







Reference:https://www.cnblogs.com/yanshw/category/1605447.html?page=2 大数据-Spark(29)栏目
0 大数据基本架构
了解架构能更清晰地认识每个组件,数据处理流程,用作流程设计和技术选型

0.1 数据传输层
Flume 专业的日志收集工具,对象一般是 文件类型;
Sqoop 是专门采集结构化数据的,对象一般是 数据库;
Kafka 实际上是一个 MQ,当做缓存,常用于高并发;它既能传输,也能存储,只是存储空间有限,默认 1 G(可配置),且有存储期限,默认 7 天(可配置);
其实还有一些不太常用的工具,如 Logstash、DataX
0.2 数据存储层
MySQL 关系型数据库,存储结构化数据,还有很多其他关系型数据库;
Mongodb 非关系型数据库;
HDFS 分布式 文件系统,非结构化数据,把文件分布式的存储在集群上;
Hive 是基于 hadoop 的数据仓库,存储结构化数据;Hive 也可以用于计算,所以也在计算层
HBase
S3
其中 HDFS、Hive、HBase 是大数据常用的技术,只是 HBase 用户在减少
0.3 数据计算层
MapReduce 基础分布式计算框架;
Hive 基于 MapReduce 的计算框架,它把 sql 转换成了 MapReduce;
Spark 基于内存的计算,计算效率高;
Storm 实时计算,只是它的扩展太少,逐渐被淘汰;
Flink 逐渐火起来;
Tez
1 shell命令
1.1 spark2-submit
spark2-submit\
--master yarn\
--deploy-mode client\
--driver-memory 10G\
--num-executors 20\
--executor-memory 20g\
--executor-cores 2\
--conf spark.yarn.executor.memoryoverhead=4096\
--conf spark.sql.adaptive.enabled=true\
--conf spark.sql.adaptive.shuffle.targetPostShuffleInputSize=67108864\
--conf spark.sql.broadcastTimeout=36000\
--conf spark.sql.autobroadcastJoinThreshold=36700160\
--conf spark.sql.shuffle.partitions=2000\
--conf spark.driver.maxResultSize 20g\
--conf spark.sql.execution.arrow.enabled true\
--conf spark.rpc.message.maxSize=1024\
--conf spark.kryoserializer.buffer.max 1g\
FD-12345.py
| 参数名 | 参数说明 |
| --master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local |
| --deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client |
| --class | 应用程序的主类,仅针对 java 或 scala 应用 |
| --name | 应用程序的名称 |
| --jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 |
| --packages | 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标 |
| --exclude-packages | 为了避免冲突 而指定不包含的 package |
| --repositories | 远程 repository |
| --conf PROP=VALUE | 指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m" |
| --properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf |
| --driver-memory | Driver内存,默认 1G |
| --driver-java-options | 传给 driver 的额外的 Java 选项 |
| --driver-library-path | 传给 driver 的额外的库路径 |
| --driver-class-path | 传给 driver 的额外的类路径 |
| --driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用 |
| --executor-memory | 每个 executor 的内存,默认是1G |
| --total-executor-cores | 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用 |
| --num-executors | 启动的 executor 数量。默认为2。在 yarn 下使用 |
| --executor-core | 每个 executor 的核数。在yarn或者standalone下使用 |
spark = SparkSession.builder.enableHiveSupport()\
.config("spark.executor.memory", "20g")\
.config("spark.driver.memory","20g")\
.config("spark.driver.maxResultSize", "20g")\
.config("spark.sql.execution.arrow.enabled", "true")\
.config("spark.sql.broadcastTimeout", "3600")\
.config("spark.rpc.message.maxSize", "1024")\
.config("spark.kryoserializer.buffer.max", "1g")\
.getOrCreate()
config("spark.kryoserializer.buffer.max", "1g")\
Spark设置Kryo序列化缓冲区大小
1.2 其他
【数据库笔记】常用数据库titles index 中的Shell and etc.
