









深度学习算子模块封装
1 环境篇
1.1 应用场景
本案例作为VM算子模块开发的深度学习案例,适用场景为需要将开源深度学习算法集成到VM中拖拽使用的场景。
1.2 运行环境
1)操作系统:Win10及以上64位操作系统。
2) VisionMaster版本:V4.3.0及以上
3) Visual Studio版本:2019及以上
4) Pycharm版本:2021及以上
5) OpenCV版本:opencv4.7.0及以上
6) 编程环境:C++,Python
7) 加密狗要求:基础版加密狗
2 方案篇
2.1 方案思路
1.深度学习环境搭建:Python编程环境;
2.数据集标注及模型训练:Pytorch模型;
3.模型转换:Pytorch(pth)模型转onnx模型;
4.VM算法模块搭建:算法模块工程及Opencv环境;
5.模块打包测试:VS下Debug;
2.2 方案过程
2.2.1 深度学习环境搭建
- Python环境创建方式
Python环境创建方式有许多,如:
[1]. 直接在主环境下安装python并使用pip指令安装一系列依赖包(torch,cv2等);
[2]. 使用pycharm构架python解析器创建python虚拟环境;
[3]. 使用annacoda创建虚拟环境(适合管理多个cuda及cudnn环境); - Python解析器创建及环境安装
本文以python虚拟环境的方式为例介绍:
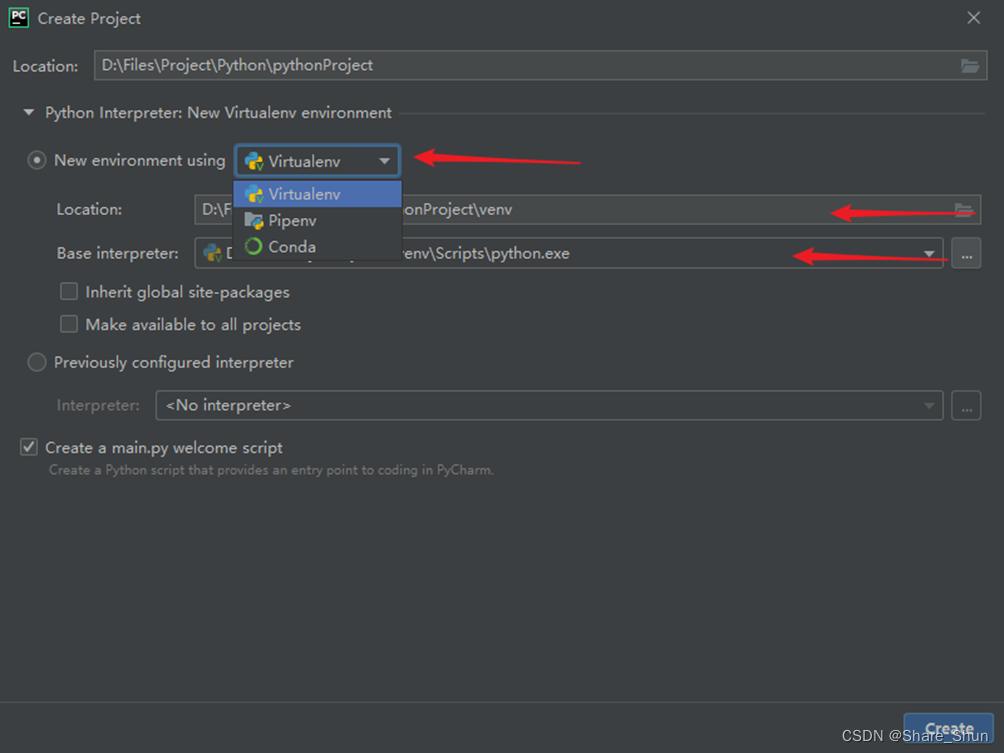
[1]. 创建python解析器
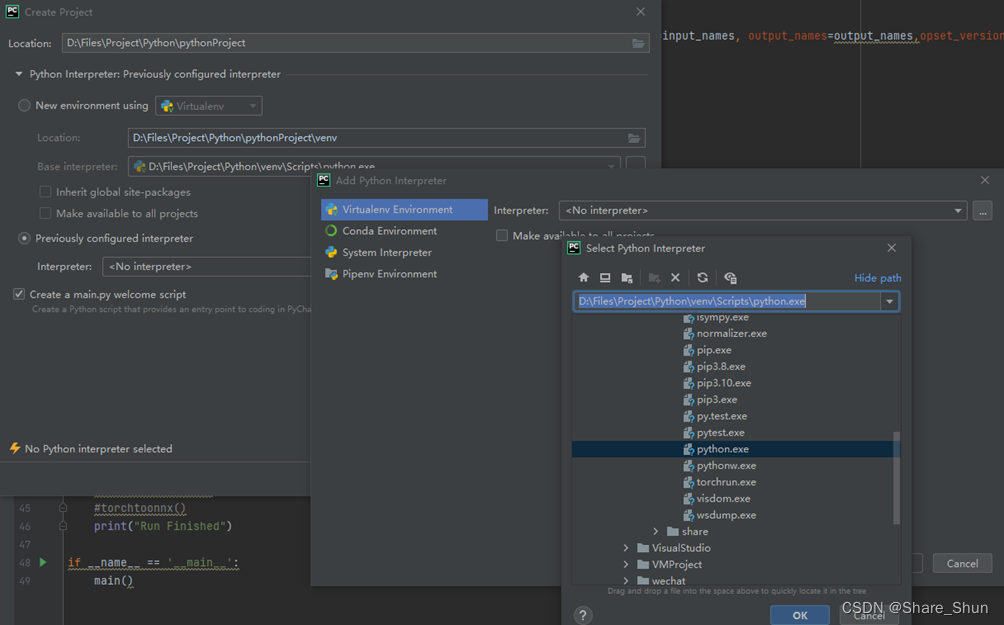
创建项目在以下弹窗选择python环境;第一次创建客户选择New Vitualenv environment,创建新的python解析器;需要加载之前环境的,可以参考图二选择虚拟环境python.exe选择已有环境。
[2]. 安装依赖包
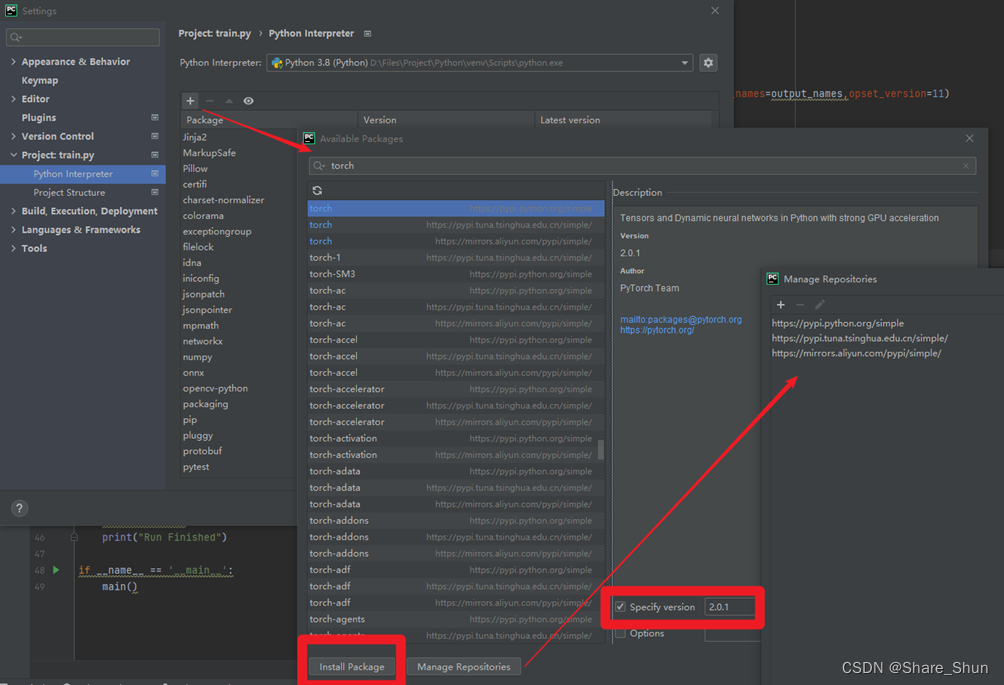
创建完成python环境后需要安装深度学习网络需要的依赖库,一般可根据工程requirement文件安装;本文以pytorch框架为例(安装torch、onnx、torchversion及opencv-python等)。
1)终端使用pip指令安装(二选一);
2)界面安装:界面安装如图所示在搜索页面搜索需要的安装包及版本(如torch),选中后点击安装即可(二选一);
[3]. 测试环境
写测试代码,库能正常导入不报错,则环境配置完成。
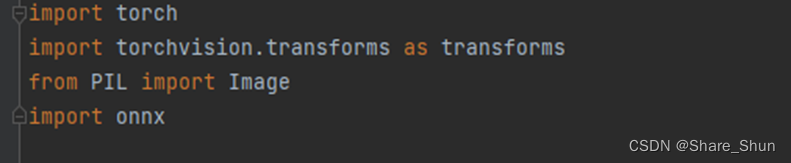
2.2.2 数据标注及模型训练
[1]. 训练数据获取及导入:
根据网络输入需要打标,本文以CIFAR10数据集为例,直接下载打标好的数据集并加载转成Tensor。
[2]. 模型搭建(torch)
根据实际项目需求搭建合适的网络模型,本文基于pytorch架构以残差模型为例,搭建简单的分类模型model.py;
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Module, Sequential, Conv2d, MaxPool2d, Flatten, Linear, ReLU, BatchNorm2d, Dropout
