






给定一个带权有向图G=(V,E),其中每条边的权是一个实数。另外,还给定V中的一个顶点,称为源。要计算从源到其他所有各顶点的最短路径长度。这里的长度就是指路上各边权之和。这个问题通常称为单源最短路径问题。
1.Floyd
Floyd是一种用于寻找图中每一对定点之间最短路径的算法。核心思想是对于每一对顶点u和v,寻找是否存在一个顶点w,使得从u到w再到v比已知的路径更短,如果是则更新它。
时间复杂度O(n3)

m, n = map(int, input().split())
graph = [[False] * m for _ in range(m)]
for _ in range(n):
i, j, value = map(int, input().split())
graph[i][j] = value
graph[j][i] = value
def floyd(graph):
for k in range(len(graph)): # 更新次数
# 以下两层循环为遍历矩阵每个元素,根据递推关系更新每两个节点之间的路径权值
for i in range(len(graph) - 1, -1, -1):
for j in range(len(graph)):
if graph[i][k] and graph[k][j] and (not graph[i][j] or graph[i][k] + graph[k][j] < graph[i][j]):
graph[i][j] = graph[i][k] + graph[k][j]
floyd(graph)
print(graph)
'''
6 8
0 1 3
0 3 2
1 2 1
2 3 8
2 4 12
3 4 3
3 5 4
4 5 2
'''
# out: [[4, 3, 4, 2, 5, 6], [3, 2, 1, 5, 8, 9], [4, 1, 2, 6, 9, 10], [2, 5, 6, 4, 3, 4], [5, 8, 9, 3, 4, 2], [6, 9, 10, 4, 2, 4]]
2.最小生成树
问题描述:
输入:
第一行输入两个整数,分别表示节点数m、边数n
接下来总共有n行,每一行有三个数,前两个表示相连的节点编号(0,1,2,...,n),最后一个数表示该边的权重值
输出:
一个整数,表示将所有点连起来权重的最小值。
示例:
输入:
9 15
0 1 3
0 5 4
1 2 8
1 6 6
1 8 5
2 8 2
2 3 12
3 8 11
3 6 14
3 7 6
3 4 10
4 7 1
4 5 18
5 6 7
6 7 9
输出:
36 # path: [(4, 7), (2, 8), (0, 1), (0, 5), (1, 8), (1, 6), (3, 7), (6, 7)]
克鲁斯卡尔算法(Kruskal)
1.对边集合进行排序;
2.选择最小权值边,若不构成环,则添加到集合边A中;
3.重复执行步骤2,直到添加|V| - 1 条边。
Kruskal基于边操作,适用于边少点多的场景,多用邻接表存储。
时间复杂度:O(ElogE) or O(ElogV)
m, n = map(int, input().split())
a = [[] for _ in range(n)]
for i in range(n):
a[i] = list(map(int, input().split())) # 邻接表存储
a.sort(key = lambda x: x[2])
res = 0
path = []
def find(father, f):
while father[f] > 0:
f = father[f]
return f
father = {i : 0 for i in range(m)} # 注意:字典的键是不可变的,可以是数字、字符串、元组,但不能为列表!!!
for i in range(n):
node1 = find(father, a[i][0])
node2 = find(father, a[i][1])
if node1 != node2:
father[node1] = node2
res += a[i][2]
path.append((a[i][0], a[i][1]))
if len(path) == m - 1: break
print(res)
print(path)
Prim算法
Kruskal算法的过程为不断对子图进行合并,直到形成最终的最小生成树。Prim算法的过程则是只存在一个子图,
不断选择顶点加入到该子图中,即通过对子图进行扩张,直到形成最终的最小生成树。
算法过程如下:
1.按照距离子图的远近,对顶点集合进行排序;
2.选择最近的顶点加入到子图中,并更新相邻顶点对子图的距离;
3.重复步骤2,直到顶点集合为空。
prim基于顶点操作,适用于点少边多的场景,多用邻接矩阵存储.
时间复杂度:O(n**2)
m, n = map(int, input().split())
a = [[float('inf')] * m for _ in range(m)] # 用邻接矩阵存储,Kruskal是邻接表存储!!!