关于spark.sql.autoBroadcastJoinThreshold设置
2 SparkContext
- SparkContext 是在 spark 库中定义的一个类,作为 spark 库的入口点;
- 它表示连接到 spark,在进行 spark 操作之前必须先创建一个 SparkContext 的实例,并且只能创建一个;
- 利用 SparkContext 实例创建的对象都是 RDD,这是相对于 SparkSession 说的,因为 它创建的对象都是 DataFrame
2.1 创建SparkContext
from pyspark import SparkContext, SparkConf
### method 1
conf = SparkConf().setAppName('myapp1').setMaster('local[4]') # 设定 appname 和 master
sc = SparkContext(conf=conf)
## method 2
sc = SparkContext("spark://hadoop10:7077")
2.2 创建 RDD
- spark 最重要的一个概念叫 RDD,Resilient Distributed Dataset,弹性分布式数据集
- spark 是以 RDD 概念为中心运行的,RDD 是一个容错的、可以被并行操作的元素集合。
创建 RDD 有三种方式:
-
在驱动程序中并行化一个已经存在的集合【内存中的数据】
-
从外部存储系统引入数据,生成 RDD【外部存储介质中的数据,注意 spark 本身没有存储功能】
// 这个存储系统可以是一个共享文件系统,如 hdfs、hbase -
从一种 RDD 转换成 另一种 RDD
2.3 操作 RDD
RDD 的操作有两种方式:
- 转换(惰性):无返回值
- 行动:有返回值
转换 算子





行动 算子



2.4 RDD 缓存
distFile = sc.textFile('README.md')
m = distFile.map(lambda x: len(x)) # map 是 转换 操作,并不立即执行
m.cache() # 把 map 的输出缓存到内存中,其实 cache 就是 执行 操作
# 或者 m.persist()
cache作用:
-
把 RDD 缓存到 内存中, 惰性执行
-
缓存除了存储到内存中,还有一个非常重要的作用,复用以提高效率;
-
缓存的 RDD 不仅可以直接拿来转换成新的 RDD,还可以多次利用;
-
我们知道 RDD 是有血缘关系的,即一个 RDD 由另一个 RDD 转换得来,而这种关系可能是多层的;
-
如果一个 RDD 缓存了,spark 会执行到目前为止所有转换操作,并为生成的 RDD 创建一个检查点,但是由于 缓存 是惰性操作,缓存只会在第一次 行动 操作后创建,且第一次 行动 操作不受益,第二次三次直接调用缓存才受益;

cache适用场景:
- 缓存适合多次使用的数据,只用一次的无需缓存;
- 缓存适合大数据,小数据无需缓存s
sparkSession怎么缓存df和释放缓存?
如果在循环里不释放会导致缓存越来越大,这不太好哦,所以我们使用完就释放吧!
# 缓存方法
df.cache()
# 释放缓存的方法
df.unpersist()
# sparkSession对象
# spark = SparkSession.builder.appName(session).enableHiveSupport().getOrCreate()
# 检查是否成功缓存的方法:建立一个临时视图
>>> df2.createTempView('temp_df2')
>>> spark.catalog.isCached('temp_df2') # 检查下内存里没有,因为还没缓存
False
>>> df2.cache() # 缓存下
DataFrame[account_id: bigint, region: string]
>>> spark.catalog.isCached('temp_df2') # 检查下内存里确实有
True
>>> df.unpersist()# 释放缓存
DataFrame[account_id: bigint, region: string]
>>> spark.catalog.isCached('temp_df2') # 真的释放了
False
3 sparkSession
- pyspark 是 python 的一个库,python + spark,简单来说,想用 python 操作 spark,就必须用 pyspark 模块
- 操作spark第一步,创建 SparkSession 或者 SparkContext
-
在 spark1.x 中是创建 SparkContext
-
在 spark2.x 中创建 SparkSession,或者说在 sparkSQL 应用中创建 SparkSession
-
3.1 读取文件
读取 csv
- 利用 sparkSession 作为 spark 切入点
- 读取 单个 csv 和 多个 csv
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
if __name__ == '__main__':
scSpark = SparkSession.builder.appName("reading csv")\
.getOrCreate() # getOrCreate 获取现有 SparkSession 或者 新建一个 SparkSession
print(scSpark.sparkContext)
data_file = 'csvdata/*.csv'# 读取 csvdata 文件夹下所有 csv 文件,但是这些 csv 文件格式必须相同,也就是 列 相同
# data_file = 'xx.csv'# 读取单个 csv 文件
sdfData = scSpark.read.csv(data_file, header=True, sep=",").cache() # .cache 缓存返回data,从而提高性能
print('Total Records = {}'.format(sdfData.count()))
sdfData.show()
读取一个文件夹下多个 csv 时,务必保持 csv 格式相同,否则会警告,但不报错
19/10/15 02:29:32 WARN CSVDataSource: Number of column in CSV header is not equal to number of fields in the schema:
Header length: 2, schema size: 4
19/10/15 02:29:32 WARN CSVDataSource: CSV header does not conform to the schema.