class Conv_Block(Module):
def __init__(self, inchannel, outchannel, res=True):
super(Conv_Block, self).__init__()
self.res = res # 是否带残差连接
self.left = Sequential(
Conv2d(inchannel, outchannel, kernel_size=(3, 3), padding=1, bias=False),
BatchNorm2d(outchannel),
ReLU(inplace=True),
Conv2d(outchannel, outchannel, kernel_size=(3, 3), padding=1, bias=False),
BatchNorm2d(outchannel),
)
self.shortcut = Sequential(Conv2d(inchannel, outchannel, kernel_size=(1, 1), bias=False),BatchNorm2d(outchannel))
self.relu = Sequential(ReLU(inplace=True))
def forward(self, x):
out = self.left(x)
if self.res:
out += self.shortcut(x)
out = self.relu(out)
return out
class Res_Model(Module):
def __init__(self, res=True):
super(Res_Model, self).__init__()
self.block1 = Conv_Block(inchannel=3, outchannel=64)
self.block2 = Conv_Block(inchannel=64, outchannel=128)
self.block3 = Conv_Block(inchannel=128, outchannel=256)
self.block4 = Conv_Block(inchannel=256, outchannel=512)
# 构建卷积层之后的全连接层以及分类器:
self.classifier = Sequential(Flatten(), # 7 Flatten层
Dropout(0.4),
Linear(2048, 256), # 8 全连接层
Linear(256, 64), # 8 全连接层
Linear(64, 10)) # 9 全连接层 ) # fc,最终Cifar10输出是10类
self.relu = ReLU(inplace=True)
self.maxpool = Sequential(MaxPool2d(kernel_size=2)) # 1最大池化层
def forward(self, x):
out = self.block1(x)
out = self.maxpool(out)
out = self.block2(out)
out = self.maxpool(out)
out = self.block3(out)
