









文章目录
引入
我们日常中都写过作文,我们在写作文之前要先确定主题,比如写科技类的,文化类的,经济类的。
一篇文章可能有一个中心的主题,还有很多分支的主题,即我们的文章会通常从多个方面考虑而不是单一的。
确定了主题,那么接下来就是用词造句了。
比如写科技相关的的文章时,我们会偏向于用(机械,计算机,CPU,无人机)这类的单词。而不偏向用(朋友,爱情,人脉)这样的词。
也就是在我们写某个特定的主题时,我们所使用的词的概率是不同的。
LDA也正是这么考虑的。
- LDA认为每个文章由若干的主题组成,每个主题的占比不同,从而这些主题形成了一个分布
比如: 一篇文章有三个主题,分别是(科技,经济,自然)
那么这个文章的主题分布可能是
P ( 科 技 ) = 0.6 , P ( 经 济 ) = 0.2 , P ( 自 然 ) = 0.2 P(科技)=0.6,P(经济)=0.2,P(自然)=0.2 P(科技)=0.6,P(经济)=0.2,P(自然)=0.2 - LDA对于每个主题,它们所对应的词的占比也是不同的。
即每个主题的词构成了一个分布 P ( w o r d ∣ 主 题 ) P(word|主题) P(word∣主题),和主题相关度高的词的概率会高于不相关的。 - LDA认为,当知道文章的主题和主题词的概率分布时,我们就可以生成一篇相关文章。
比如我们知道主体分布为:
P ( 科 技 ) = 0.6 , P ( 经 济 ) = 0.2 , P ( 自 然 ) = 0.2 P(科技)=0.6,P(经济)=0.2,P(自然)=0.2 P(科技)=0.6,P(经济)=0.2,P(自然)=0.2
还知道每个主题的词的分布为
P ( 无 人 机 ∣ 科 技 ) = 0.4 , P ( 计 算 机 ∣ 科 技 ) = 0.5 , P ( 财 政 ∣ 科 技 ) = 0.01 , P ( 植 物 分 类 学 ∣ 科 技 ) = 0.06 , P ( 国 家 公 园 ∣ 科 技 ) = 0.03 P ( 无 人 机 ∣ 经 济 ) = 0.01 , P ( 计 算 机 ∣ 经 济 ) = 0.03 , P ( 财 政 ∣ 经 济 ) = 0.8 , P ( 植 物 分 类 学 ∣ 经 济 ) = 0.1 , P ( 国 家 公 园 ∣ 经 济 ) = 0.06 P ( 无 人 机 ∣ 自 然 ) = 0.05 , P ( 计 算 机 ∣ 自 然 ) = 0.05 , P ( 财 政 ∣ 自 然 ) = 0.1 , P ( 植 物 分 类 学 ∣ 自 然 ) = 0.4 , P ( 国 家 公 园 ∣ 自 然 ) = 0.4 P(无人机|科技)=0.4, P(计算机|科技)=0.5, P(财政|科技)=0.01,P(植物分类学|科技)=0.06,P(国家公园|科技)=0.03\\ P(无人机|经济)=0.01, P(计算机|经济)=0.03, P(财政|经济)=0.8,P(植物分类学|经济)=0.1,P(国家公园|经济)=0.06\\ P(无人机|自然)=0.05, P(计算机|自然)=0.05, P(财政|自然)=0.1,P(植物分类学|自然)=0.4,P(国家公园|自然)=0.4 P(无人机∣科技)=0.4,P(计算机∣科技)=0.5,P(财政∣科技)=0.01,P(植物分类学∣科技)=0.06,P(国家公园∣科技)=0.03P(无人机∣经济)=0.01,P(计算机∣经济)=0.03,P(财政∣经济)=0.8,P(植物分类学∣经济)=0.1,P(国家公园∣经济)=0.06P(无人机∣自然)=0.05,P(计算机∣自然)=0.05,P(财政∣自然)=0.1,P(植物分类学∣自然)=0.4,P(国家公园∣自然)=0.4
然后我们就可以生成一篇文章为
无 人 机 计 算 机 计 算 机 财 政 国 家 公 园 无人机计算机计算机财政国家公园 无人机计算机计算机财政国家公园
看起来不顺,是因为在生成文章时,LDA没有考虑先后顺序,只是按概率挑选单词。不过没有关系,他至少与我们的主题是相符的。
到这里你应该已经知道LDA的想法了,他想法其实就是对日常生活中我们写文章时的规律做出了一个描述。
LDA的概率图
感性的了解了LDA的想法之后,我们还必须要从更加严谨的角度读LDA进行一个描述。
从LDA的想法可以看出,LDA是一个生成模型,我们可以明显的感觉到变量之间决定顺序。
那么此时我们就可以使用概率图来加以进行更直观的描述。
- 首先我们先描述主题的分布,我们假设主题服从一个分布,其为
θ
\theta
θ。如果有多篇文章,我们就假设
θ
i
\theta_i
θi为第i偏文章的主题分布。
假设主题有K个,文章有D个,那么 θ i j ( i ∈ ( 1 , 2 , 3... , D ) , i ∈ ( 1 , 2 , 3... , K ) ) \theta_{ij}(i \in (1,2, 3..., D), i \in (1,2, 3..., K)) θij(i∈(1,2,3...,D),i∈(1,2,3...,K))就表示第i篇文章中第j个主题的占比。 - 接下来我们看单词的分布,我们假设其为
ϕ
\phi
ϕ。
假设有D个文档,词典大小为V。那么 ϕ i j ( i ∈ ( 1 , 2 , 3... , D ) , i ∈ ( 1 , 2 , 3... , V ) ) \phi_{ij}(i \in (1,2, 3..., D), i \in (1,2, 3..., V)) ϕij(i∈(1,2,3...,D),i∈(1,2,3...,V))就表示了,在第i个主题的情况下第j个词的出现的概率。 - 假设我们生成了若干文章一共有D篇其中第i篇生成了
∣
D
i
∣
|D_i|
∣Di∣个词,我们记w。
w i j ( i ∈ ( 1 , 2 , 3... , D ) , i ∈ ( 1 , 2 , 3... , ∣ D i ∣ ) w_{ij}(i \in (1,2, 3..., D), i \in (1,2, 3..., |D_i|) wij(i∈(1,2,3...,D),i∈(1,2,3...,∣Di∣)我们表示第i篇文章中第j个词。 - 除此之外,我们还需要额外在加一步在生成单词之前,我们还需要先确定每个单词属于哪个主题。
即我们需要从文章对应的主题分布 θ \theta θ抽取出若干的主题,作为接下来生成单词主题。然后我们在用这些主题去 ϕ \phi ϕ中,挑选具体的单词。
我们设,第i个文章中,第j个单词被调戏选出的的主题是 Z i j Z_{ij} Zij,显然,Z和w的形状是完全相同的,因为它们一一对应。
那么好了,大功告成,我们画一下这些设的量之间的关系。

但是好像还是有点问题,
θ
,
ϕ
\theta,\phi
θ,ϕ是怎么来的呢?难道要作为我们的先验知识么?