异常记录
- 读取本地文件会出现 文件不存在
- 如下异常
Caused by: org.apache.spark.SparkException:
Error from python worker:
/usr/bin/python: No module named pyspark
PYTHONPATH was:
/usr/lib/hadoop-2.6.5/tmp/nm-local-dir/usercache/root/filecache/46/__spark_libs__6155997154509109577.zip/spark-core_2.11-2.4.4.jar
解决方法
conf = SparkConf().setAppName('gps').setMaster('yarn')
# 下面两句解决 No module named pyspark
conf.set('spark.yarn.dist.files','file:/usr/lib/spark/python/lib/pyspark.zip,file:/usr/lib/spark/python/lib/py4j-0.10.7-src.zip')
conf.setExecutorEnv('PYTHONPATH','pyspark.zip:py4j-0.10.7-src.zip')
sc = SparkContext(conf=conf)
# yarn 模式必须读取 集群 中的文件,不能读本地
rdd = sc.textFile('hdfs://hadoop10:9000/spark/dwd.csv')
spark-submit 命令:即使我在代码里指定了 master 为 yarn,spark-submit 运行时仍需指定 master,否则报错 No module named pyspark 【上面第二个异常】
bin/spark-submit --master yarn gpsfreq.py # 参数必须在 py 文件前面
python 命令:如果是 python 命令执行,无需额外指定 master
python gpsfreq.py
4 sparkSQL 数据抽象
sparkSQL 的数据抽象是 DataFrame,df 相当于表格,它的每一行是一条信息,形成了一个 Row
4.1 数据抽象
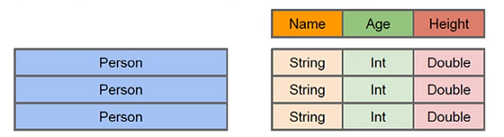
Row
它是 sparkSQL 的一个抽象,用于表示一行数据,从表现形式上看,相当于一个 tuple 或者 表中的一行;
from pyspark.sql import Row
##### 创建 Row
#### method 1
row = Row(name="Alice", age=11)
print row # Row(age=11, name='Alice')
print row['name'], row['age'] # ('Alice', 11)
print row.name, row.age # ('Alice', 11)
print 'name' in row # True
print 'wrong_key' in row # False
#### method 2
Person = Row("name", "age")
print Person # <Row(name, age)>
print 'name' in Person # True
print 'wrong_key' in Person # False
print Person("Alice", 11) # Row(name='Alice', age=11)
DataFrame (DF)
与 RDD 类似,df 也是分布式的数据容器,不同的是,df 更像一个 二维数据表,除了数据本身外,还包含了数据的结构信息,即 schema;
- df 的 API 提供了更高层的关系操作,比函数式的 RDD API 更加友好;
- df 的底层仍是 RDD,所以 df 也是惰性执行的,但值得注意的是,它比 RDD 性能更高;
问题来了:为什么底层实现是 RDD,却比 RDD 更快,不合常理啊
- 其实是这样的,因为 df 是由 spark 自己转换成RDD的,那么 spark 自然会用最合适的、最优化的方式转换成RDD,因为它比任何人都清楚怎么才能更高效
- 对比我们自己操作RDD去实现各种功能,大部分情况下我们的作法可能不是最优,自己玩不如作者玩,所以说 df 性能高于RDD
data1 = sc.parallelize([('1','a'), ('2', 'b'), ('3', 'c')])
data2 = sc.parallelize([('1','1'), ('2', '2'), ('3', '3')])
### 找到两个list中 key 为 1 的对应值的集合
## 自己写可能这么写
data1.join(data2).collect() # [('1', ('a', '1')), ('3', ('c', '3')), ('2', ('b', '2'))]
data1.join(data2).filter(lambda x: x[0] == '1').collect() # [('1', ('a', '1'))]
## spark 可能这么写
data1.filter(lambda x: x[0] == '1').join(data2.filter(lambda x: x[0] == '1')).collect() # [('1', ('a', '1'))]
为什么 spark 这么写快呢?
