







 本文详细介绍使用Python从零开始制作词云图的过程,包括环境搭建、依赖安装及具体实现步骤。
本文详细介绍使用Python从零开始制作词云图的过程,包括环境搭建、依赖安装及具体实现步骤。
临渊羡鱼,不如退而结网。我们步步为营,从头开始帮助你用Python做出第一张词云图来。欢迎尝试哦!

需求
在大数据时代,你经常可以在媒体或者网站上看到一些非常漂亮的信息图。
例如这个样子。

或是这个样子的。

看过之后你有什么感觉?想不想自己做一张出来?
如果你的答案是肯定的,我们就不要拖延了,今天就来一步步从零开始做个词云分析图。当然,做为基础的词云图,肯定比不上刚才那两张信息图酷炫。不过不要紧,好的开始是成功的一半嘛。食髓知味,后面你就可以自己升级技能,进入你开挂的成功之路。
网上教你做信息图的教程很多。许多都是利用了专用工具。这些工具好是好,便捷而强大。只是它们功能都太过专一,适用范围有限。今天我们要尝试的,是用通用的编程语言python来做词云。
Python是一种时下很流行的编程语言。你不仅可以用它做数据分析和可视化,还能用来做网站、爬取数据、做数学题、写脚本替你偷懒……
知道豆瓣吗?它一开始就是用Python写的。
在目前的编程语言热度排序里,Python屈居第四(当然,很多人不同意,所以编程语言的排行榜有许多,你懂的)。但看问题要用发展眼光。随着数据科学的发展,Python有爆发的趋势。早点儿站上风口,很有益处。
如果你之前没有编程基础,没关系。从零开始,意味着我会教你如何安装Python运行环境,一步步完成词云图。希望你不要限于浏览,而是亲自动手尝试一番。到完成的那一步,你不仅可以做出第一张词云图,而且这还将是你的第一个有用的编程作品。
心动了?那咱们就开始吧。
效果展示:

笔者为了实现这玩意可是鼓捣了一天(哈哈!已笑哭,这么菜)
那么笔者(python 小白)就把这填坑之路细细道来
首先我们需要搭建环境 python + pip (只需要看这两个就行)
第一个坑
一. 现象 && 原因
出现如下 Error :
ImportError: No module named 'pysqlite2'
查看出错代码时,有下面的信息:
File "$/venv/lib/python3.5/site-packages/sqlalchemy/dialects/sqlite/pysqlite.py"
, line 334, in dbapi
from pysqlite2 import dbapi2 as sqlite 问题原因,可能为 无法打开 pysqlite2 库,因使用 Python3.5 作为开发环境, Python 3.5 默认使用 sqlite3,且可以替代pysqlite2 。
stackoverflow 上,有人建议使用sqlite3 替换pysqlite2,详见这里 。
展开出错位置代码如下:
@classmethod
def dbapi(cls):
try:
from pysqlite2 import dbapi2 as sqlite
except ImportError as e:
try:
from sqlite3 import dbapi2 as sqlite # try 2.5+ stdlib name.
except ImportError:
raise e 这里已经对不同版本使用 sqlite做出了处理。所以该问题并不是上述问题产生。
进入 Python3 交互环境后:
import sqlite3
会出现 Error.
原因是编译安装 Python3 时,缺少 sqlite3 依赖。
yum install sqlite-devel (先安装这玩意 不然python都要重新装)
如果使用tkinter 需要安装
yum install tcl-devel
yum install tk_devel
重新编译安装 Python3 后问题得到解决。
安装python3.5 和pip 安装链接
笔者环境是将安装好的 /usr/local/python/python3/bin/ pip3 以及 python3 已软链接的方式连接到 /usr/bin 目录下
命令 : ln -s /usr/local/python/python3/bin/pip3 /usr/bin/pip
ln -s /usr/local/python/python3/bin/python3 /usr/bin/python (可以先进入/usr/bin 执行命令 ll python* 看到 python -> python2 可以将 这个删除 rm -rf python)
这时 python -V 就是 3.5版本
之后可以升级pip
命令 : pip install --upgrade pip(按照博客的顺序走)
升级完成之后安装
2、安装jupyter
pip install jupyter(这是安装) *** (pip卸载 pip uninstall PackageName 补充知识点)
ln -s /usr/local/python/python3/bin/jupyter /usr/bin/jupyter
3、安装 wordcloud
pip install wordcloud
4、在cd /usr/local/nginx/html/
mkdir ciyun
也可以安装(scripy *pip install scripy*)
也可以安装(jieba *pip install jieba* 中文分词)
数据
词云分析的对象,是文本。
理论上讲,文本可以是各种语言的。英文、中文、法文、阿拉伯文……
为了简便,我们这里以英文文本为例。你可以随意到网上找一篇英文文章作为分析对象。我特别喜欢英剧"Yes, minister",所以到维基百科上找到了这部剧的介绍词条。
我把其中的正文文字部分拷贝了下来,存储为一个文本文件,叫做yes-minister.txt。
把这个文件挪动到我们的工作目录demo里。
好了,文本数据已经准备好了。开始进入编程的魔幻世界吧!
运行 jupyter notebook --por=8888
第二大坑!!!
地址问题
笔者 jupyter notebook 怎么也不成功!!!
提示笔者 address 有问题
此时直接上大招 远程连接jupyter (笔者是linux 阿里云线上 不是虚拟机)
1、jupyter notebook --generate-config (生成jupyter配置文件)
2、 生成密码 这一步其实用不到,因为不建议使用密码登录,修改配置文件的时候密码建议屏蔽
打开ipython,创建一个密文的密码:
In [1]: from notebook.auth import passwd
In [2]: passwd()
Enter password:
Verify password:
Out[2]: 'sha1:86346e4cdf7a:c57960216df752e8ee5d3b9b8de6941640e15273'
把密文复制下来
'sha1:86346e4cdf7a:c57960216df752e8ee5d3b9b8de6941640e15273'
3 修改配置文件
$ vim ~/.jupyter/jupyter_notebook_config.py
进行如下修改:
c.NotebookApp.ip='*'
#c.NotebookApp.password = u'sha1:86346e4cdf7a:c57960216df752e8ee5d3b9b8de6941640e15273' (自己使用可以不使用密码笔者这里注释掉了)
c.NotebookApp.open_browser = False
c.NotebookApp.port =8888 #随便指定一个端口,使用默认8888也可以
个人建议:屏蔽掉密码那一行,如果不是服务器安装,而只是自己的虚拟机,自己用的虚拟机不需要安全设置
4,启动jupyter notebook
5,远程访问服务器 浏览器建议使用火狐,虚拟机下Linux里默认安装的是火狐浏览器
http://远程服务器ip:8888
6,如果登陆失败,则有可能是服务器防火墙设置的问题,此时最简单的方法是在本地建立一个ssh通道:
在本地终端中输入ssh username@address_of_remote -L127.0.0.1:1234:127.0.0.1:8888
便可以在localhost:1234直接访问远程的jupyter了。 username 一般为root
如果需要可以关闭防火墙,或者iptables -i INPUT -j ACCEPT,
在INPUT链前面加全通策略。
以上只是理想状态 笔者之后又遇到问题 报错大致意思为:不能以root 用户去启动
*************************************
下面开始建立新的用户 ( 新建用户并授权!!!)
1、添加用户
首先用adduser命令添加一个普通用户,命令如下:
#adduser tommy //添加一个名为tommy的用户
#passwd tommy //修改密码
Changing password for user tommy.
New UNIX password: //在这里输入新密码
Retype new UNIX password: //再次输入新密码
passwd: all authentication tokens updated successfully.
2、赋予root权限
方法一:修改 /etc/sudoers 文件,找到下面一行,把前面的注释(#)去掉
