







问题
直接I/O允许I/O请求绕过Linux页面缓存,作为默认缓冲I/O模式的替代方案。然而,高性能计算(HPC)应用程序仍然主要依赖于缓冲I/O,即使直接I/O在给定情况下可以执行得更好。这是因为用户倾向于使用他们最熟悉的I/O模式。但对于复杂的分布式文件系统和应用程序,通常不清楚使用哪种I/O模式。
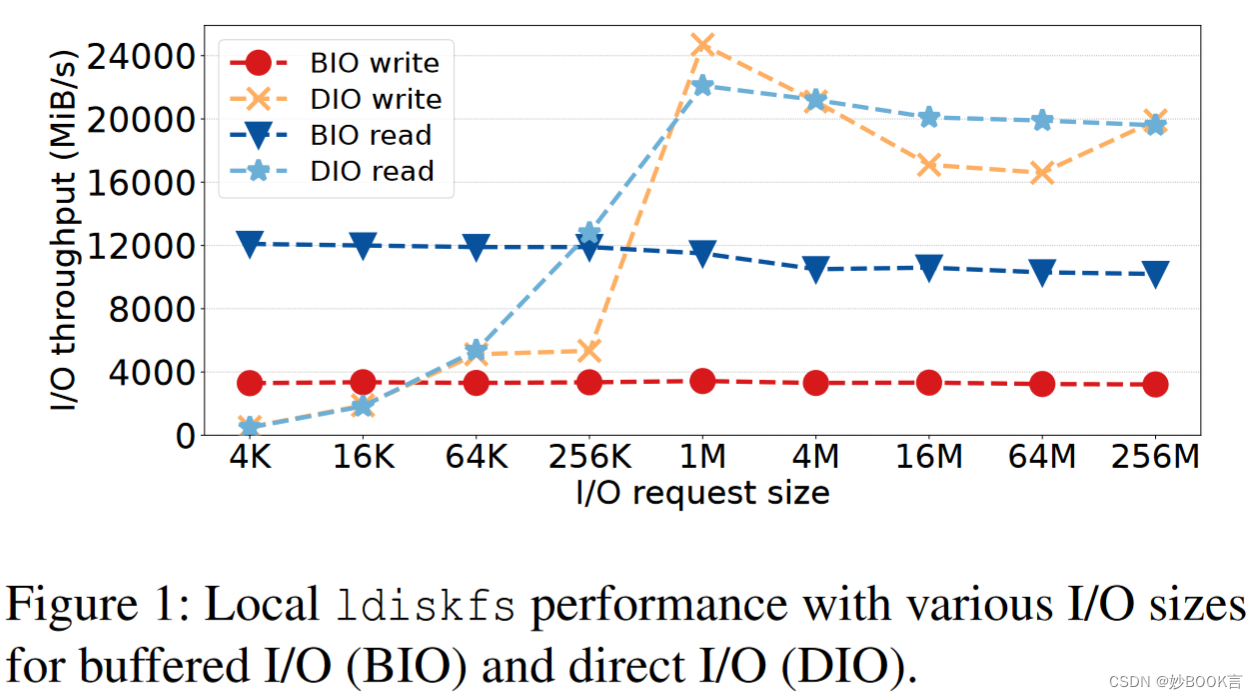
缓冲I/O的性能不始终优于直接I/O:
-
缓冲I/O会引发额外的复制操作,以便在内核缓存和应用程序之间移动数据
-
与内核页面缓存和页面管理交互的开销相当大
-
当内存变得稀缺时,页面回收必须释放旧页面,以便为当前I/O操作分配内存,由此产生的缓存抖动可能会显著降低性能
-
缓冲I/O在并行文件系统中另一个成本是管理复杂的分布式范围锁,以支持强一致性的客户端缓存。如果只锁定并发访问文件的必要(小)部分,则需要在客户端和锁管理器之间进行多次远程过程调用(RPC),而使用较大的扩展锁,可能会导致客户端之间的错误锁争用和许多锁吊销消息[39]。

本文方法
在本文中,展示了在哪些条件下两种I/O模式都是有益的,并提出了一种新的透明方法,可以动态切换到文件系统中的每种I/O模式。它的决策基于:I/O大小、文件锁争用、内存压力。其他优化还有:自适应服务器端回写缓存、将未对齐I/O对齐、延迟分配、I/O请求批处理。

在Lustre客户端和服务器中示例性地实现了我们的设计,并用其他功能对其进行了扩展,例如延迟分配。在各种条件和实际工作负载下,本文方法实现了比原始Lustre高出3倍的吞吐量,并比包括不同程度的直接I/O支持的其他分布式文件系统高出13倍。
实验
实验环境:4个MDT、8个OST、32个客户端节点组成的Lustre集群。服务器使用DDN AI400X2设备后端(20×SAMSUNG 3.84 TiB NVMe,4×IB-HDR100 100 100 Gbps),运行Lustre 2.15.58。所有客户端都使用Intel Gold 5218处理器、96 GiB DDR4内存,运行CentOS 8.7 Linux。所有节点均使用InfiniBand IB-HDR100互连。
数据集:微基准测试、mdtest、HPC工作负载 mpiFileUtils/dcp [50]、VPIC-IO[12]、Nek5000应用程序[20]
实验对比:吞吐量、I/O带宽
实验参数:I/O大小、并发I/O、文件大小
总结
针对文件系统中直接I/O和缓存I/O的选择,作者分析二者在不同条件下各有优劣,于是提出根据系统状态自适应选择I/O方式。根据对I/O大小、文件锁争用、内存压力的分析,明确了各种环境下哪种I/O方式性能更高,对应切换到性能更高的I/O方式。将自适应I/O方法应用于Lustre中,同时提出优化:自适应服务器端回写缓存、将未对齐I/O对齐、延迟分配、I/O请求批处理。
















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