join是把 两个元素做 笛卡尔內积,生成了 3x3=9 个元素,然后shuffle,每个分区分别比较 key是否相同,如果相同,合并,然后合并分区结果;- 我们自己写的就是这样,shuffle 了 9 个元素;
- 而 spark 是先 filter,每个 list 变成了 一个元素,然后 join,join 的结果直接就是所需,不用shuffle;
- shuffle 本身是耗时的,而 filter 无需 shuffle,所以效率高【join 是个低效方法的原因】
DataSet
- DataSet 是 DataFrame 的扩展,是 spark 最新的数据抽象;
- dataSet 像个对象,允许我们像操作类一样操作它,通过属性查看数据;
- 实际上 DataSet 是在 df 的基础上增加了数据类型;
- df 只指定了字段名,而没有指定字段类型,sparkSQL 需要自动推断数据集的格式,这也是一种消耗,而 dataSet 直接指定了字段名和字段属性,效率更高
- python 目前不支持 dataSet,所以后续支持了再说
4.2 SparkSession
在老版本中,sparkSQL 提供了两种 SQL 查询的起始点:
- SQLContext,用于 spark 自己提供的 SQL 查询;
- HiveContext,用于连接 hive 的查询
sparkSession 是新版的 SQL 查询起始点,实质上是组合了 SQLContext 和 HiveContext;
sparkSession 只是封装了 sparkContext,sparkContext 包含 SQLContext 和 HiveContext;
所以 sparkSession 实际上还是 依靠 sparkContext 实现了 SQLContext 和 HiveContext,故老版本用法也适用新版本。
4.3 DataFrame 的创建
sparkSession 直接生成 df
df 的创建有 3 种方式
- 从 spark 的数据源创建:读取 spark 支持的文件
- 从内部 RDD 创建:RDD 转换成 df
- 从 hive 创建:hive 查询
4.4 DF 操作
sparkSQL 对 DF 的操作有两种风格,一种是类 sql 的方式,一种是 领域专属语言 DSL
RDD-DF-dataSet
rdd、dataFrame、dataSet 相当于 spark 中三种数据类型,简单总结几点:
-
rdd 是 df、ds 的底层实现
-
df 在 rdd 的基础上添加了结构,可以像数据表一个进行字段操作,易用,且高效
-
ds 在 df 的基础上添加了数据类型,并且可以像操作类一样进行属性操作,目前 python 不支持
-
三者可互相转换
-
df、ds 是 sparkSQL 中的数据类型,准确的说叫数据抽象,在 sparkSQL 中他们被转换成 table,进行 sql 操作
-
三者的计算逻辑并无差异,也就是说相同的数据,结果是相同的
-
三者的计算效率和执行方式不同
-
在未来 spark 演进过程中, ds 会逐步取代 df、rdd
发展历程
RDD(spark1.0) ===> DataFrame(spark1.3) ===> DataSet(spark1.6)
转换逻辑
- rdd + 表结构 = df
- rdd + 表结构 + 数据类型 = ds
- df + 数据类型 = ds
- ds - 数据类型 - 表结构 = rdd
- ds - 数据类型 = df
- df - 表结构 = rdd

RDD to DF 之 toDF
dataFrame 类似于数据表,数据表有行的概念,df 也有 Row 的概念,也就是说 df 必须是有行有列,二维的概念;
如果 RDD 不是二维,或者说没有 Row 的概念,需要显示的构建 Row 的格式;
## 手动构建 Row 的概念
rdd1 = sc.parallelize(range(5))
df1_1 = rdd1.map(lambda x: Row(id = x)).toDF() # 先加入结构,即字段,或者说 key,然后调用 toDF
# >>> df1
# DataFrame[id: bigint]
RDD to DF 之 spark.createDataFrame
该方法有两个输入:一个由行构成的RDD,一个数据格式;
数据格式可以是一个 StructType 类实例;
- 一个 StructType 对象包含一个 StructField 对象序列;
- 一个StructField 对象用于指定一列的名字、数据类型,并可选择的指定这一列是否包含空值及其元数据
### 方法2
rdd1 = sc.parallelize([range(5)]) # 注意必须是 二维 的,sc.parallelize(range(5)) 是不行的
df2_1 = spark.createDataFrame(rdd1).collect() # 没有显示地添加字段,以 默认值为 字段名
# [Row(_1=0, _2=1, _3=2, _4=3, _5=4)]
rdd2 = sc.parallelize([('a', 1), ('b', 2)]) # 二维数据
df2_2 = spark.createDataFrame(rdd2, ['label', 'num']).collect() # 显示地添加字段
# [Row(label=u'a', num=1), Row(label=u'b', num=2)]
### 方法3
rdd3 = sc.parallelize([('zhangsan', 20), ('lisi', 30)])
Person = Row('name', 'age') # 格式化 Row,每行代表一个 Person
person = rdd3.map(lambda x: Person(*x)) # 把 RDD 格式化成 新的 RDD,并加入 Row 的概念
df3_1 = spark.createDataFrame(person).show()
# +--------+---+
# | name|age|
# +--------+---+
# |zhangsan| 20|
# | lisi| 30|
# +--------+---+
### 方法4
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([StructField("name", StringType(), True),
