出了一个猜想:从一个训练好的浅层网络中,插入一些恒等变换层。即插入的层不改变输入,输出等于输入。

如图中下面的网络结构其实是上面网络结构加了最后一层,如果这个最后一层不改变输入,那么这两个网络其实是等价的。也就是说下面这个更深的网络的训练误差不会高于上面的浅层网络。
但实际上很难让机器学习到这样的一个恒等映射层。因此作者提出了残差学习框架。假设 H ( x ) H(x) H(x)是最优解函数,想要让 H ( x ) H(x) H(x)是一个恒等映射,即 H ( x ) = x H(x)=x H(x)=x。改为残差网络结构后,就变成了 H ( x ) = f ( x ) + x = x H(x)=f(x)+x=x H(x)=f(x)+x=x,即 f ( x ) = 0 f(x)=0 f(x)=0,只要让残差函数 f ( x ) f(x) f(x)是一个零映射,就可以实现让 H ( x ) H(x) H(x)是一个恒等映射。而让机器学习到零映射比让机器学习到恒等映射要简单的多。
于是作者提出了这样的网络结构

f
(
x
)
+
x
f(x)+x
f(x)+x用一个shortcut实现,跳过一层或多层,将输入与输出叠加。这个shortcut既不会添加额外的参数,也不会增加计算复杂度。
这样的结构与“Highway Network”有些相似,但“Highway Network”的shortcut是有门控制的,这个门函数是数据相关的并且参数需要调整。如果门函数为0则shortcut无法使用,也就不再是残差结构。“Highway Network”并没有呈现出精度随深度增加而增加的特性。
将上述公式化表示,得到
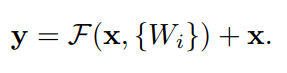
其中
F
(
x
,
W
i
)
F(x,{W_i})
F(x,Wi)表示将被训练的残差映射,
W
i
W_i
Wi表示参数。该公式要求输入x和残差函数F的维度必须一致。如果不一致,可以在shortcut上增加一个线性投影
W
s
W_s
Ws来匹配维度
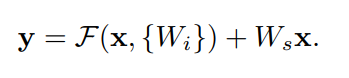
残差函数F即可以表示全连接层,也可以表示卷积层。同时,F可以表示一层或多层,但在表示一层时,函数F退化为参数矩阵
W
i
W_i
Wi,公式退化为
y
=
W
i
x
+
x
y=W_ix+x
y=Wix+x。作者并没有观察到这个公式具有任何优势。















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









