







1. 引言
作者提出一种弱监督的图像分割算法,只需要少量的潦草的人工注释就可以达到高精确度和鲁棒性。该方法与传统的潦草注释学习算法一样使用潦草注释,但是他们将pseudo-labeling和label-filtering结合。
该方法引入了一种新的迭代的图像分割网络的训练过程,该过程通过弱监督,自动地生成训练注释,从而只需要一小部分的人工注释。
该方法提出了一种新的思想,将pseudo-labeling和label-filtering结合,利用一致性来生成可靠的训练注释。
该方法与现有的scribble监督的图像分割方法不同,该方法是一种端到端方案,不需要使用任何额外的模型参数或外部分割方法。

2. 实现
对于标注了的像素,使用一个标准的交叉熵。对于未标注的像素,建立的神经网络会使用训练期间预测的指数移动平均值来自动生成可靠的标注。
模型的训练分为两部分。第一部分是初始化,或称为热身阶段,只使用标注像素进行训练。第二部分同时使用标注和未标注的像素,迭代地优化预测结果。
2.1 热身阶段
不使用未标注的像素,使用如下的交叉熵进行训练
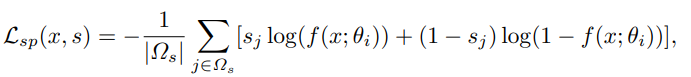
其中
x
x
x表示输入图像,
s
s
s表示一个标注,
Ω
s
\Omega_s
Ωs是标注的像素集合,
f
(
x
;
θ
i
)
f(x;\theta_i)
f(x;θi)是模型在第
i
i
i次迭代的预测值。
同时,定期计算训练过程中预测值的指数移动值exponential moving average (EMA)
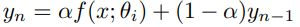
其中
α
\alpha
α是EMA的权值,
y
y
y是预测值的平均值,
y
0
=
f
(
x
;
θ
1
)
y_0=f(x;\theta_1)
y0=f(x;θ1),
n
n
n是预测值被计算平均值的次数。这个过程被称为预测值集合prediction ensemble。
由于训练的过程中使用了数据增强(旋转、翻转、水平位移等)data augmentation,因此对于相同的输入图像,分割的预测会不一样。为了解决这个问题,将训练过程分为训练部分和集成部分。在集成部分,使用未增强的图像un-augmented image作为输入,并且对其预测结果使用EMA。为了减少计算代价,每 γ \gamma γ个预测结果,计算一次预测值的平均。
2.2 用自生成的伪标注进行学习Learning with a Self-generated Pseudo-Label
将具有相同结果的像素进行one-hot编码,并作为无标注的像素的标注。通过熵最小化,仅使用可靠的像素并将这些像素逐渐地one-hot编码。未标注的像素的损失如下定义
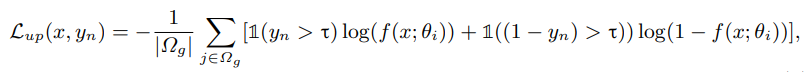
其中
Ω
g
\Omega_g
Ωg是生成的标注像素集合,
τ
\tau
τ是一致性的阈值。
总损失函数就是两个损失函数的权值相加
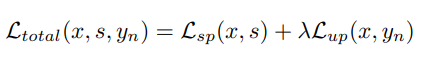
















 3692
3692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