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
然后修改用户,使其属于root组(wheel),命令如下:
#usermod -g root tommy
修改完毕,现在可以用tommy帐号登录,然后用命令 su - ,即可获得root权限进行操作。
方法二:修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
tommy ALL=(ALL) ALL
修改完毕,现在可以用tommy帐号登录,然后用命令 su - ,即可获得root权限进行操作。
切换用户后
输入命令 : jupyter notebook --port 8888
笔者以为 这下大功告成 但是出现了最大坑!!!!
天坑!!!
jupyter 启动报错 Permission denied: '/run/user/0/jupyter'
大致报错
解决办法
输入命令:
jupyter --path
显示以下:
看着样子好像是修改 runtime 的设置就可以了
export XDG_RUNTIME_DIR="/home/haiyong/.jupyter" (我新建立的用户haiyong)
环境变量配置(上面的只是临时作用)
********************************************************************************************************************************************
$PATH:决定了shell将到哪些目录中寻找命令或程序,PATH的值是一系列目录,当您运行一个程序时,linux在这些目录下进行搜寻编译链接。
编辑你的 PATH 声明,其格式为:
PATH=$PATH:<PATH 1>:<PATH 2>:<PATH 3>:------:<PATH N>
你可以自己加上指定的路径,中间用冒号隔开。环境变量更改后,在用户下次登陆时生效,如果想立刻生效,则可执行下面的语句:$ source .bash_profile
需要注意的是,最好不要把当前路径 “./” 放到 PATH 里,这样可能会受到意想不到的攻击。完成后,可以通过 $ echo $PATH 查看当前的搜索路径。这样定制后,就可以避免频繁的启动位于 shell 搜索的路径之外的程序了。
1. 可用 export 命令查看PATH值
[root@localhost u-boot-sh4]# export
declare -x CVS_RSH="ssh"
declare -x DISPLAY=":0.0"
declare -x G_BROKEN_FILENAMES="1"
declare -x HISTSIZE="1000"
declare -x HOME="/root"
declare -x HOSTNAME="localhost"
declare -x INPUTRC="/etc/inputrc"
declare -x LANG="zh_CN.UTF-8"
declare -x LESSOPEN="|/usr/bin/lesspipe.sh %s"
declare -x LOGNAME="root"
declare -x LS_COLORS="no=00:fi=00:di=00;34:ln=00;36:pi=40;33:so=00;35:bd=40;33;01:cd=40;33;01:or=01;05;37;41:mi=01;05;37;41:ex=00;32:*.cmd=00;32:*.exe=00;32:*.com=00;32:*.btm=00;32:*.bat=00;32:*.sh=00;32:*.csh=00;32:*.tar=00;31:*.tgz=00;31:*.arj=00;31:*.taz=00;31:*.lzh=00;31:*.zip=00;31:*.z=00;31:*.Z=00;31:*.gz=00;31:*.bz2=00;31:*.bz=00;31:*.tz=00;31:*.rpm=00;31:*.cpio=00;31:*.jpg=00;35:*.gif=00;35:*.bmp=00;35:*.xbm=00;35:*.xpm=00;35:*.png=00;35:*.tif=00;35:"
declare -x MAIL="/var/spool/mail/root"
declare -x OLDPWD="/root"
declare -x PATH="/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin"
declare -x PWD="/opt/STM/STLinux-2.3/devkit/sources/u-boot/u-boot-sh4"
declare -x SHELL="/bin/bash"
declare -x SHLVL="1"
declare -x SSH_ASKPASS="/usr/libexec/openssh/gnome-ssh-askpass"
declare -x TERM="xterm"
declare -x USER="root"
declare -x XAUTHORITY="/root/.xauthkSzH7b"
2. 单独查看PATH环境变量,可用:
[root@localhost u-boot-sh4]#echo $PATH
/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
3. 添加PATH环境变量(临时),可用:
[root@localhost u-boot-sh4]#export PATH=/opt/STM/STLinux-2.3/devkit/sh4/bin:$PATH
再次查看:
[root@localhost u-boot-sh4]# echo $PATH
/opt/STM/STLinux-2.3/devkit/sh4/bin:/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
说明添加PATH成功。
上述方法的PATH 在终端关闭 后就会消失。
4. 永久添加环境变量(影响当前用户)
#vim ~/.bashrc
export PATH="/opt/STM/STLinux-2.3/devkit/sh4/bin:$PATH"
5.永久添加环境变量(影响所有用户)
# vim /etc/profile
在文档最后,添加:
export PATH="/opt/STM/STLinux-2.3/devkit/sh4/bin:$PATH"
保存,退出,然后运行:
#source /etc/profile
不报错则成功。
问题:
1. 做了各实验,在/etc/profile, ~/.profile, ~/.bashrc中加入新PATH,重启都没有效果,只有使用source才可以,ubunt12.04
找到原因,~/.zshrc导致的,因为在zshrc中直接对PATH重新赋值,而没有继承之前的$PATH,导致启动加载完/etc/profile后,PATH又被重新赋值。
*****************************************************************************************************************************************************************+
此时再次启动
进入 目录页 /usr/local/nginx/html/ciyun/
jupyter notebook --port 8888
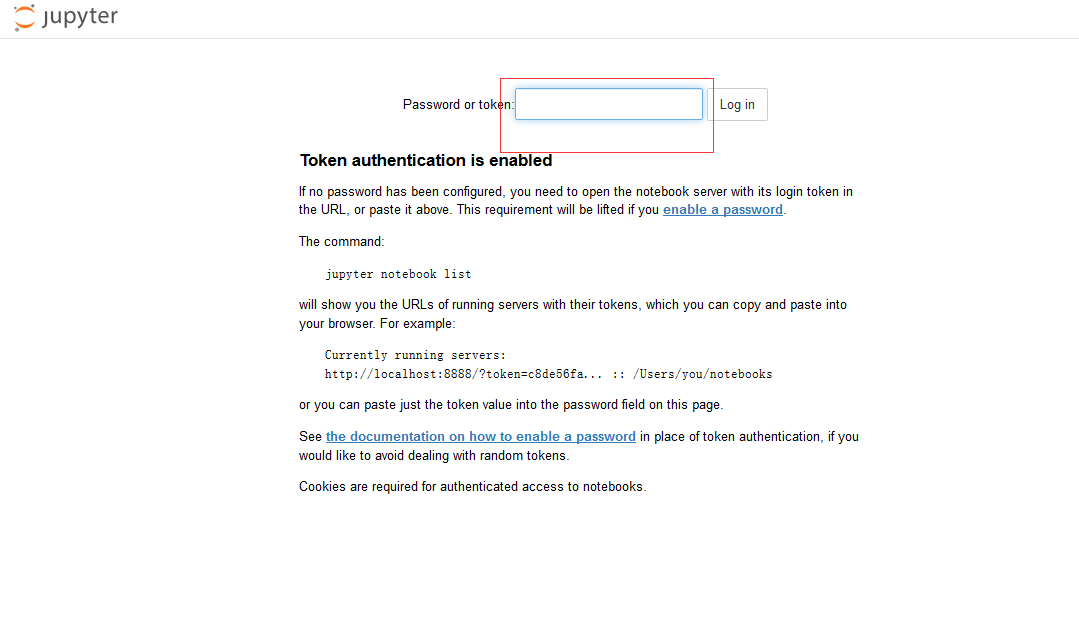
查看linux