如果这样的话,我们就得请专家挨个的去估计,显然是很蠢的。那既然
θ
,
ϕ
\theta,\phi
θ,ϕ是会随着我们生成的文章的不同而不同,那就说明他们也服从某个分布。
也就是说,存在某个分布,这个分布的随机变量构成了
θ
\theta
θ或者是
ϕ
\phi
ϕ
用公式来表达就是
存在分布
P
(
θ
∣
α
)
和
P
(
ϕ
∣
β
)
,
其
中
β
和
α
是
这
两
个
分
布
的
参
数
P(\theta|\alpha)和P(\phi|\beta),其中\beta和\alpha是这两个分布的参数
P(θ∣α)和P(ϕ∣β),其中β和α是这两个分布的参数
使得
∑
i
=
1
∣
θ
∣
θ
i
=
1
,
θ
i
≥
0
∑
i
=
1
∣
ϕ
∣
ϕ
i
=
1
,
ϕ
i
≥
0
\sum_{i = 1}^{|\theta|}\theta_i=1,\theta_i\geq0\\ \sum_{i = 1}^{|\phi|}\phi_i=1,\phi_i\geq0
i=1∑∣θ∣θi=1,θi≥0i=1∑∣ϕ∣ϕi=1,ϕi≥0
大家不要混淆了,这里
θ
\theta
θ是作为P的随机变量,随机变量的和可不一定为1,比如高斯分布其随机变量的取值范围可是整个实数域。
想要找到这样的分布,可以说是有点苛刻,但是正好有一个分布满足我们的要求,他就是狄利克雷分布(dirichlet distribution)
有了这个分布之后,我们就可以从这个分布生成
ϕ
,
θ
\phi,\theta
ϕ,θ,不需要在进行人工估计了。
那么换而言之,我们只需要提前知狄利克雷分布的参数,就可以得到
ϕ
,
θ
\phi,\theta
ϕ,θ了。

接下来我们就需要补一些关于狄利克雷分布和一些其他分布的相关知识了。
潜在狄利克雷分配
潜在狄利克雷分配,也叫LDA(Latent Dirichlet Allocation)
是一种主题模型,可以用于进行文本的聚类,是一种需要使用无监督学习的算法,它的想法就如我们上面的所描述的一样。非常朴素简单。
使用潜在狄利克雷分配我们最主要需要解决两个问题,第一个是
模型参数的学习
新数据的预测
这里主要讲,模型参数的学习,对于预测之后我再补吧。
几个分布
首先先看几个分布和函数,由于这里的分布的式子都是基础内容,我就列一下不做其性质的推导什么的。
- 多项分布
P ( X 1 = n 1 , X 2 = n 2 , . . . , X k = n k ) = n ! ∏ i = 1 k n i ! ∏ i = 1 k p n i P(X_1= n_1, X_2=n_2,..., X_{k} = n_k)=\frac{n!}{\prod_{i = 1}^kn_i!}\prod_{i = 1}^kp^{n_i} P(X1=n1,X2=n2,...,Xk=nk)=∏i=1kni!n!i=1∏kpni
其中 ( n 1 , n 2 , . . . , n k ) ( n_1,n_2,...,n_k) (n1,n2,...,nk)表示每个随机变量发生的次数,多项分布是二项分布的扩展,特别的,当 ∑ i = 1 k n i = 1 \sum_{i = 1}^kn_i=1 ∑i=1kni=1时有
P ( X 1 = n 1 , X 2 = n 2 , . . . , X k = n k ) = ∏ i = 1 k p n i P(X_1= n_1, X_2=n_2,..., X_{k} = n_k)=\prod_{i = 1}^kp^{n_i} P(X1=n1,X2=n2,...,Xk=nk)=i=1∏kpni - 狄利克雷分布
狄利克雷分布可以写作
P ( θ ∣ α ) = 1 B ( α ) ∏ i = 1 k θ i α i − 1 P(\theta|\alpha) = \frac{1}{B(\alpha)}\prod_{i =1}^k\theta_i^{\alpha_i - 1} P(θ∣α)=B(α)1i=1∏kθiαi−1
其中 α \alpha α是一个k维的向量,也就是这个分布是一个k维的分布,其中B(a)为beta函数
狄利克雷分布满足
∑ i = 1 k θ i = 1 , θ i ≥ 0 \sum_{i = 1}^{k}\theta_i=1,\theta_i\geq0 i=1∑kθi=1,θi≥0 - beta函数
beta函数可以写成如下的形式
B ( α ) = ∫ ∏ i = 1 k θ i α i − 1 d θ B(\alpha)=\int \prod_{i = 1}^k\theta_i^{\alpha_i - 1}d\theta B(α)=∫i=1∏kθiαi−1dθ
共轭先验
所谓的共轭先验可以理解为,先验概率和后概率服从同种分布的分布。
共轭先验有很多对,这里我们主要说,狄利克雷分布和多项分布这一对。
假设有样本数据D,其产生服从多项分布,每个样本之间的产生相互独立,就有
P
(
D
∣
θ
)
=
∏
i
=
1
k
θ
i
n
i
P(D|\theta)=\prod_{i = 1}^k\theta_i^{n_i}
P(D∣θ)=i=1∏kθini
因为每个样本都服从实验次数为1的多项分布
假设我们想要估计参数
θ
\theta
θ,即求后验概率
P
(
θ
∣
D
)
P(\theta|D)
P(θ∣D)
根据贝叶斯公式就有
P
(
θ
∣
D
)
=
P
(
D
∣
θ
)
P
(
θ
)
P
(
D
)
=
P
(
D
∣
θ
)
P
(
θ
)
∫
P
(
D
∣
θ
)
P
(
θ
)
d
θ
P(\theta|D) = \frac{P(D|\theta)P(\theta)}{P(D)}=\frac{P(D|\theta)P(\theta)}{\int P(D|\theta)P(\theta)d\theta}
P(θ∣D)=P(D)P(D∣θ)P(θ)=∫P(D∣θ)P(θ)dθP(D∣θ)P(θ)
如果对这里的式子有疑问,可以看看贝叶斯估计
https://blog.csdn.net/qq_36102055/article/details/116984083
我们假设先验概率
θ
\theta
θ服从先验分布
D
i
r
i
c
h
l
e
t
(
α
)
Dirichlet(\alpha)
Dirichlet(α)
那么就有
P
(
D
∣
θ
)
P
(
θ
)
∫
P
(
D
∣
θ
)
P
(
θ
)
d
θ
=
1
B
(
α
)
∏
i
=
1
k
θ
i
n
i
θ
i
α
i
−
1
1
B
(
α
)
∫
∏
i
=
1
k
θ
n
i
θ
α
i
−
1
d
θ
\frac{P(D|\theta)P(\theta)}{\int P(D|\theta)P(\theta)d\theta}=\frac{\frac{1}{B(\alpha)}\prod\limits_{i =1}^k\theta^{n_i}_i\theta^{\alpha_i -1}_i}{\frac{1}{B(\alpha)}\int \prod\limits_{i =1}^k\theta^{n_i}\theta^{\alpha_i -1}d\theta}
∫P(D∣θ)P(θ)dθP(D∣θ)P(θ)=B(α)1∫i=1∏kθniθαi−1dθB(α)1i=1∏kθiniθiαi−1
我们消去B(a)合并
θ
\theta
θ
1
B
(
α
)
∏
i
=
1
k
θ
i
n
i
θ
i
α
i
−
1
1
B
(
α
)
∫
∏
i
=
1
k
θ
n
i
θ
α
i
−
1
d
θ
=
∏
i
=
1
k
θ
i
n
i
+
α
i
−
1
∫
∏
i
=
1
k
θ
n
i
+
α
i
−
1
d
θ
\frac{\frac{1}{B(\alpha)}\prod\limits_{i =1}^k\theta^{n_i}_i\theta^{\alpha_i -1}_i}{\frac{1}{B(\alpha)}\int \prod\limits_{i =1}^k\theta^{n_i}\theta^{\alpha_i -1}d\theta} =\frac{\prod\limits_{i =1}^k\theta^{n_i+\alpha_i-1}_i}{\int \prod\limits_{i =1}^k\theta^{n_i+\alpha_i-1}d\theta}
B(α)1∫i=1∏kθniθαi−1dθB(α)1i=1∏kθiniθiαi−1=∫i=1∏kθni+αi−1dθi=1∏kθini+αi−1
上式分母显然是一个beta函数,我们可以写成
∏
i
=
1
k
θ
i
n
i
+
α
i
−
1
∫
∏
i
=
1
k
θ
n
i
+
α
i
−
1
d
θ
=
∏
i
=
1
k
θ
i
n
i
+
α
i
−
1
B
(
n
1
+
α
1
,
.
.
.
,
n
k
+
α
k
)
\frac{\prod\limits_{i =1}^k\theta^{n_i+\alpha_i-1}_i}{\int \prod\limits_{i =1}^k\theta^{n_i+\alpha_i-1}d\theta} = \frac{\prod\limits_{i =1}^k\theta^{n_i+\alpha_i-1}_i}{B(n_1+\alpha_1, ..., n_k+\alpha_k)}
∫i=1∏kθni+αi−1dθi=1∏kθini+αi−1=B(n1+α1,...,nk+αk)i=1∏kθini+αi−1
然后你就会发现,这其实是另一个狄利克雷分布,于是我们得到了
P
(
θ
∣
D
)
∼
D
i
r
i
c
h
l
e
t
(
θ
∣
α
+
n
)
P(\theta|D) \thicksim Dirichlet(\theta|\alpha+n)
P(θ∣D)∼Dirichlet(θ∣α+n)
其中
n
=
(
n
1
,
n
2
,
.