StructField("age", IntegerType(), True)])
df3 = spark.createDataFrame(rdd3, schema).collect()
# [Row(name=u'zhangsan', age=20), Row(name=u'lisi', age=30)]
toDF() vs createDataFrame()
- 前者需要自己推断数据集的数据格式,因为并没有指定,后者则需要指定数据格式;
- 前者易用;
- 后者更加灵活,可以根据需要对同一数据设定多个数据格式,满足不同需求
DF to RDD
只需调用 rdd 属性即可
rdd = sc.parallelize([('a', 1), ('b', 2)]) # 二维数据
df = spark.createDataFrame(rdd2, ['label', 'num'])
df.rdd.collect()
# [Row(label=u'a', num=1), Row(label=u'b', num=2)]
5 sparkSQL
5.1 sparkSQL 的由来
- 我们知道最初的计算框架叫 mapreduce,他的缺点是计算速度慢,还有一个就是代码比较麻烦,所以有了 hive;
- hive 是把类 sql 的语句转换成 mapreduce,解决了开发难的问题,但是
hive的底层还是mapreduce,仍然是慢; - spark 也看到了 hive 的优势,以 hive 为中心的一套框架 shark 营运而生,它是 spark 的前身,h 就是 hive 的意思;
- 但是 为了 提高 shark 的效率,spark 自己开发了一套算法,替代了之前 hive 的思路,这套算法就是 sparkSQL
5.2 sparkSQL 简介
- sparkSQL 是 spark 专门处理结构化数据的一个模块,也就是像数据表一样的数据,处理方式就是像 sql 一样;
- 换句话说,sparkSQL 使用 sql 的方式代替了之前数据处理的方式
- sparkSQL 提供了两个编程抽象:DataFrame 和 DataSet,起到了分布式 SQL 查询引擎的作用;
- sparkSQL 把 sql 语句 和 dataFrame、dataSet 转换成了 RDD,执行效率非常快;
- 也就是说 dataFrame、dataSet 的底层仍然 是 RDD,并且可以互相转换
5.3 sparkSQL 的特点
- 易整合
- 兼容 hive
- 统一的数据访问方式:用同样的方式读取各类文件
- 标准的数据库连接:可以通过 JDBC 或者 ODBC 连接标准数据库
6 SparkSession
- spark 有三大引擎,spark core、sparkSQL、sparkStreaming
- spark core 的关键抽象是 SparkContext、RDD;
- SparkSQL 的关键抽象是 SparkSession、DataFrame;
- sparkStreaming 的关键抽象是 StreamingContext、DStream
SparkSession 是 spark2.0 引入的概念,主要用在 sparkSQL 中,当然也可以用在其他场合,他可以代替 SparkContext;
SparkSession 其实是封装了 SQLContext 和 HiveContext
6.1 SQLContext
它是 sparkSQL 的入口点,sparkSQL 的应用必须创建一个 SQLContext 或者 HiveContext 的类实例
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession, SQLContext, HiveContext
conf = SparkConf().setAppName('test').setMaster('yarn')
sc = SparkContext(conf=conf)
sqlc = SQLContext(sc)
print(dir(sqlc))
# 'cacheTable', 'clearCache', 'createDataFrame', 'createExternalTable', 'dropTempTable', 'getConf', 'getOrCreate', 'newSession', 'range', 'read', 'readStream',
# 'registerDataFrameAsTable', 'registerFunction', 'registerJavaFunction', 'setConf', 'sparkSession', 'sql', 'streams', 'table', 'tableNames', 'tables', 'udf', 'uncacheTable'
### sqlcontext 读取数据也自动生成 df
data = sqlc.read.text('/usr/yanshw/test.txt')
print(type(data))
6.2 HiveContext
它是 sparkSQL 的另一个入口点,它继承自 SQLContext,用于处理 hive 中的数据
HiveContext 对 SQLContext 进行了扩展,功能要强大的多
-
它可以执行 HiveSQL 和 SQL 查询
-
它可以操作 hive 数据,并且可以访问 HiveUDF
-
它不一定需要 hive,在没有 hive 环境时也可以使用 HiveContext
注意,如果要处理 hive 数据,需要把 hive 的 hive-site.xml 文件放到 spark/conf 下,HiveContext 将从 hive-site.xml 中获取 hive 配置信息;
如果 HiveContext 没有找到 hive-site.xml,他会在当前目录下创建 spark-warehouse 和 metastore_db 两个文件夹
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession, SQLContext, HiveContext