for _ in range(n):
i, j, v = map(int, input().split())
a[i][j] = v
a[j][i] = v
res, path = 0, []
print(a)
# weightE保存相关顶点间边的权值, V保存相关顶点下标
weightE, V = [0] * m, [0] * m
#将V0作为最小生成树的根开始遍历,权值为0
for i in range(1, m):
weightE[i] = a[0][i] # 将邻接矩阵第0行所有权值先加入数组
# 真正构造最小生成树的过程
for i in range(1, m):
min_w = float('inf')
j, k = 1, 0
while j < m: # 遍历全部顶点
if weightE[j] and weightE[j] < min_w:
min_w = weightE[j]
k = j
j += 1
res += a[V[k]][k]
path.append([V[k], k])
weightE[k] = 0 # 将当前顶点的权值设置为0,表示此顶点已经完成任务,进行下一个顶点的遍历
for j in range(1, m):
if weightE[j] and a[k][j] < weightE[j]:
weightE[j] = a[k][j]
V[j] = k
print(res)
print(path)
3.迪杰斯特拉Dijkstra算法
Dijkstra算法主要针对的是有向图的单元最短路径问题,且不能出现权值为负的情况!Dijkstra算法类似于贪心算法计算从起点到指定顶点的最短路径,通过不断选择距离起点最近的顶点,来逐渐扩大最短路径权值,直到覆盖图中所有顶点(与方法4不同,其对边的松弛顺序是随意进行的)。其应用根本在于最短路径的最优子结构性质。Dijkstra算法步骤与Floyd算法类似,更新规则也是dist[j]=min(dist[j],dist[i]+matrix[i][j])
采用邻接矩阵存储,两顶点之间不存在有向连接,则设置为inf.
算法过程:
1.从未确认顶点中选择距离起点最近的顶点,并标记为已确认顶点
2.根据步骤 1 中的已确认顶点,更新其相邻未确认顶点的距离
3.重复步骤 1,2,直到不存在未确认顶点
# 图中的顶点数
V = 6
# 标记数组:used[v]值为False说明改顶点还没有访问过,在S中,否则在U中!
used = [False for _ in range(V)]
# 距离数组:distance[i]表示从源点s到i的最短距离,distance[s]=0
distance = [float('inf') for _ in range(V)]
# cost[u][v]表示边e=(u,v)的权值,不存在时设为INF
cost = [[float('inf') for _ in range(V)] for _ in range(V)]
def dijkstra(s):
distance[s] = 0
while True:
# v在这里相当于是一个哨兵,对包含起点s做统一处理!
v = -1
# 从未使用过的顶点中选择一个距离最小的顶点
for u in range(V):
if not used[u] and (v == -1 or distance[u] < distance[v]):
v = u
if v == -1: # 说明所有顶点都维护到S中了!
break
# 将选定的顶点加入到S中, 同时进行距离更新
used[v] = True
# 更新U中各个顶点到起点s的距离。之所以更新U中顶点的距离,是由于上一步中确定了k是求出最短路径的顶点,从而可以利用k来更新其它顶点的距离;例如,(s,v)的距离可能大于(s,k)+(k,v)的距离。
for u in range(V):
distance[u] = min(distance[u], distance[v] + cost[v][u])
if __name__ == '__main__':
Inf = float('inf')
cost = [[0, 1, 12, Inf, Inf, Inf],
[Inf, 0, 9, 3, Inf, Inf],
[Inf, Inf, 0, Inf, 5, Inf],
[Inf, Inf, 4, 0, 13, 15],
[Inf, Inf, Inf, Inf, 0, 4],
[Inf, Inf, Inf, Inf, Inf, 0]]
s = int(input('请输入一个起始点(0-5):'))
dijkstra(s)
print(distance) # [0, 1, 8, 4, 13, 17]
4.贝尔曼-福特Bellman-Ford算法
算法核心是通过松弛函数进行距离更新:if d[v] > d[u] + w(u, v): d[v] = d[u] + w(u, v),最多通过|V - 1|次松弛就可以得到各顶点之间的最短距离。

class Solution:
def findCheapestPrice(self, n: int, flights: List[List[int]], src: int, dst: int, K: int) -> int:
distance = [[float('inf')] * (K + 2) for _ in range(n)] # distance行表示点,列表示松弛次数,值代表最短距离
for i in range(K + 2):
distance[src][i] = 0 # 原点不管松弛几次距离本身都是0
times = 1 # 松弛次数
def relax(vi, vj, w, times):
if distance[vj][times] > distance[vi][times - 1] + w:
distance[vj][times] = distance[vi][times - 1] + w
while times < K + 2: # 我们这里把直连一个点设置为松弛1次,绕过一个点算松弛2次,绕过两个点算松弛3次,以此类推,可以绕过K个点,那么可以松弛K+1次