.
.
,
n
k
)
n=(n_1, n_2, ..., n_k)
n=(n1,n2,...,nk)
生成流程
接下来我们详细的看一下LDA的生成的流程,以便为我们的学习算法做准备
首先,是
θ
\theta
θ的生成,我们知道它服从狄利克雷分布,所以我们从狄利克雷分布中进行抽取得到
θ
1
,
θ
2
,
.
.
.
,
θ
n
\theta_1, \theta_2, ..., \theta_n
θ1,θ2,...,θn
然后我们从 θ \theta θ里抽取对应每个文章的单词对应的主题,从 θ i \theta_i θi中抽取 Z i 1 , Z i 2 , . . . , Z i ∣ D i ∣ Z_{i1}, Z_{i2}, ..., Z_{i|D_i|} Zi1,Zi2,...,Zi∣Di∣
然后我们从 ϕ \phi ϕ对应的狄利克雷分布里抽取对应的 ϕ 1 , ϕ 2 , . . . , ϕ k \phi_1, \phi_2, ..., \phi_k ϕ1,ϕ2,...,ϕk
最后我们依据 ϕ \phi ϕ和 Z Z Z生成w
学习算法
gibbs sample
对于LDA的学习我们可以采用吉布斯采样法。
回顾一下贝叶斯学习的过程,贝叶斯学习的目的是学习到
θ
^
=
∫
θ
θ
P
(
θ
∣
X
)
d
θ
\hat \theta=\int_\theta \theta P(\theta|X)d\theta
θ^=∫θθP(θ∣X)dθ
我们很难求出所有的
θ
\theta
θ假设一个模型有一千个参数,那么这就会变成一个一千重的积分,几乎无法对其进行精确求解,但是,我们可以使用采样的方法进行近似求解。
其思路是我们对分布
P
(
θ
∣
X
)
P(\theta|X)
P(θ∣X)进行多次采样,只要采样次数够多就可以近似的逼近我们结果。
值得注意的是,我们每次采样都可能得到重复的结果。
比如我们采样得到(1, 2, 3, 3, 3, 2, 4),其中3就重复了多次,也正是因为这种重复,所以我们从采样中就可以得到分布,也就是概率比较大的
θ
\theta
θ自然会被多次采样,从而我们就可以近似出它的概率。
假设我们独立采样N次,就可以得到
θ
^
=
1
N
∑
i
=
1
N
θ
i
\hat \theta=\frac{1}{N}\sum_{i = 1}^N \theta_i
θ^=N1i=1∑Nθi
其中
θ
i
\theta_i
θi表示第i次采样的结果,对于为什么这里是取平均,上面已经解释过,就是因为概率大的会被多次采样。
这种采样有一个缺陷,每次采样都是独立的,没有相互关联,而MCMC算法考虑了这一点。让每次采样依赖于上一次,这样的好处是:当某个参数特特别好时,他周围的参数也一般会比较好。这样我们在其周围采样就可以得到比较好的结果。
贝叶斯网络相关知识
我们先复习一下贝叶斯网络的性质(如果一点也不知道啥是贝叶斯网路可以先看我写的HMM),假设有这么一个贝叶斯网络,我们想要对
A
4
A_4
A4的概率分布进行估计,而其它的参数我们都知道。

那么我们只需要计算出
P
(
A
4
∣
−
A
4
)
P(A_4|-A_4)
P(A4∣−A4)其中
−
A
4
-A_4
−A4表示出了
A
4
A_4
A4以外的其它所有已知随机变量。
我们对其进行化简,首先根据贝叶斯网络的定义,我们知道与
A
4
A_4
A4直接相连的一定与它有关。
于是就有
P
(
A
4
∣
−
A
4
)
=
P
(
A
4
∣
A
1
,
A
2
,
A
6
,
A
7
,
e
t
c
)
P(A_4|-A_4)=P(A_4|A_1, A_2, A_6, A_7, etc)
P(A4∣−A4)=P(A4∣A1,A2,A6,A7,etc)
其中
e
t
c
etc
etc表示其它与之相关的。
根据几大基本的贝叶斯网络的关系,我们可以得到
A
1
0
,
A
9
A_10, A_9
A10,A9也与
A
4
A_4
A4相关。
P
(
A
4
∣
−
A
4
)
=
P
(
A
4
∣
A
1
,
A
2
,
A
6
,
A
7
,
A
10
,
A
9
)
P(A_4|-A_4)=P(A_4|A_1, A_2, A_6, A_7, A_{10}, A_9)
P(A4∣−A4)=P(A4∣A1,A2,A6,A7,A10,A9)
那么问题来了,为什么?
因为,我们知道贝叶斯网络有一种特殊关系,如下图
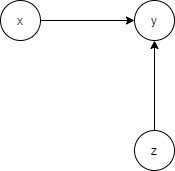
当我们知道
y
y
y时,x,z不独立。现在看我们的图,我们显然已经知道了
A
8
,
A
6
A_8, A_6
A8,A6了,所以此时
A
4
A_4
A4和
A
8
,
A
6
A_8, A_6
A8,A6的所有父亲节点都有关系。
总结一下就是,在贝叶斯网络中,一个节点和所有直接相连的节点,和其子节点的父节点有关系,与其它节点没有关系。
知道了这个之后,我们再看LDA的网络。

其中圆圈起来的是随机变量,方框并不是。
知道了这些之后,我们就可以正式的开始参数估计了。
对 θ \theta θ采样
由LDA的贝叶斯网络可以知道
P
(
θ
∣
−
θ
)
=
P
(
θ
∣
α
,
Z
)
P(\theta|-\theta)=P(\theta|\alpha, Z)
P(θ∣−θ)=P(θ∣α,Z)
这是一个后验概率,我们使用贝叶斯公式
P
(
θ
∣
α
,
Z
)
=
P
(
Z
∣
θ
,
α
)
P
(
θ
∣
α
)
P
(
Z
∣
α
)
P(\theta|\alpha, Z)=\frac{P(Z|\theta, \alpha)P(\theta|\alpha)}{P(Z|\alpha)}
P(θ∣α,Z)=P(Z∣α)P(Z∣θ,α)P(θ∣α)
我们依照网络关系对其进行化简
P
(
θ
∣
α
,
Z
)
=
P
(
Z
∣
θ
)
P
(
θ
∣
α
)
P
(
Z
)
P(\theta|\alpha, Z)=\frac{P(Z|\theta)P(\theta|\alpha)}{P(Z)}
P(θ∣α,Z)=P(Z)P(Z∣θ)P(θ∣α)
其中
P
(
Z
∣
θ
)
P(Z|\theta)
P(Z∣θ)服从多项式分布,
P
(
θ
∣
α
)
P(\theta|\alpha)
P(θ∣α)服从狄利克雷分布。
那么根据共轭先验,我们可以得到
P
(
θ
∣
α
,
Z
)
P(\theta|\alpha, Z)
P(θ∣α,Z)也服从狄利克雷分布。
根据共轭先验,记
θ
i
\theta_i
θi为第i偏文章的主体分布
θ
i
∣
α
,
Z
∼
D
i
r
(
α
+
(
n
1
,
n
2
,
.
.
.
,
n
k
)
)
\theta_i|\alpha,Z \thicksim Dir(\alpha+(n_1, n_2, ..., n_k))
θi∣α,Z∼Dir(α+(n1,n2,...,nk))
其中
(
n
1
,
n
2
,
n
3
,
.
.
.