conf = SparkConf().setAppName('test').setMaster('yarn')
sc = SparkContext(conf=conf)
## 需要把 hive/conf/hive-site.xml 复制到 spark/conf 下
hivec = HiveContext(sc)
print(dir(hivec))
# 'cacheTable', 'clearCache', 'createDataFrame', 'createExternalTable', 'dropTempTable', 'getConf', 'getOrCreate', 'newSession', 'range', 'read', 'readStream','refreshTable',
# 'registerDataFrameAsTable', 'registerFunction', 'registerJavaFunction', 'setConf', 'sparkSession', 'sql', 'streams', 'table', 'tableNames', 'tables', 'udf', 'uncacheTable'
data = hivec.sql('''select * from hive1101.person limit 2''')
print(type(data))
6.3 SparkSession
它实现了对二者的封装
SparkSession 的创建
from pyspark.sql import SparkSession
### method 1
sess = SparkSession.builder \
.appName("aaa") \
.config("spark.driver.extraClassPath", sparkClassPath) \
.master("local") \
.enableHiveSupport() \ # sparkSQL 连接 hive 时需要这句
.getOrCreate() # builder 方式必须有这句
### method 2
conf = SparkConf().setAppName('myapp1').setMaster('local[4]') # 设定 appname 和 master
sess = SparkSession.builder.config(conf=conf).getOrCreate() # builder 方式必须有这句
### method 3
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName('myapp1').setMaster('local[4]') # 设定 appname 和 master
sc = SparkContext(conf=conf)
sess = SparkSession(sc)
SparkSession vs SparkContext
SparkSession 是 spark2.x 引入的新概念,SparkSession 为用户提供统一的切入点,字面理解是创建会话,或者连接 spark
在 spark1.x 中,SparkContext 是 spark 的主要切入点,由于 RDD 作为主要的 API,我们通过 SparkContext 来创建和操作 RDD,
SparkContext 的问题在于:
- 不同的应用中,需要使用不同的 context,在 Streaming 中需要使用 StreamingContext,在 sql 中需要使用 sqlContext,在 hive 中需要使用 hiveContext,比较麻烦
- 随着 DataSet 和 DataFrame API 逐渐成为标准 API,需要为他们创建接入点,即 SparkSession
SparkSession 实际上封装了 SparkContext、 SparkConf、sqlContext,随着版本增加,可能更多,所以我们尽量使用 SparkSession ,如果发现有些 API 不在SparkSession中,也可以通过 SparkSession 拿到 SparkContext 和其他 Context 等
在 shell 操作中,原生创建了 SparkSession,故无需再创建,创建了也不会起作用
在 shell 中,SparkContext 叫 sc,SparkSession 叫 spark
# test 只是个字符
strlen = spark.udf.register("stringLengthString", lambda x: len(x))
spark.sql("SELECT stringLengthString('test')").collect()
# [Row(stringLengthString(test)=u'4')]
# read hive table
spark.sql("SELECT stringLengthString(name) from hive1101.person limit 3").collect()
# [Row(stringLengthString(name)=u'4'), Row(stringLengthString(name)=u'4'), Row(stringLengthString(name)=u'4')]
from pyspark.sql.types import IntegerType
from pyspark.sql.functions import udf
slen = udf(lambda s: len(s), IntegerType())
_ = spark.udf.register("slen", slen)
spark.sql("SELECT slen('test')").collect()
# [Row(slen(test)=4)]
6.4 repartition and coalesce
def repartition(self, numPartitions):
"""
Return a new RDD that has exactly numPartitions partitions.