for vi, vj, w in flights:
if distance[vi][times - 1] != None:
relax(vi, vj, w, times)
times += 1
return distance[dst][K + 1] if distance[dst][K + 1] != float('inf') else -1
优化版本:
class Solution(object):
def findCheapestPrice(self, n, flights, src, dst, k):
dist = [float('inf')] * n # dist[v]表示到达v的最小花费
dist[src] = 0
for i in range(k + 1): # 对每条边做 k+1 次松弛操作,每次松弛操作实际上是对相邻节点的访问,所以总的中转为k次
dist_old = [_ for _ in dist]
for u, v, w in flights:
dist[v] = min(dist[v], dist_old[u] + w)
return dist[dst] if dist[dst] != float('inf') else -1
5.SPFA算法
SPFA(Shortest Path Faster Algorithm)算法是求单源最短路径的一种算法,它是Bellman-ford的队列优化,它是一种十分高效的最短路算法。
很多时候,给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便派上用场了。SPFA的复杂度大约是O(kE),k是每个点的平均进队次数(一般的,k是一个常数,在稀疏图中小于2)。
但是,SPFA算法稳定性较差,在稠密图中SPFA算法时间复杂度会退化。
实现方法:
建立一个队列,初始时队列里只有起始点,再建立一个表格记录起始点到所有点的最短路径(该表格的初始值要赋为极大值,该点到他本身的路径赋为0)。然后执行松弛操作,用队列里有的点去刷新起始点到所有点的最短路,如果刷新成功且被刷新点不在队列中则把该点加入到队列最后。重复执行直到队列为空。
此外,SPFA算法还可以判断图中是否有负权环,即一个点入队次数超过N。
from collections import deque
class Solutions:
def spfa(self, grids, src, target):
dis = [float('inf')] * len(grids)
counter = [0] * len(grids)
dis[src] = 0
visited = set() #这里设置一个visited集合主要是为了后面判断是否存在负环,不需判断负环的代码请看下面简洁代码
q = deque([(0, src)])
visited.add(src)
while q:
d_cur, cur = q.popleft()
visited.remove(cur)
for node, value in enumerate(grids[cur]):
if value and dis[cur] + value < dis[node]:
dis[node] = value + dis[cur]
if node not in visited:
counter[node] += 1
if counter[node] > len(grids):
raise ValueError('输入有负环异常!')
visited.add(node)
q.append((dis[node], node))
return dis[target] if dis[target] != float('inf') else -1
m, n, src, target = map(int, input().split())
grids = [[float('inf')] * m for _ in range(m)]
for _ in range(n):
i, j, dis = map(int, input().split())
grids[i][j] = dis
f = Solutions()
out = f.spfa(grids, src, target)
print(out)
'''
输入:
第一行节点数m、边数n、起点、终点,接下来n行每行三个数字,当前起点-下一终点-距离值。
输出起点到终点的最短距离。
input:
5 7 0 4
0 1 3
0 2 2
1 3 1
3 0 4
3 2 6
3 4 4
4 2 4
output:
8
'''
简洁版:
from collections import deque
from collections import defaultdict
class Solution:
def spfa(self, grids, src, target):
dist = [float('inf')] * len(grids)
dist[src] = 0
dic = defaultdict(dict)
for u, v, w in grids:
dic[u][v] = w
q = deque([src])
while q:
node = q.popleft()
for v in dic.get(node, []):
if dist[node] + dic[node][v] < dist[v]:
dist[v] = dist[node] + dic[node][v]
q.append(v)
return dist[target] if dist[target] != float('inf') else -1
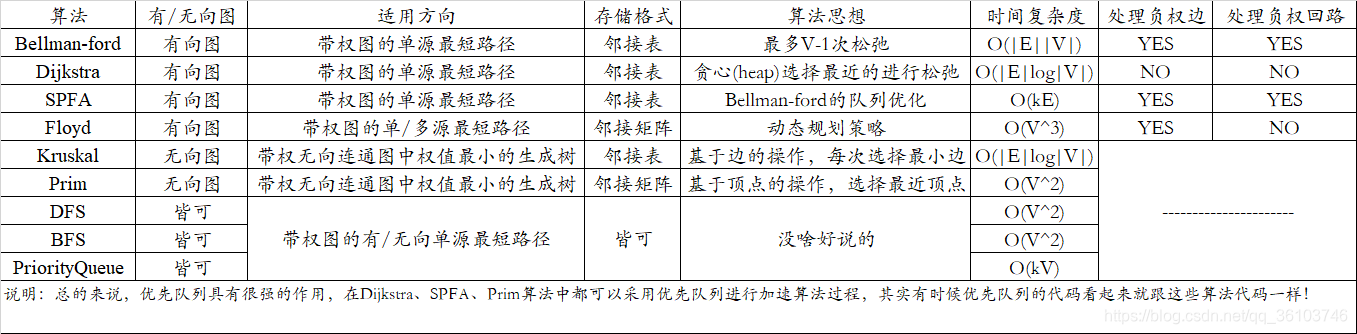
总结
就放一个各种算法对比表吧。

















 6098
6098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