,
n
k
)
(n_1, n_2, n_3,..., n_k)
(n1,n2,n3,...,nk)为第
i
i
i偏文章中,每个主题出现的次数。
具体推导过程和共轭先验的推导一致,所以就不再写了。
对 ϕ \phi ϕ采样
对
ϕ
\phi
ϕ的采样和对
θ
\theta
θ 的十分相似,首先我们写出条件概率分布,这里需要注意w也是和
ϕ
\phi
ϕ有关系的
P
(
ϕ
∣
β
,
w
,
Z
)
P(\phi|\beta,w,Z)
P(ϕ∣β,w,Z)
然后对其使用贝叶斯公式
P
(
ϕ
∣
β
,
w
,
Z
)
=
P
(
ϕ
,
w
∣
β
,
Z
)
P
(
w
∣
β
,
Z
)
=
P
(
w
∣
ϕ
,
β
,
Z
)
P
(
ϕ
∣
β
,
Z
)
P
(
w
∣
β
,
Z
)
P(\phi|\beta,w,Z)=\frac{P(\phi,w|\beta,Z)}{P(w|\beta,Z)}=\frac{P(w|\phi,\beta,Z) P(\phi|\beta,Z)}{P(w|\beta,Z)}
P(ϕ∣β,w,Z)=P(w∣β,Z)P(ϕ,w∣β,Z)=P(w∣β,Z)P(w∣ϕ,β,Z)P(ϕ∣β,Z)
然后化简
P
(
ϕ
∣
β
,
w
,
Z
)
=
P
(
ϕ
,
w
∣
β
,
Z
)
P
(
w
∣
β
,
Z
)
=
P
(
w
∣
ϕ
,
Z
)
P
(
ϕ
∣
β
)
P
(
w
∣
Z
)
P(\phi|\beta,w,Z)=\frac{P(\phi,w|\beta,Z)}{P(w|\beta,Z)}=\frac{P(w|\phi,Z) P(\phi|\beta)}{P(w|Z)}
P(ϕ∣β,w,Z)=P(w∣β,Z)P(ϕ,w∣β,Z)=P(w∣Z)P(w∣ϕ,Z)P(ϕ∣β)
关于
P
(
ϕ
∣
β
,
Z
)
P(\phi|\beta,Z)
P(ϕ∣β,Z)的Z为什么忽略掉了,是因为此时我们不知道w,只有在知道w时,Z才和
ϕ
\phi
ϕ有关系,否则它们独立。
那么此时
P
(
ϕ
∣
β
)
P(\phi|\beta)
P(ϕ∣β)服从狄利克雷分布,
P
(
w
∣
ϕ
,
Z
)
P(w|\phi,Z)
P(w∣ϕ,Z)服从多项式分布这明显又是一对共轭先验。
于是我们得到
ϕ
k
∣
β
,
w
,
Z
∼
D
i
r
(
β
+
(
n
1
,
n
2
,
.
.
.
,
n
v
)
)
\phi_k|\beta,w,Z\thicksim Dir(\beta+(n_1, n_2, ..., n_v))
ϕk∣β,w,Z∼Dir(β+(n1,n2,...,nv))
其中上式的
n
j
(
j
∈
{
1
,
2
,
.
.
.
,
v
}
)
n_j(j \in \{1, 2,..., v\})
nj(j∈{1,2,...,v})表示主题为k,单词为v的单词的个数。
对 Z Z Z采样
同样道理,我们首先我们写出Z的分布,并且使用贝叶斯公式
P
(
Z
∣
θ
,
w
,
ϕ
)
=
P
(
w
∣
Z
,
θ
,
ϕ
)
P
(
Z
∣
θ
,
ϕ
)
P
(
w
∣
θ
,
ϕ
)
∝
P
(
w
∣
Z
,
θ
,
ϕ
)
P
(
Z
∣
θ
,
ϕ
)
P(Z|\theta, w, \phi)=\frac{P(w|Z, \theta, \phi)P(Z|\theta, \phi)}{P(w|\theta,\phi)}\varpropto P(w|Z, \theta, \phi)P(Z|\theta, \phi)
P(Z∣θ,w,ϕ)=P(w∣θ,ϕ)P(w∣Z,θ,ϕ)P(Z∣θ,ϕ)∝P(w∣Z,θ,ϕ)P(Z∣θ,ϕ)
因为对于Z来说,分母都一样,所以我们可以不用关心,最后我们进行归一化即可。
然后依据LDA的贝叶斯网络进行化简
P
(
Z
∣
θ
,
w
,
ϕ
)
∝
P
(
w
∣
Z
,
ϕ
)
P
(
Z
∣
θ
)
P(Z|\theta, w, \phi)\varpropto P(w|Z, \phi)P(Z|\theta)
P(Z∣θ,w,ϕ)∝P(w∣Z,ϕ)P(Z∣θ)
然后我们写出分布,设我们要求的是
P
(
Z
i
j
=
k
∣
θ
i
,
w
i
j
,
ϕ
k
)
P(Z_{ij}=k|\theta_i, w_{ij}, \phi_k)
P(Zij=k∣θi,wij,ϕk)
就有
P
(
w
i
j
∣
Z
i
j
=
k
,
ϕ
k
)
P
(
Z
i
j
=
k
∣
θ
i
)
=
ϕ
k
w
i
j
∗
θ
i
k
P(w_{ij}|Z_{ij}=k, \phi_k)P(Z_{ij}=k|\theta_i)=\phi_{kw_{ij}} * \theta_{ik}
P(wij∣Zij=k,ϕk)P(Zij=k∣θi)=ϕkwij∗θik
然后我们按照k进行归一化,就可以得到Z的分布然后就可以进行进一步的采样。
至此LDA的吉布斯采样方法结束。
numpy实现
import numpy as np
class LDA:
def __init__(self, topics=8) -> None:
self.topics = topics
# 主题数目
def fit(self, docs, V, beta=1, alpha=1, iters=100):
self.D, self.V = len(docs), V
# D,V分别表示,文档数目,词典大小
# doc表示文档,其中每个文章已经实现转化为对应的标号
self.Z = {}
for i in range(self.D):
self.Z[i] = np.random.randint(low=0, high=self.topics, size=(len(docs[i]))) # 随机初始赋值
self.theta = np.zeros(shape=(self.D, self.topics))
self.phi = np.zeros(shape=(self.topics, self.V))
self.alpha = alpha
self.beta = beta
self.docs = np.array(docs)
for i in range(self.D):
self.theta[i] = np.random.dirichlet(alpha * np.ones(self.topics)) # 随机初始赋值
for i in range(self.topics):
self.phi[i] = np.random.dirichlet(beta * np.ones(self.V)) # 随机初始赋值
self.sample(iters)
def sample(self, inters):
for _ in range(inters): # 反复采样iters次
# 对Z进行重采样
for d in range(self.D):
for v in range(len(self.Z[d])): # 对于每个位置上的单词主题
tmp = np.exp(np.log(self.theta[d]) + np.log(self.phi[:, self.docs[d, v]])) # 求某个位置的主题分布,这么做是为了防止溢出
tmp /= tmp.sum() # 归一化,得到这个位置单词的主题分布
self.Z[d][v] = np.random.multinomial(1, tmp).argmax() # 进行采样
for i in range(self.D):
# 对theta进行采样
tmp = np.zeros(shape=(self.topics))
for j in range(self.topics):
tmp[j] = np.sum(self.Z[i] == j) # 文章i中,所有主题为j的出现的次数
self.theta[i] = np.random.dirichlet(self.alpha + tmp)
for k in range(self.topics):
tmp = np.zeros(shape=(self.V))
# 对phi进行采样
for v in range(self.V):
for i in range(self.D):
tmp[v] += np.sum((self.Z[i] == k) == (self.docs[i] == v))
self.phi[k] = np.random.dirichlet(self.beta + tmp)
我们进行一下测试
X = np.array([
[0, 0, 0, 0, 0],
[1, 1, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 1, 1],
[0, 0, 0, 0, 1],
])
model = LDA(2)
model.fit(X, 2, iters=500)
print(model.theta)
"""
输出:
[[0.27656992 0.72343008]
[0.78205677 0.21794323]
[0.47284058 0.52715942]
[0.32858845 0.67141155]
[0.19554842 0.80445158]]
"""
可以发现,全出现单词0和1的,都极度侧重于一个主题。
然后随着0和1的占比数目的变化,其主题的占比也在变化,这说明我们学到了其内部的规律。
