







为什么需要无监督学习
- 原始数据容易获得,标注数据很难获得
- 节约内存和计算资源
- 减少高维数据中的噪声
- 有助于可解释的数据分析
- 经常作为监督学习的预处理部分
聚类分析
寻找样本中的簇,使得同一簇内样本相似,不同簇之间样本不相似。
聚类的类型

聚类的结果是产生一个簇的集合
- 基于划分的聚类(无嵌套)
- 将所有样本划分到若干不重叠的子集(簇),且使得每个样本仅属于一个 子集
层次聚类(嵌套)
- 树形聚类结构,在不同层次对数据集进行划分,簇之间存在嵌套
对聚类中簇集合的其他区别
- 独占(Exclusive ) vs. 非独占的(non-exclusive) ) 在非独占的类簇中, 样本点可以属于多个簇
- 模糊(Fuzzy ) vs. 非模糊的(non-fuzzy) )
- 在模糊聚类中, 一个样本点以一定权重属于各个聚类簇
- 权重和为1
- 概率聚类有相似的特性
- 部分(Partial ) vs. 完备( complete ) )
- 在一些场景, 我们只聚类部分数据
- 异质(Heterogeneous ) vs. 同质(homogeneous) )
- 簇的大小、形状和密度的是否有很大的差别
簇的类型
1.基于中心的簇
簇内的点和其“中心”较为相近(或相似),和其他簇的“中心”较远,
这样的一组样本形成的簇
簇的中心常用质心(metroid)表示,即簇内所有点的平均, 或者用中心点
(medoid) 表示, 即簇内最有代表性的点
2. 基于邻接的簇
3. 基于连续性的簇:相比其他任何簇的点,每个点都至少和所属簇的某一个点更近

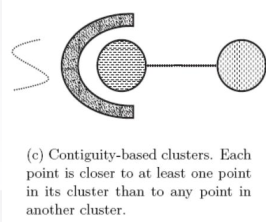
-
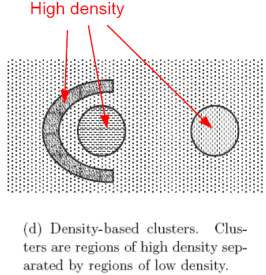
基于密度的簇:簇是有高密的区域形成的,簇之间是一些低密度的区域
-
基于概念的簇
聚类的应用
- 图像分割
这个是基于连续的簇

- 人类种族分析
这个是基于层次的聚类

- 复杂网络分析
这是一张社交关系网络。对这样一个复杂的网络有很多研究,给你一个微博转发关系,就成了一个网络。这里有很多有趣的现象,小世界或者是六度分割理论,它不是一个均匀的网络,在这里聚类算法就比较好用。我们各自都有自己的群,从群里面转发消息,除了腾讯或者微信的大boss知道我们有什么群,我们不可能知道我们的好友有几个群。那么你能告诉我他们有哪些群 ,谁是这个群里的发言人?群主,谁是这个群里的意见领袖,可以已转发就发生很大的影响。通过聚类的分析,在这个网络里,我们不把一个点当做一个类,它可能是一个小的group,再往外看变成大的group
其他应用

-
用户画像:基于顾客消费历史对顾客聚类
-
商品分析:基于购买的用户对商品聚类
-
文本分析:基于相似的词对文档聚类
-
计算生物学:基于编辑距离对DNA序列聚类
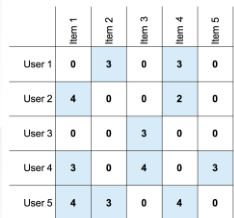
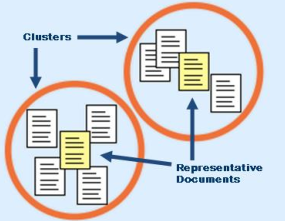
聚类分析的“三要素”
- 如何定义样本点之间的“远近”
• 使用相似性/距离函数 - 如何评价聚类出来簇的质量?
• 利用评价函数去评估聚类结果 - 如何获得聚类的簇?
• 如何表示簇,如何设计划分和优化的算法,算法何时停止
如何衡量样本之间的“远近”?
• 文档聚类时,我们如何衡量文档间远近?
• 图像分割时,我们如何衡量像素点之间的远近?
• 用户画像时,我们如何衡量用户之间的远近?
我们需要量化这些样本,并计算它们之间的距离
-
距离(Distance)/相似(Similarity)/不相似(Dissimilarity)/邻
近(Proximity)函数的选择与应用相关 -
需要考虑特征的类型
类别,序值,数值
-
可以从数据直接学习相似/距离函数
聚类算法
◼ K均值聚类
◼ 高斯混合模型和 EM 算法
◼ 层次聚类
◼ 基于密度的聚类
- K均值聚类是一种比较简单的聚类算法
• 问题:给定一组样本点X = {xi } ? 进行聚类
==============================================
• 输入:数据D = ? 1 ,? 2 ,⋯,? ? ,簇数目K - 随机选取K个种子数据点(seeds)作为K个簇中心
- repeat
- for each ? ∈ ? do
- 计算?与每一个簇中心的距离
- 将?指配到距离最近的簇中心
- end for
- 用当前的簇内点重新计算K个簇中心位置
- until 当前簇中心未更新
==============================================
k-means收敛性 - k-means 是在损失函数上进行坐标下降(coordinate descent)的优化
- 损失函数J 单调下降, 所以损失函数值会收敛, 所以聚类结果也会收敛
- k-means 有可能会在不同聚类结果间震荡,但是在实际中较少发生
- J 是非凸的(non-convex), 所以损失函数J上应用坐标下降法不能够保证收敛到全局的最小值.
一个常见的方法是运行k-means多次,选择最好的结果

如何选择K
K是该算法的超参, 损失函数J 一般 随着K的增大而递减
如何选择K ?

-
间隔统计:分析损失函数J随K增大递减的间隔
-
交叉检验: 把原始数据集分裂两个子集.在其中一个数据集上估计 中心点(prototypes) ,然后在另一个集合上计算损失函数
-
簇的稳定性: 通过对原始数据的重采样或者分裂,度量簇的改变 程度.
-
非参数方法: 为K加上一个先验, Bayesian non-parametric 例如:中国餐馆过程(Chinese
Restaurant Process)
如何初始化K-means?
- 随机选
- 加一个策略选
- 即便存在K个真实的簇,正好选到K个簇的中心的机会也将会是很 小的
- 一些启发式做法
- 随机选择K个数据点作为中心点
- 选择第i+1个中心时,选择与距离之前选出的中心点距离最远的
预处理和后处理
-
预处理
• 归一化数据 (e.g.,缩放到单位标准差)
• 消除离群点 -
后处理
• 删除小的簇:可能代表离群点
• 分裂松散的簇:簇内节点间距离之和很高
• 合并距离较近的簇
K-means的局限性
当簇具有不同的• 尺寸• 密度• 非球形,那么K-means可能得不到理想的聚类结果
未解决这些问题,就会用高斯混合模型,EM算法等















 3500
3500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









