







 该专栏为热销专栏榜 第67名
该专栏为热销专栏榜 第67名目录
Seaborn可视化-核密度分布图 seaborn.kdeplot
前言
密度估计问题在诸多机器学习与模式识别任务中起着核心作用.核密度估计(Kernel Density Estimation,简称KDE)算法作为当前最有效和应用最广泛的一种非参数密度估计算法,在理论与应用方面都得到了广泛而深入的研究.
核密度估计(Kernel Density Estmation,KDE)认为在一定的空间范围内,某种事件可以在任何位置发生,但是在不同的地理位置上发生的概率是不一样的,如果在某一区域内其事件发生的次数较多则认为此区域内此事件发生的频率高,反之则低。另外根据地理学第一定律,即:距离越近的事物关联越密切,与核心要素越近的位置获取的密度扩张值越大。我们可以把每一个发生的事件看做成一个核心要素,那么在事件发生次数较多的区域,核心要素间的关联性就越强。而核密度估计通过一个函数反映了这一思想。
核密度估计就是估计概率密度函数,从几个样本估计其服从的分布,即求出其概率密度函数,这样就可以求任意区间处的概率了。所以核密度就是一个从具体样本到普遍概率密度的过程,然后再用普遍指导具体的问题。
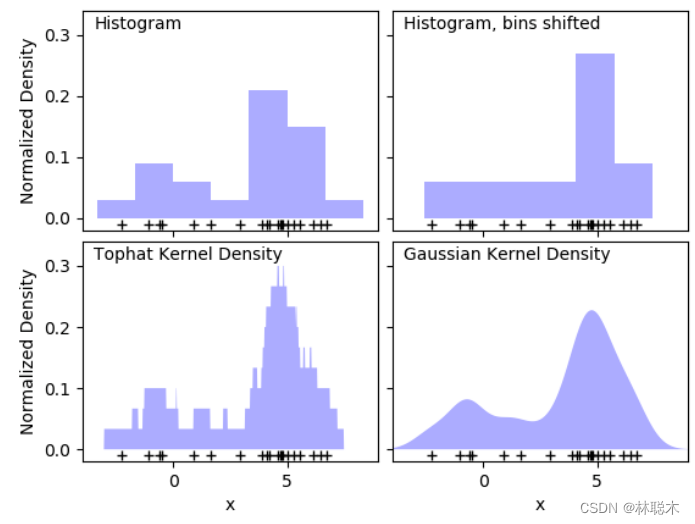
在实际生活中,核密度估计可以根据某一地区犯罪的集中发生地来预测犯罪率密度较高的地区范围,还可以运用野外调查后所得的某一珍稀物种的地理位置来预测其种群密度较高的地域范围。

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