collapsed gibbs sample
朴素的吉布斯采样的方法虽然好,但是采样的变量的个数太多了,真有有这个必要么?有没有采样个数少一点的算法。
其实是有的,他就是collapsed gibbs sample
collapsed gibbs sample的思想是先对Z进行估计,然后利用Z的估计结果对
ϕ
,
θ
\phi,\theta
ϕ,θ在进行估计。
对Z进进行估计时,我们隐含掉了
ϕ
,
θ
\phi,\theta
ϕ,θ,尝试直接通过
α
,
β
\alpha, \beta
α,β等参数进行采样估计。

并且我们对每个
Z
i
j
Z_{ij}
Zij进行估计时,假设其它的
Z
−
i
j
Z_{-ij}
Z−ij已知,其中
Z
−
i
j
Z_{-ij}
Z−ij表示除了
Z
i
j
Z_{ij}
Zij以外的所有其他的Z。
那么我们现在需要求的就是(为了后续式子不混淆,这里用ts替代ij)
P
(
Z
t
s
∣
Z
−
t
s
,
α
,
β
,
w
)
P(Z_{ts}|Z_{-ts},\alpha,\beta, w)
P(Zts∣Z−ts,α,β,w)
我们应用后验概率的公式
P
(
Z
t
s
∣
Z
−
t
s
,
α
,
β
,
w
)
=
P
(
Z
t
s
,
Z
−
t
s
,
w
∣
α
,
β
)
P
(
Z
−
t
s
,
w
∣
α
,
β
)
=
P
(
Z
,
w
∣
α
,
β
)
P
(
Z
−
t
s
,
w
∣
α
,
β
)
P(Z_{ts}|Z_{-ts},\alpha,\beta, w) = \frac{P(Z_{ts},Z_{-ts}, w|\alpha,\beta)}{P(Z_{-ts}, w|\alpha,\beta)}=\frac{P(Z, w|\alpha,\beta)}{P(Z_{-ts}, w|\alpha,\beta)}
P(Zts∣Z−ts,α,β,w)=P(Z−ts,w∣α,β)P(Zts,Z−ts,w∣α,β)=P(Z−ts,w∣α,β)P(Z,w∣α,β)
我们分别求这两项即可。首先我们先来求分子。
P
(
Z
,
w
∣
α
,
β
)
=
P
(
w
∣
Z
,
α
,
β
)
P
(
Z
∣
α
,
β
)
=
P
(
w
∣
Z
,
β
)
P
(
Z
∣
α
)
P(Z, w|\alpha,\beta)=P(w|Z,\alpha,\beta)P(Z|\alpha,\beta)=P(w|Z,\beta)P(Z|\alpha)
P(Z,w∣α,β)=P(w∣Z,α,β)P(Z∣α,β)=P(w∣Z,β)P(Z∣α)
上面的两个条件的省略一个是根据概率图,一个是根据Z已知,所以不需要
α
\alpha
α
到了,这里我们依然十分不好求,此时我们就需要借助被我们隐含掉的
θ
,
ϕ
\theta,\phi
θ,ϕ的帮助
P
(
w
∣
Z
,
β
)
P
(
Z
∣
α
)
=
∫
θ
P
(
Z
,
θ
∣
α
)
d
θ
∫
ϕ
P
(
w
,
ϕ
∣
Z
,
β
)
d
ϕ
P(w|Z,\beta)P(Z|\alpha)= \int_\theta P(Z,\theta|\alpha)d\theta \int_\phi P(w,\phi|Z,\beta)d\phi
P(w∣Z,β)P(Z∣α)=∫θP(Z,θ∣α)dθ∫ϕP(w,ϕ∣Z,β)dϕ
我们把这两个积分,一个记做A,一个记做B,接下来我们就需要对他们进行求解。
先来看A
∫
θ
P
(
Z
,
θ
∣
α
)
d
θ
=
∫
θ
P
(
Z
∣
θ
)
P
(
θ
∣
α
)
d
θ
\int_\theta P(Z,\theta|\alpha)d\theta=\int_\theta P(Z|\theta)P(\theta|\alpha)d\theta
∫θP(Z,θ∣α)dθ=∫θP(Z∣θ)P(θ∣α)dθ
这两个分布可以说是老熟人了,一个是多项分布,一个是狄利克雷分布,我们挨个写出它们
P
(
Z
∣
θ
)
=
∏
i
=
1
D
∏
j
=
1
∣
D
i
∣
∏
k
=
1
K
θ
i
j
I
(
Z
i
j
=
k
)
P(Z|\theta)=\prod_{i = 1}^D\prod_{j=1}^{|D_{i}|}\prod_{k = 1}^K\theta_{ij}^{I(Z_{ij}=k)}
P(Z∣θ)=i=1∏Dj=1∏∣Di∣k=1∏KθijI(Zij=k)
P
(
θ
∣
α
)
=
∏
i
=
1
D
1
B
(
α
)
∏
k
=
1
K
θ
i
j
α
i
−
1
P(\theta|\alpha)=\prod_{i = 1}^D\frac{1}{B(\alpha)}\prod_{k=1}^K\theta^{\alpha_i -1}_{ij}
P(θ∣α)=i=1∏DB(α)1k=1∏Kθijαi−1
我们带入A式中
∫
θ
P
(
Z
∣
θ
)
P
(
θ
∣
α
)
d
θ
=
∫
θ
∏
i
=
1
D
∏
j
=
1
∣
D
i
∣
∏
k
=
1
K
θ
i
j
I
(
Z
i
j
=
k
)
∏
i
=
1
D
1
B
(
α
)
∏
k
=
1
K
θ
i
j
α
i
−
1
d
θ
\int_\theta P(Z|\theta)P(\theta|\alpha)d\theta=\int_\theta \prod_{i = 1}^D\prod_{j=1}^{|D_{i}|}\prod_{k = 1}^K\theta_{ij}^{I(Z_{ij}=k)}\prod_{i = 1}^D\frac{1}{B(\alpha)}\prod_{k=1}^K\theta^{\alpha_i -1}_{ij} d\theta
∫θP(Z∣θ)P(θ∣α)dθ=∫θi=1∏Dj=1∏∣Di∣k=1∏KθijI(Zij=k)i=1∏DB(α)1k=1∏Kθijαi−1dθ
这里的
θ
\theta
θ是一个向量,而对于每两个文档之间是相互无关的,且是乘积关系,积分区域都是0-1所以我们可以把乘积的积分写成积分的乘积
∫
θ
P
(
Z
∣
θ
)
P
(
θ
∣
α
)
d
θ
=
∏
i
=
1
D
∫
θ
∏
j
=
1
∣
D
i
∣
∏
k
=
1
K
θ
i
j
I
(
Z
i
j
=
k
)
1
B
(
α
)
∏
k
=
1
K
θ
i
j
α
i
−
1
d
θ
\int_\theta P(Z|\theta)P(\theta|\alpha)d\theta=\prod_{i = 1}^D\int_\theta \prod_{j=1}^{|D_{i}|}\prod_{k = 1}^K\theta_{ij}^{I(Z_{ij}=k)}\frac{1}{B(\alpha)}\prod_{k=1}^K\theta^{\alpha_i -1}_{ij} d\theta
∫θP(Z∣θ)P(θ∣α)dθ=i=1∏D∫θj=1∏∣Di∣k=1∏KθijI(Zij=k)B(α)1k=1∏Kθijαi−1dθ
我们交换前半部分的j和k的积分位置,然后把j的乘积项写到指数上去
∫
θ
P
(
Z
∣
θ
)
P
(
θ
∣
α
)
d
θ
=
∏
i
=
1
D
∫
θ
∏
k
=
1
K
θ
i
j
∑
j
=
1
∣
D
i
∣
I
(
Z
i
j
=
k
)
1
B
(
α
)
∏
k
=
1
K
θ
i
j
α
i
−
1
d
θ
\int_\theta P(Z|\theta)P(\theta|\alpha)d\theta=\prod_{i = 1}^D\int_\theta \prod_{k = 1}^K\theta_{ij}^{\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=k)}\frac{1}{B(\alpha)}\prod_{k=1}^K\theta^{\alpha_i -1}_{ij} d\theta
∫θP(Z∣θ)P(θ∣α)dθ=i=1∏D∫θk=1∏Kθijj=1∑∣Di∣I(Zij=k)B(α)1k=1∏Kθijαi−1dθ
然后我们对两个K的连乘进行合并,并且把常数项B(a)移出
∫
θ
P
(
Z
∣
θ
)
P
(
θ
∣
α
)
d
θ
=
∏
i
=
1
D
1
B
(
α
)
∫
θ
∏
k
=
1
K
θ
i
j
∑
j
=
1
∣
D
i
∣
I
(
Z
i
j
=
k
)
+
α
i
−
1
d
θ
\int_\theta P(Z|\theta)P(\theta|\alpha)d\theta=\prod_{i = 1}^D\frac{1}{B(\alpha)}\int_\theta \prod_{k = 1}^K\theta_{ij}^{\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=k) + \alpha_i -1} d\theta
∫θP(Z∣θ)P(θ∣α)dθ=i=1∏DB(α)1∫θk=1∏Kθijj=1∑∣Di∣I(Zij=k)+αi−1dθ
根据beta函数的定义,我们可以发现,后面这一大坨就是bata函数。
∫
θ
P
(
Z
∣
θ
)
P
(
θ
∣
α
)
d
θ
=
∏
i
=
1
D
B
(
a
1
+
∑
j
=
1
∣
D
i
∣
I
(
Z
i
j
=
1
)
.
