







基于bag of words 和 word2Vec 的影评情绪分类
分别用词袋模型和Word2Vec模型提取特征进行LR二分类
# -*- coding: utf-8 -*-
'''
基于词袋特征(bag of words)和词向量特征(word2vec)
对影评情绪二分类
'''
import os
import re
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import nltk
import matplotlib.pyplot as plt
import itertools
#from nltk.corpus import stopwords
import warnings
from gensim.models import Word2Vec
from nltk.corpus import stopwords
eng_stopwords = set(stopwords.words('english'))
warnings.filterwarnings("ignore")
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
def clean_text1(text):
text = BeautifulSoup(text, 'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
words = [w for w in words if w not in eng_stopwords]
return ' '.join(words)
def clean_text2(text, remove_stopwords=False):
text = BeautifulSoup(text, 'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
if remove_stopwords:
words = [w for w in words if w not in eng_stopwords]
return words
def to_review_vector(review):
global word_vec
review = clean_text2(review, remove_stopwords=True)
#print (review)
#words = nltk.word_tokenize(review)
word_vec = np.zeros((1,300))
for word in review:
#word_vec = np.zeros((1,300))
if word in model:
word_vec += np.array([model[word]])
#print (word_vec.mean(axis = 0))
return pd.Series(word_vec.mean(axis = 0))
def split_sentences(review):
raw_sentences = tokenizer.tokenize(review.strip())
sentences = [clean_text1(s) for s in raw_sentences if s]
return sentences
if __name__ == "__main__":
'''
词袋模型
'''
df = pd.read_csv("labeledTrainData.tsv",sep = "\t",escapechar="\\")
stopwords = {}.fromkeys([line.rstrip() for line in open("stopwords.txt")])
eng_stopwords = set(stopwords)
df["clean_review"] = df["review"].apply(clean_text1)
vectorizer = CountVectorizer(max_features = 5000)
train_data_features = vectorizer.fit_transform(df["clean_review"]).toarray()
X_train,X_test,y_train,y_test = train_test_split(train_data_features,df["sentiment"].values,test_size=0.2,random_state=0)
LR_model = LogisticRegression()
LR_model = LR_model.fit(X_train,y_train)
y_pred = LR_model.predict(X_test)
cnf_matrix = confusion_matrix(y_test,y_pred)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
'''
word2vec模型
'''
#训练词向量
df = pd.read_csv("unlabeledTrainData.tsv",sep="\t",escapechar="\\")
df["clean_review"] = df.review.apply(clean_text1)
review_part = df['clean_review']
sentences = sum(review_part.apply(split_sentences), [])
sentences_list = []
for line in sentences:
sentences_list.append(nltk.word_tokenize(line))
# 设定词向量训练的参数
num_features = 300 # Word vector dimensionality
min_word_count = 40 # Minimum word count
num_workers = 4 # Number of threads to run in parallel
context = 10 # Context window size
model_name = '{}features_{}minwords_{}context.model'.format(num_features, min_word_count, context)
model = Word2Vec(sentences_list,workers=num_workers,size=num_features,min_count=min_word_count,window=context)
# model.save(os.path.join('..', 'models', model_name))
model.init_sims(replace=True)
#训练模型
df = pd.read_csv('labeledTrainData.tsv', sep='\t', escapechar='\\')
train_data_features = df.review.apply(to_review_vector)
X_train, X_test, y_train, y_test = train_test_split(train_data_features,df.sentiment,test_size = 0.2, random_state = 0)
LR_model = LogisticRegression()
LR_model = LR_model.fit(X_train, y_train)
y_pred = LR_model.predict(X_test)
cnf_matrix = confusion_matrix(y_test,y_pred)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
结果如下:
词袋模型
Recall metric in the testing dataset: 0.8531810766721044
accuracy metric in the testing dataset: 0.8454
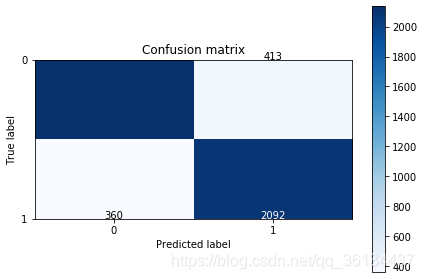
词向量模型
Recall metric in the testing dataset: 0.8776508972267537
accuracy metric in the testing dataset: 0.865
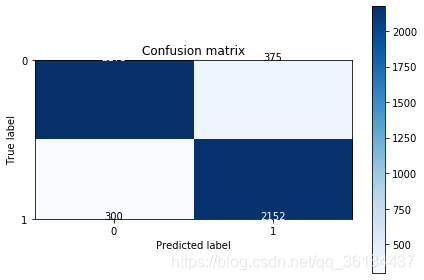














 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









