






Hive支持的文件存储格式有
- TEXTFILE
- SEQUENCEFILE
- RCFILE
- 自定义格式
在建表的时候,可以使用STORED AS子句指定文件存储的格式。
TEXTFILE
即通常说的文本格式,默认长期,数据不做压缩,磁盘开销大、数据解析开销大。
SEQUENCEFILE
Hadoop提供的一种二进制格式,使用方便、可分割、可压缩,并且按行进行切分
RCFILE
一种行列存储相结合的存储方式,首先,其将数据按行分块,保证同一条记录在一个块上,避免读一条记录多个块。其次,块上的数据按照列式存储,有利于数据压缩和快速地进行列存取。
ORC
全称是(Optimized Record Columnar),使用ORC文件格式可以提高hive读、写和处理数据的能力。ORC在RCFile的基础上进行了一定的改进,所以与RCFile相比,具有以下一些优势:
- 1、ORC中的特定的序列化与反序列化操作可以使ORC file writer根据数据类型进行写出。- 2、提供了多种RCFile中没有的indexes,这些indexes可以使ORC的reader很快的读到需要的数据,并且跳过无用数据,这使得ORC文件中的数据可以很快的得到访问。
- 3、由于ORC file writer可以根据数据类型进行写出,所以ORC可以支持复杂的数据结构(比如Map等)。
- 4、除了上面三个理论上就具有的优势之外,ORC的具体实现上还有一些其他的优势,比如ORC的stripe默认大小更大,为ORC writer提供了一个memory manager来管理内存使用情况。 自定义文件格式
用户通过实现InputFormat和OutputFormat来自定义输入输出格式。
ORC详解
在ORC格式的hive表中,记录首先会被横向的切分为多个stripes,然后在每一个stripe内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。每个stripe的默认大小为256MB,相对于RCFile每个4MB的stripe而言,更大的stripe使ORC的数据读取更加高效。
对于复杂数据类型,比如Map,ORC文件会将一个复杂数据类型字段解析成多个子字段。下表中列举了ORC文件中对于复杂数据类型的解析
| Data type | Chile columns |
|---|---|
| Array | 一个包含所有数组元素的子字段 |
| Map | 两个子字段,一个key字段,一个value字段 |
| Struct | 每一个属性对应一个子字段 |
| Union | 每一个属性对应一个子字段 |
当字段类型都被解析后,会由这些字段类型组成一个字段树,只有树的叶子节点才会保存表数据,这些叶子节点中的数据形成一个数据流,如上图中的Data Stream。
为了使ORC文件的reader更加高效的读取数据,字段的metadata会保存在Meta Stream中。在字段树中,每一个非叶子节点记录的就是字段的metadata,比如对一个array来说,会记录它的长度。下图根据表的字段类型生成了一个对应的字段树。
RCFile
RCFile文件格式是FaceBook开源的一种Hive的文件存储格式,首先将表分为几个行组,对每个行组内的数据进行按列存储,每一列的数据都是分开存储,正是先水平划分,再垂直划分的理念。
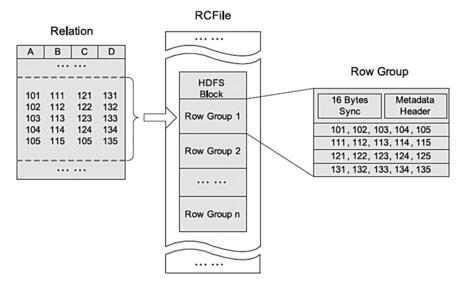
在存储结构上:
如上图是HDFS内RCFile的存储结构,我们可以看到,首先对表进行行划分,分成多个行组。一个行组主要包括:16字节的HDFS同步块信息,主要是为了区分一个HDFS块上的相邻行组;元数据的头部信息主要包括该行组内的存储的行数、列的字段信息等等;数据部分我们可以看出RCFile将每一行,存储为一列,将一列存储为一行,因为当表很大,我们的字段很多的时候,我们往往只需要取出固定的一列就可以。
在一般的行存储中 select a from table,虽然只是取出一个字段的值,但是还是会遍历整个表,所以效果和select * from table 一样,在RCFile中,像前面说的情况,只会读取该行组的一行。
在一般的列存储中,会将不同的列分开存储,这样在查询的时候会跳过某些列,但是有时候存在一个表的有些列不在同一个HDFS块上(如下图),所以在查询的时候,Hive重组列的过程会浪费很多IO开销。
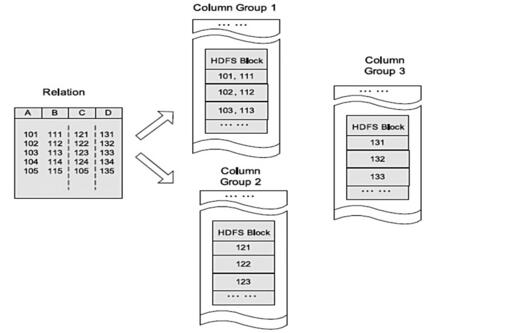
而RCFile由于相同的列都是在一个HDFS块上,所以相对列存储而言会节省很多资源。
在存储空间上:
RCFile采用游程编码,相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候。
懒加载:
数据存储到表中都是压缩的数据,Hive读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。
针对行组来说,会对一个行组的a列进行解压缩,如果当前列中有a>1的值,然后才去解压缩c。若当前行组中不存在a>1的列,那就不用解压缩c,从而跳过整个行组。















 1092
1092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