.
.
,
a
K
+
∑
j
=
1
∣
D
i
∣
I
(
Z
i
j
=
K
)
)
B
(
α
)
\int_\theta P(Z|\theta)P(\theta|\alpha)d\theta=\prod_{i = 1}^D\frac{B(a_1+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=1)..., a_K+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K))}{B(\alpha)}
∫θP(Z∣θ)P(θ∣α)dθ=i=1∏DB(α)B(a1+j=1∑∣Di∣I(Zij=1)...,aK+j=1∑∣Di∣I(Zij=K))
接下来我们推导式子B
∫
ϕ
P
(
w
,
ϕ
∣
Z
,
β
)
d
ϕ
=
∫
ϕ
P
(
w
∣
Z
,
ϕ
)
P
(
ϕ
∣
β
)
d
ϕ
\int_\phi P(w,\phi|Z,\beta)d\phi=\int_\phi P(w|Z,\phi)P(\phi|\beta)d\phi
∫ϕP(w,ϕ∣Z,β)dϕ=∫ϕP(w∣Z,ϕ)P(ϕ∣β)dϕ
依然是根据那些性质,我们省去了不必要的条件。
然后我们写出两个分布,一个是多项分布,一个是狄利克雷分布
P ( w ∣ Z , ϕ ) = ∏ k = 1 K ∏ i , j : Z i j = k ∏ v = 1 V ϕ i j w i j = v P(w|Z,\phi)=\prod\limits_{k = 1}^K\prod\limits_{i,j:Z_{ij=k}}\prod\limits_{v=1}^V\phi_{ij}^{w_{ij}=v} P(w∣Z,ϕ)=k=1∏Ki,j:Zij=k∏v=1∏Vϕijwij=v
P ( ϕ ∣ β ) = ∏ i = 1 K 1 B ( β ) ∏ v = 1 V ϕ k v β v − 1 P(\phi|\beta)=\prod\limits_{i=1}^K\frac{1}{B(\beta)}\prod\limits_{v=1}^V\phi_{kv}^{\beta_{v} - 1} P(ϕ∣β)=i=1∏KB(β)1v=1∏Vϕkvβv−1
然后又是同样的技巧,带入,乘积的积分变积分的乘积
∫ ϕ P ( w , ϕ ∣ Z , β ) d ϕ = ∏ k = 1 K ∫ ϕ ∏ i , j : Z i j = k ∏ v = 1 V ϕ i j I ( w i j = v ) 1 B ( β ) ∏ v = 1 V ϕ k v β v − 1 d ϕ \int_\phi P(w,\phi|Z,\beta)d\phi=\prod\limits_{k = 1}^K\int_\phi\prod\limits_{i,j:Z_{ij}=k}\prod\limits_{v=1}^V\phi_{ij}^{I(w_{ij}=v)}\frac{1}{B(\beta)}\prod\limits_{v=1}^V\phi_{kv}^{\beta_{v} - 1}d\phi ∫ϕP(w,ϕ∣Z,β)dϕ=k=1∏K∫ϕi,j:Zij=k∏v=1∏VϕijI(wij=v)B(β)1v=1∏Vϕkvβv−1dϕ
然后交换位置,连乘变指数连加
∫ ϕ P ( w , ϕ ∣ Z , β ) d ϕ = ∏ k = 1 K 1 B ( β ) ∫ ϕ ∏ v = 1 V ϕ i j ∑ i , j : Z i j = k I ( w i j = v ) + β v − 1 d ϕ \int_\phi P(w,\phi|Z,\beta)d\phi=\prod\limits_{k = 1}^K\frac{1}{B(\beta)}\int_\phi\prod\limits_{v=1}^V\phi_{ij}^{\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=v) + \beta_{v} - 1}d\phi ∫ϕP(w,ϕ∣Z,β)dϕ=k=1∏KB(β)1∫ϕv=1∏Vϕiji,j:Zij=k∑I(wij=v)+βv−1dϕ
然后我们也用beta函数来表示
∫ ϕ P ( w , ϕ ∣ Z , β ) d ϕ = ∏ k = 1 K B ( ∑ i , j : Z i j = k I ( w i j = 1 ) + β 1 ) , . . . , ∑ i , j : Z i j = k I ( w i j = V ) + β V ) B ( β ) d ϕ \int_\phi P(w,\phi|Z,\beta)d\phi=\prod\limits_{k = 1}^K\frac{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=1) + \beta_{1}),..., \sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=V) + \beta_{V})}{B(\beta)}d\phi ∫ϕP(w,ϕ∣Z,β)dϕ=k=1∏KB(β)B(i,j:Zij=k∑I(wij=1)+β1),...,i,j:Zij=k∑I(wij=V)+βV)dϕ
最后我们把两个式子合并
得到
P ( Z , w ∣ α , β ) = ∏ i = 1 D B ( a 1 + ∑ j = 1 ∣ D i ∣ I ( Z i j = 1 ) . . . , a K + ∑ j = 1 ∣ D i ∣ I ( Z i j = K ) ) B ( α ) ∏ k = 1 K B ( ∑ i , j : Z i j = k I ( w i j = 1 ) + β 1 ) , . . . , ∑ i , j : Z i j = k I ( w i j = V ) + β V ) B ( β ) P(Z, w|\alpha,\beta)=\prod\limits_{i = 1}^D\frac{B(a_1+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=1)..., a_K+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K))}{B(\alpha)}\prod\limits_{k = 1}^K\frac{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=1) + \beta_{1}),..., \sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=V) + \beta_{V})}{B(\beta)} P(Z,w∣α,β)=i=1∏DB(α)B(a1+j=1∑∣Di∣I(Zij=1)...,aK+j=1∑∣Di∣I(Zij=K))k=1∏KB(β)B(i,j:Zij=k∑I(wij=1)+β1),...,i,j:Zij=k∑I(wij=V)+βV)
我们分子求完了,然后是分母,我们观察分母,其实就是比分子少了个 t s ts ts所以我们对分子进行稍加的改变就得到分母
我们给所有出现 Z i j Z_{ij} Zij的地方机上一个条件,即 i j ! = t s ij!=ts ij!=ts,我们就得到了分母
P ( Z − t s , w ∣ α , β ) = ∏ i = 1 D B ( a 1 + ∑ j = 1 ∣ D i ∣ I ( Z i j = 1 & i j ! = t s ) . . . , a K + ∑ j = 1 ∣ D i ∣ I ( Z i j = K & i j ! = t s ) ) B ( α ) ∏ k = 1 K B ( ∑ i , j : Z i j = k I ( w i j = 1 & i j ! = t s ) + β 1 ) , . . . , ∑ i , j : Z i j = k I ( w i j = V & i j ! = t s ) + β V ) B ( β ) P(Z_{-ts}, w|\alpha,\beta)=\prod\limits_{i = 1}^D\frac{B(a_1+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=1\& ij!=ts)..., a_K+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K \& ij!=ts))}{B(\alpha)}\prod\limits_{k = 1}^K\frac{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=1\& ij!=ts) + \beta_{1}),..., \sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=V\& ij!=ts) + \beta_{V})}{B(\beta)} P(Z−ts,w∣α,β)=i=1∏DB(α)B(a1+j=1∑∣Di∣I(Zij=1&ij!=ts)...,aK+j=1∑∣Di∣I(Zij=K&ij!=ts))k=1∏KB(β)B(i,j:Zij=k∑I(wij=1&ij!=ts)+β1),...,i,j:Zij=k∑I(wij=V&ij!=ts)+βV)
然后我们两项相除,分母就全部消掉了,为了表示方便,我们把向量
( ∑ j = 1 ∣ D i ∣ I ( Z i j = 1 & i j ! = t s ) , . . , ∑ j = 1 ∣ D i ∣ I ( Z i j = K & i j ! = t s ) ) (\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=1 \& ij!=ts), .., \sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K \& ij!=ts)) (j=1∑∣Di∣I(Zij=1&ij!=ts),..,j=1∑∣Di∣I(Zij=K&ij!=ts))记为 ∑ j = 1 ∣ D i ∣ I ( Z i j = K & i j ! = t s ) \sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K \& ij!=ts) j=1∑∣Di∣I(Zij=K&ij!=ts)类似的也这么做
就得到