将token 值 当密码登录
浏览器会自动开启,并且显示如下界面。
这就是咱们刚才的劳动成果——安装好的运行环境了。我们还没有编写程序,目录下只有一个刚才生成的文本文件。
打开这个文件,浏览一下内容。

回到Jupyter笔记本的主页面。我们点击New按钮,新建一个笔记本(Notebook)。在Notebooks里面,请选择Python 3选项。 (笔者这里是只有python3)
系统会提示我们输入Notebook的名称。程序代码文件的名称,你可以随便起。但是我建议你起一个有意义的名字,将来好方便查找。由于我们要尝试词云,就叫它wordcloud好了。

然后就出现了一个空白的笔记本,供我们使用了。我们在网页里唯一的代码文本框里,输入以下3条语句。请务必逐字根据示例代码输入,空格数量都不可以有差别。尤其注意第三行,用4个空格,或者1个Tab开始。输入后,按Shift+Enter键,就可以执行了。
filename = "yes-minister.txt"
with open(filename) as f:
mytext = f.read()没有任何结果啊。
对,因为我们这里没有任何输出动作,程序只是打开了你的yes-minister.txt文本文件,把里面的内容都读了出来,存储到了一个叫做mytext的变量里面。
然后我们尝试显示mytext的内容。输入以下语句之后,还是得按Shift+Enter键,系统才会实际执行该语句。
mytext之后的步骤里,也千万不要忘了这一确认执行动作。
显示的结果如下图所示。

嗯,看来mytext变量里存储的文本就是我们从网上摘来的文字。到目前为止,一切正常。
然后我们呼唤(import)词云包,利用mytext中存储的文本内容来制造词云。
from wordcloud import WordCloud
wordcloud = WordCloud().generate(mytext)这时程序可能会报警。别担心。警告(warning)不影响程序的正常运行。

