







0.我们有这样一个表,表名为Student

1.在Hbase中创建一个表

表明为student,列族为info
2.插入数据
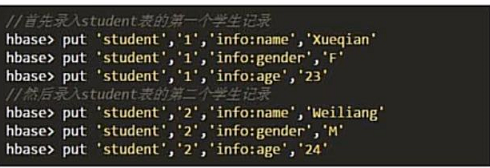
我们这里采用put来插入数据
格式如下 put ‘表命’,‘行键’,‘列族:列’,‘值’
我们知道Hbase 四个键确定一个值,
一般查询的时候我们需要提供 表名、行键、列族:列名、时间戳才会有一个确定的值。
但是这里插入的时候,时间戳自动被生成,我们并不用额外操作。
我们不用表的时候可以这样删除

注意,一定要先disable 再drop,不能像RDMS一样直接drop
3.配置spark
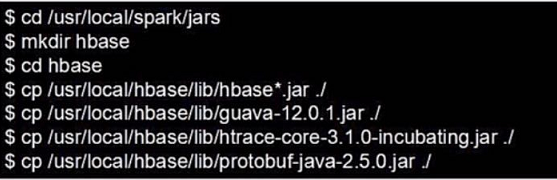
我们需要把Hbase的lib目录下的一些jar文件拷贝到Spark中,这些都是编程中需要引进的jar包。
需要拷贝的jar包包括:所有hbase开头的jar文件、guava-12.0.1.jar、htrace-core-3.1.0-incubating.jar和protobuf-java-2.5.0.jar
我们将文件拷贝到Spark目录下的jars文件中
4.编写程序
(1)读取数据

我们程序中需要的jar包如下

我们这里使用Maven来导入相关jar包
我们需要导入hadoop和spark相关的jar包
spark方面需要导入的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>hadoop方面需要导入的依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>hbase方面需要导入的依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>我们使用的org.apache.hadoop.hbase.mapreduce是通过hbase-server导入的。
具体的程序如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
(2)存入数据
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
5.Maven打包
我们用命令行打开到项目的根目录,输入mvn clean package -DskipTests=true
打包成功后我们到项目目录下的target文件下就会找到相应的jar包
6.提交任务
















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