P ( Z t s ∣ Z − t s , α , β , w ) = ∏ i = 1 D B ( a + ∑ j = 1 ∣ D i ∣ I ( Z i j = K ) B ( a + ∑ j = 1 ∣ D i ∣ I ( Z i j = K & i j ! = t s ) ) ∏ k = 1 K B ( ∑ i , j : Z i j = k I ( w i j = V ) + β ) B ( ∑ i , j : Z i j = k I ( w i j = V & i j ! = t s ) + β ) P(Z_{ts}|Z_{-ts},\alpha,\beta, w)=\prod\limits_{i = 1}^D\frac{B(a+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K)}{B(a+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K\& ij!=ts))}\prod\limits_{k = 1}^K\frac{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=V) + \beta)}{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=V\& ij!=ts) + \beta)} P(Zts∣Z−ts,α,β,w)=i=1∏DB(a+j=1∑∣Di∣I(Zij=K&ij!=ts))B(a+j=1∑∣Di∣I(Zij=K)k=1∏KB(i,j:Zij=k∑I(wij=V&ij!=ts)+β)B(i,j:Zij=k∑I(wij=V)+β)
然后就是最终的变换了,根据beta函数的gamma函数表示形式,我们可以对其进行拆解。
B ( a , b ) = Γ ( a ) + Γ ( b ) Γ ( a + b ) B(a,b)=\frac{\Gamma(a) + \Gamma(b)}{\Gamma(a+b)} B(a,b)=Γ(a+b)Γ(a)+Γ(b)
然后就会发现,对于分子分母来说,只有少了ts的那个 Γ \Gamma Γ函数不会被消掉,其它的都会被消掉。
并且对于gamma函数来说有 Γ ( x + 1 ) = x Γ ( x ) \Gamma(x + 1)=x\Gamma(x) Γ(x+1)=xΓ(x)因为gamma函数本质就是阶乘的拓展。而为我们知道由于少了ts这一项,分子与分母的和的差是1所以我们可以把分子和分母几乎全部都消掉。
设 n t i n_{ti} nti表示为第t个文档中,Z取值为i的个数
设 n t i ′ n'_{ti} nti′表示为第t个文档中,不包括 Z t s Z_{ts} Zts的所有Z中,Z取值为i的个数
于是可以得到
∏ i = 1 D B ( a + ∑ j = 1 ∣ D i ∣ I ( Z i j = K ) ) B ( a + ∑ j = 1 ∣ D i ∣ I ( Z i j = K & i j ! = t s ) ) = ∏ i = 1 D ∏ k = 1 K Γ ( α k + n i k ) Γ ( ∑ i = 1 K ( α k + n i k ) ) ⋅ Γ ( ∑ i = 1 K ( α k + n i k ′ ) ) ∏ k = 1 K Γ ( α k + n i k ′ ) \prod\limits_{i = 1}^D\frac{B(a+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K))}{B(a+\sum\limits_{j=1}^{|D_i|} I(Z_{ij}=K\& ij!=ts))}=\prod\limits_{i=1}^D\frac{\prod\limits_{k=1}^{K}\Gamma(\alpha_k+n_{ik})}{\Gamma(\sum\limits_{i=1}^K(\alpha_k+n_{ik}))}\cdot\frac{\Gamma(\sum\limits_{i=1}^K(\alpha_k+n'_{ik}))}{\prod\limits_{k=1}^{K}\Gamma(\alpha_k+n'_{ik})} i=1∏DB(a+j=1∑∣Di∣I(Zij=K&ij!=ts))B(a+j=1∑∣Di∣I(Zij=K))=i=1∏DΓ(i=1∑K(αk+nik))k=1∏KΓ(αk+nik)⋅k=1∏KΓ(αk+nik′)Γ(i=1∑K(αk+nik′))
我们知道ts只存在其中的某个文档中,所以除了某个文档之外的其他所有项都会被消掉,而我们知道不算入ts的那个项的和比算入的的少1,根据gamma函数的性质 Γ ( x + 1 ) = x Γ ( x ) \Gamma(x + 1)=x\Gamma(x) Γ(x+1)=xΓ(x)我们也可以进行轻松地约分。
∏ i = 1 D ∏ k = 1 K Γ ( α k + n i k ) Γ ( ∑ i = 1 K ( α k + n i k ) ) ⋅ Γ ( ∑ i = 1 K ( α k + n i k ′ ) ) ∏ k = 1 K Γ ( α k + n i k ′ ) = n t Z t s + α Z t s − 1 ∑ k = 1 K ( α k + n t k ) − 1 \prod\limits_{i=1}^D\frac{\prod\limits_{k=1}^{K}\Gamma(\alpha_k+n_{ik})}{\Gamma(\sum\limits_{i=1}^K(\alpha_k+n_{ik}))}\cdot\frac{\Gamma(\sum\limits_{i=1}^K(\alpha_k+n'_{ik}))}{\prod\limits_{k=1}^{K}\Gamma(\alpha_k+n'_{ik})}=\frac{n_{tZ_{ts}}+\alpha_{Z_{ts}}-1}{\sum\limits_{k=1}^K(\alpha_k+n_{tk})-1} i=1∏DΓ(i=1∑K(αk+nik))k=1∏KΓ(αk+nik)⋅k=1∏KΓ(αk+nik′)Γ(i=1∑K(αk+nik′))=k=1∑K(αk+ntk)−1ntZts+αZts−1
我们进行进一步的化简,注意到 ∑ i = 1 K n t k \sum_{i=1}^Kn_{tk} ∑i=1Kntk其实就是文章t的单词总数,所以我们记 n t n_t nt为文章t的单词总数减一,并且用 n t ′ Z t s n_t'{Z_{ts}} nt′Zts代替 n t Z t s − 1 n_t{Z_{ts}}-1 ntZts−1
得到
n t Z t s ′ + α Z t s ∑ k = 1 K α k + n t \frac{n'_{tZ_{ts}}+\alpha_{Z_{ts}}}{\sum\limits_{k=1}^K\alpha_k + n_t} k=1∑Kαk+ntntZts′+αZts
同样道理对于第二个连乘
∏ k = 1 K B ( ∑ i , j : Z i j = k I ( w i j = K ) + β ) B ( ∑ i , j : Z i j = k I ( w i j = K & i j ! = t s ) + β ) \prod\limits_{k = 1}^K\frac{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=K) + \beta)}{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=K\& ij!=ts) + \beta)} k=1∏KB(i,j:Zij=k∑I(wij=K&ij!=ts)+β)B(i,j:Zij=k∑I(wij=K)+β)
我们也可以进行永gamma函数表示,然后进行约分,这里就不再多写了直接给出结果
∏ k = 1 K B ( ∑ i , j : Z i j = k I ( w i j = V ) + β ) B ( ∑ i , j : Z i j = k I ( w i j = V & i j ! = t s ) + β ) = β s + m w t s Z t s ∑ i = 1 V β i + m Z t s \prod\limits_{k = 1}^K\frac{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=V) + \beta)}{B(\sum\limits_{i,j:Z_{ij}=k} I(w_{ij}=V\& ij!=ts) + \beta)}=\frac{\beta_{s}+m_{w_{ts}Z_{ts}}}{\sum\limits_{i=1}^V\beta_i + m_{Z_{ts}}} k=1∏KB(i,j:Zij=k∑I(wij=V&ij!=ts)+β)B(i,j:Zij=k∑I(wij=V)+β)=i=1∑Vβi+mZtsβs+mwtsZts
其中 m Z t s m_{Z_{ts}} mZts表示所有的文档中有多少个主题为 Z t s Z_{ts} Zts 的, m Z t s w t s m_{Z_{ts}w_{ts}} mZtswts表示所有文章中,主题为 Z t s Z_{ts} Zts并且单词为 W i j W_{ij} Wij的单词的个数。
于是我们得到了
P ( Z t s ∣ Z − t s , α , β , w ) = n t Z t s ′ + α Z t s ∑ k = 1 K α k + n t β s + m w t s Z t s ∑ i = 1 V β i + m Z t s P(Z_{ts}|Z_{-ts},\alpha,\beta, w)=\frac{n'_{tZ_{ts}}+\alpha_{Z_{ts}}}{\sum\limits_{k=1}^K\alpha_k + n_t}\frac{\beta_{s}+m_{w_{ts}Z_{ts}}}{\sum\limits_{i=1}^V\beta_i + m_{Z_{ts}}} P(Zts∣Z−ts,α,β,w)=k=1∑Kαk+ntntZts′+αZtsi=1∑Vβi+mZtsβs+mwtsZts
然后我们依次计算
P ( Z t s = 1 ∣ Z − t s , α , β , w ) , P ( Z t s = 2 ∣ Z − t s , α , β , w ) . . . P(Z_{ts}=1|Z_{-ts},\alpha,\beta, w), P(Z_{ts}=2|Z_{-ts},\alpha,\beta, w)... P(Zts=1∣Z−ts,α,β,w),P(Zts=2∣Z−ts,α,β,w)...