Can increase or decrease the level of parallelism in this RDD.
Internally, this uses a shuffle to redistribute data.
If you are decreasing the number of partitions in this RDD, consider
using `coalesce`, which can avoid performing a shuffle.
>>> rdd = sc.parallelize([1,2,3,4,5,6,7], 4)
>>> sorted(rdd.glom().collect())
[[1], [2, 3], [4, 5], [6, 7]]
>>> len(rdd.repartition(2).glom().collect())
2
>>> len(rdd.repartition(10).glom().collect())
10
"""
return self.coalesce(numPartitions, shuffle=True)
def coalesce(self, numPartitions, shuffle=False):
"""
Return a new RDD that is reduced into `numPartitions` partitions.
>>> sc.parallelize([1, 2, 3, 4, 5], 3).glom().collect()
[[1], [2, 3], [4, 5]]
>>> sc.parallelize([1, 2, 3, 4, 5], 3).coalesce(1).glom().collect()
[[1, 2, 3, 4, 5]]
"""
if shuffle:
# Decrease the batch size in order to distribute evenly the elements across output
# partitions. Otherwise, repartition will possibly produce highly skewed partitions.
batchSize = min(10, self.ctx._batchSize or 1024)
ser = BatchedSerializer(PickleSerializer(), batchSize)
selfCopy = self._reserialize(ser)
jrdd_deserializer = selfCopy._jrdd_deserializer
jrdd = selfCopy._jrdd.coalesce(numPartitions, shuffle)
else:
jrdd_deserializer = self._jrdd_deserializer
jrdd = self._jrdd.coalesce(numPartitions, shuffle)
return RDD(jrdd, self.ctx, jrdd_deserializer)
- 我们看到 repartition 最终是调用了 coalesce 方法,并且把 coalesce 的参数
shuffle=True; - 所以搞懂了 coalesce,也就搞懂了 repartition
- 如果是生成一个窄依赖的结果,无需 shuffle,比如 1000个分区重新分成10个分区;
- 窄依赖:一个父RDD的分区对应一个子RDD的分区,或者多个父RDD的分区对应一个子RDD的分区;
- 宽依赖:一个父RDD的分区对应多个子RDD的分区

- 如果分区数量变化巨大,如设置
numPartition=1,这可能造成运行计算的节点比你想象的少,为了避免这种情况,可以设置shuffle=True - 如果需要增加分区数,
shuffle=False时,并不会进行重分区,只有设置成 True 才可以 - repartition 是 特殊的 coalesce,相当于把 coalesce 的参数 shuffle 写死成 True
7 spark异常篇
7.1 OutOfMemory:GC overhead limit exceeded

在执行 count 时没什么问题,各种参数影响不大;但是在执行 collect 时,总是报错

8 spark调优篇
8.1 Spark ON Yarn 内存管理
内存相关参数
spark 是基于内存的计算,spark 调优大部分是针对内存的,了解 spark 内存参数有也助于我们理解 spark 内存管理
- spark.driver.memory:默认 512M
- spark.executor.memory:默认 512M
- spark.yarn.am.memory:默认 512M
- spark.yarn.driver.memoryOverhead:driver memory * 0.10, with minimum of 384
- spark.yarn.executor.memoryOverhead:executor memory * 0.10, with minimum of 384
- spark.yarn.am.memoryOverhead:am memory * 0.10, with minimum of 384
- executor-cores:executor 相当于一个进程,cores 相当于该进程里的线程
常见问题
常见的问题无非就是 内存不足 或者 container 被杀死
Removing executor 5 with no recent heartbeats: 120504 ms exceeds
timeout 120000 ms Container killed by YARN for exceeding memory limits