此时词云分析已经完成了。你没看错,制作词云的核心步骤只需要这2行语句,而且第一条还只是从扩展包里找外援。但是程序并不会给我们显示任何东西。
说好了的词云呢?折腾了这么半天,却啥也没有,你蒙人吗?!
别激动。输入下面4行语句后,就是见证奇迹发生的时刻了。
%pylab inline
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")运行结果如图所示:
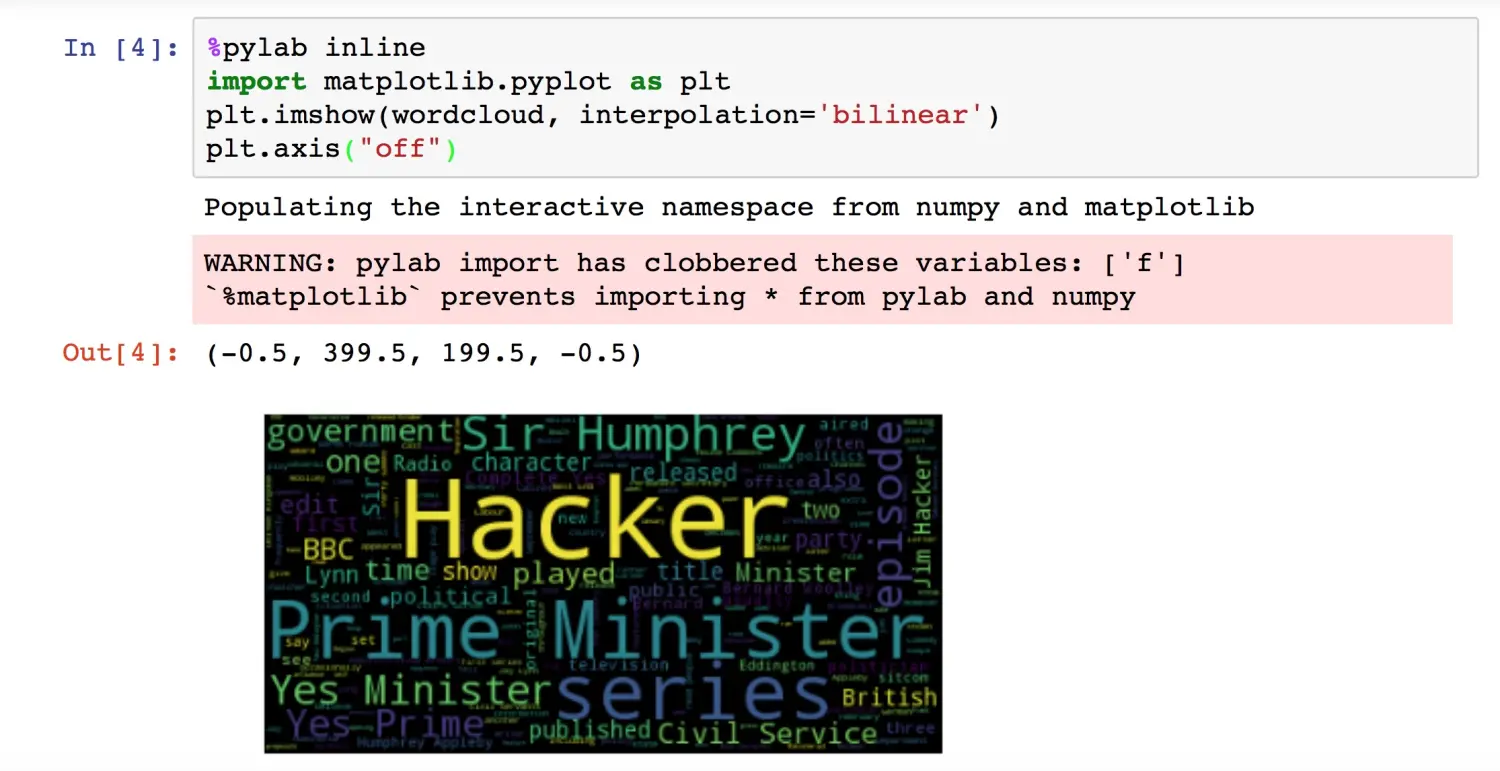
不用那么兴奋嘛。
你可以在词云图片上单机鼠标右键,用“图片另存为”功能导出。

通过这张词云图,我们可以看到不同单词和词组出现的频率高低差别。高频词的字体明显更大,而且颜色也很醒目。值得说明的是,最显眼的单词Hacker并不是指黑客,而是指这部剧的主角之一——哈克首相。
包含程序完整代码的ipynb文件,我也分享了出来,你可以从 这里 下载。
希望你在尝试过程中一切顺利。对自己生成的词云图满意吗?如果你不满意,也不要紧,可以挖掘wordcloud软件包的其他高级功能。尝试一下,看自己能不能做出这样的词云图来?
本文大部分是参考 王树义大牛文章
如果想要达成 上面链接的效果 需要安装scripy 、tkinter 模块
以及在运行python文件头部加入
import matplotlib
matplotlib.use('Agg')


pip安装软件时出现Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build*的解决方案
http://blog.csdn.NET/u011092188/article/details/64123561

















 1716
1716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