最后在归一化即可得到概率分布,然后进行采样。
好了,现在已经估计出Z了,那么接卸来就只需要对Z进行统计就可以得出 ϕ , θ \phi,\theta ϕ,θ了,具体来说有
θ i j = n i j + α j ∑ k = 1 K α k + n t \theta_{ij}=\frac{n_{ij} + \alpha_j}{\sum\limits_{k=1}^K\alpha_k + n_t } θij=k=1∑Kαk+ntnij+αj
ϕ i j = m i j + β j ∑ i = 1 V β i + m j \phi_{ij}=\frac{m_{ij} + \beta_j}{\sum\limits_{i=1}^V\beta_i +m_j} ϕij=i=1∑Vβi+mjmij+βj
numpy代码实现
class LDA:
def __init__(self, topics) -> None:
self.K = topics
def fit(self, docs, V, alpha=0.1, beta=0.1, iter=100):
self.V, self.beta, self.iter, self.alpha = V, beta, iter, alpha
self.docs, self.D = docs, len(docs)
self.collapse_gibbs_sample()
def collapse_gibbs_sample(self):
self.__paras_init()
self.__sample()
self.__update_paras()
def __paras_init(self):
self.phi = np.zeros(shape=(self.K, self.V))
self.theta = np.zeros(shape=(self.D, self.K))
self.Z = []
self.n_w = np.zeros(shape=(self.D), dtype=np.int32) # 第i篇文章的单词个数
self.n_tp_w = np.zeros(shape=(self.D, self.K), dtype=np.int32) # 第i篇文章中主题为j的单词个数
self.m = np.zeros(shape=(self.K), dtype=np.int32) # 所有文章中主题为i的词的个数
self.m_w_tp = np.zeros(shape=(self.K, self.V), dtype=np.int32) # 所有文章中,主题为i,单词为j的个数
for i in range(self.D): # 初始化所有参数
self.n_w[i] = len(self.docs[i])
self.Z.append([0] * int(self.n_w[i]))
for j in range(self.n_w[i]): # 初始化参数,并且统计上述参数
self.Z[i][j] = np.random.randint(low=0, high=self.K)
self.n_tp_w[i][self.Z[i][j]] += 1
self.m[self.Z[i][j]] += 1
self.m_w_tp[self.Z[i][j]][self.docs[i][j]] += 1
def __sample(self):
for _ in range(self.iter):
for i in range(self.D):
for j in range(self.n_w[i]):
self.__sample_Z_ij(i, j)
def __sample_Z_ij(self, d, w): # 采样某个Z_ij
# 首先减去1
old_k = self.Z[d][w]
self.n_tp_w[d][old_k] -= 1
self.m[old_k] -= 1
self.m_w_tp[old_k][self.docs[d][w]] -= 1
self.n_w[d] -= 1
p = np.zeros(shape=(self.K))
for z in range(self.K):
p[z] = (self.alpha + self.n_tp_w[d][z]) / (self.K * self.alpha + self.n_w[d])\
* (self.beta + self.m_w_tp[z][self.docs[d][w]]) / (self.beta * self.K + self.m[z])
p /= np.sum(p) # 归一化
new_k = np.random.multinomial(1, p).argmax()
# 然后把心估计的Z加上去
self.n_tp_w[d][new_k] += 1
self.m[new_k] += 1
self.m_w_tp[new_k][self.docs[d][w]] += 1
self.n_w[d] += 1
self.Z[d][w] = new_k
def __update_paras(self): # 对phi和theta进行统计估计
for i in range(self.D):
for j in range(self.K):
self.theta[i][j] = (self.n_tp_w[i][j] + self.alpha) / (self.n_w[i] + self.K * self.alpha)
for i in range(self.K):
for j in range(self.V):
self.phi[i][j] = (self.m_w_tp[i][j] + self.beta) / (self.m[i] + self.K * self.beta)
X = np.array([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1],
])
model = LDA(2)
model.fit(X, 2, iter=500)
print(model.theta)
"""
[[0.00980392 0.99019608]
[0.99019608 0.00980392]
[0.79411765 0.20588235]
[0.5 0.5 ]
[0.20588235 0.79411765]]
"""
可以发现,collapsed gibbs sample 也出色的完成了任务,就结果来看比gibbs sample好要更好
变分推断
咕咕咕咕 ,等有时间再写吧
gensim的LDA
gensim中提供了很多高质量的模型,而LDA也在其中。
首先导入gensim的LDA
from gensim.models.ldamodel import LdaModel
要使用LdaModel至少传入两个参数,一个是corpus一个数num_topics即语料库和主题数目
这里我用了自己的语料库,然后进行了简单的处理
from gensim.corpora.dictionary import Dictionary
from gensim.models.ldamodel import LdaModel
from gensim.parsing.preprocessing import remove_stopwords, strip_non_alphanum, strip_short
import pandas as pd
from time import time
df = pd.read_csv('yelp.csv')['text']
gensim.parsing.preprocessing.STOPWORDS = gensim.parsing.preprocessing.STOPWORDS.union(['good', 'like', 'know', 'place']) # 添加一些新的停用词
corpus = [strip_short(remove_stopwords(strip_non_alphanum(df[i].strip().lower())), minsize=3) for i in range(len(df))] # 转为小写,去掉符号,去停用词,删去等于1的字符
corpus = [list(filter(lambda x: len(x), content.split())) for content in corpus] # 切分,删去空字符
diction = Dictionary(corpus) # 创建字典
corpus = [diction.doc2bow(text) for text in corpus] # 把文章变为bag of words表示
然后我们训练LDA,并且可以使用print_topic方法打印出对应的 ϕ \phi ϕ
print('-----training-----')
a = time()
lda = LdaModel(corpus=corpus, id2word=diction, num_topics=40, iterations=100)
print('训练用时 {}'.format(time() - a))
for i in range(5):
print(lda.print_topic(i, topn=6))
"""
0.022*"thai" + 0.010*"best" + 0.009*"curry" + 0.009*"food" + 0.008*"beef" + 0.008*"delicious"
0.022*"gym" + 0.014*"fitness" + 0.012*"courtyard" + 0.011*"slaw" + 0.010*"cole" + 0.009*"mimi"
0.034*"food" + 0.010*"mexican" + 0.009*"time" + 0.008*"little" + 0.007*"restaurant" + 0.007*"try"
0.017*"com" + 0.016*"www" + 0.016*"http" + 0.010*"yelp" + 0.009*"select" + 0.007*"locker"
0.020*"beer" + 0.010*"night" + 0.007*"movie" + 0.006*"coffee" + 0.006*"seats" + 0.006*"downtown"
"""
可以看到,每个主题的对应的 ϕ \phi ϕ都被打印出来了,第一个主题可能和饮食相关,第二个可能和健身有关,第三个可能和餐馆有关,第四个可能和网站有关,第五个可能与电影等娱乐休闲有关。
我们还可以使用LdaModel进行新数据的预测
pred = lda[corpus[0]]
print(pred)
"""
[(5, 0.29647768), (14, 0.29408976), (15, 0.048572015), (16, 0.30326793), (24, 0.02220891), (28, 0.023255143)]
"""
预测的结果是主题的分布,即 θ \theta θ















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