Consider boosting spark.yarn.executor.memoryOverhead
spark-OutOfMemory:GC overhead limit exceeded
常规思路
-
第一解决办法就是增加总内存【此法不能解决所有问题】
-
其次考虑数据倾斜问题,因为数据倾斜导致某个 task 内存不足,其它 task 内存足够
// 最简单的方法是repartition【此法不能解决所有问题】 -
考虑增加每个 task 的可用内存
// 减少Executor数
// 减少executor-cores数
参数设置注意事项
垃圾回收 (garbage collection, GC)
-
executor-memory
- 设置过大,会导致 GC 过程很长,64G 是推荐的内存上限【根据硬件不同,可寻找合适的上限】
- 设置过小,会导致 GC 频繁,影响效率
-
executor-cores
- 设置过大,并行度会很高,容易导致 网络带宽占满,特别是从 HDFS 读取数据,或者是 collect 数据回传 Driver
- 设置过大,使得多个 core 之间争夺 GC 时间以及资源,导致大部分时间花在 GC 上
8.2 数据倾斜
8.3 oom 优化
spark 之所以需要调优
- 一是代码执行效率低
- 二是经常 OOM
Spark中的Driver和Executor

- Driver :Driver是Spark中Application也即代码的发布程序,可以理解为我们编写spark代码的主程序,因此只有一个,负责对spark中SparkContext对象进行创建,其中SparkContext对象负责创建Spark中的RDD(Spark中的基本数据结构,是一种抽象的逻辑概念)
- Driver的另外一个职责是将任务分配给各个Executor进行执行。任务分配的原则主要是就近原则,即数据在哪个Executor所在的机器上,则任务分发给哪个Exectuor。
简单来说就是:Driver就是new sparkcontext的那个应用程序类可以成为Driver ,而且Driver的职责是将任务分配给Exectuor执行计算
- Executor:是Spark中执行任务的计算资源,可以理解为分布式的CPU,每台机器可能存在多个Executor(因为计算机的CPU有多个核),这些分布式的计算机集群会有很多的Executor,Executor主要负责Spark中的各种算子的实际计算(如map等)

内存溢出
内存溢出无非两点:
-
Driver 内存不够
-
Executor 内存不够
Driver 内存不够无非两点:
-
读取数据太大
-
数据回传
Executor 内存不够无非两点:
-
map 类操作产生大量数据,包括 map、flatMap、filter、mapPartitions 等
-
shuffle 后产生数据倾斜 spark调优篇-数据倾斜(汇总)
Driver 中需要读取大量数据
造成 Driver 内存溢出
解决思路是增加 Driver 内存,具体做法为设置参数
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
from pyspark import SparkContext
sc = SparkContext(master='yarn')
rdd = sc.parallelize(range(300000000))
# spark-submit --master yarn-client --driver-memory 512M driver_oom.py 内存溢出
# spark-submit --master yarn-client --driver-memory 3G driver_oom.py 可以执行
collect
大量数据回传 Driver,造成内存溢出
解决思路是分区输出,具体做法是 foreach 或者增加 Driver 内存
rdd = sc.parallelize(range(100))
rdd.flatMap(lambda x: ['%d'%x*50 for _ in range(100000)]).collect() # 内存溢出
def func(x): print(x)
rdd.flatMap(lambda x: ['%d'%x*50 for _ in range(100000)]).foreach(func) # 分区输出
Executor 内存不够
有个通用的解决办法就是增加 Executor 内存,但这并不一定是最好的办法
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
map 过程产生大量对象
造成 Executor 内存溢出
解决思路是减少每个 task 的大小,从而减少每个 task 的输出;
具体做法是在 会产生大量对象的 map 操作前 添加 repartition(重新分区) 方法,分区成更小的块传入 map
rdd.flatMap(lambda x: ['%d'%x*50 for _ in range(100000000)]).count() # 100 * 100000000 个对象,内存溢出
rdd.flatMap(lambda x: len(['%d'%x*50 for _ in range(100000000)])).sum() # 内存溢出
rdd.repartition(1000000).flatMap(lambda x: ['%d'%x*50 for _ in range(100000000)]).count() # 可执行















 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