out = self.maxpool(out)
out = self.block4(out)
out = self.maxpool(out)
out = self.classifier(out)
return out
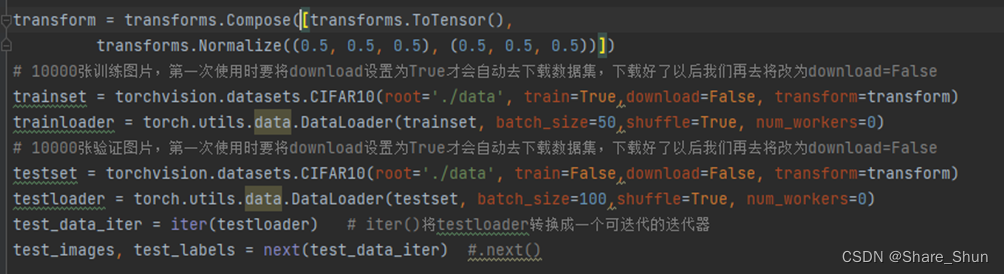
[3]. 模型训练(pth),创建train.py文件设置超参数进行网络模型训练
import torch
import torchvision
import torch.nn as nn
from model import LeNet,Res_Model
import torch.optim as optim
import torchvision.transforms as transforms
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 10000张训练图片,第一次使用时要将download设置为True才会自动去下载数据集,下载好了以后我们再去将改为download=False
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=50,shuffle=True, num_workers=0)
# 10000张验证图片,第一次使用时要将download设置为True才会自动去下载数据集,下载好了以后我们再去将改为download=False
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100,shuffle=True, num_workers=0)
test_data_iter = iter(testloader) # iter()将testloader转换成一个可迭代的迭代器
test_images, test_labels = next(test_data_iter) #.next()
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # 这个也就是我们之前在model模块中将最后的输出设置为10的原因,因为这个是10个类别
net = Res_Model()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001) # 传入优化器,net.parameters() 相当于是将net中所有可以训练的参数都进行了训练
def main(k):
for epoch in range(k): # loop over the dataset multiple times 主要是训练集
running_loss = 0.0
for step, data in enumerate(trainloader, start=0):
# train
# for index,item in enumerate(listname) 输出的是索引和元素值
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients 将参数梯度归零
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels) # 计算输出值和标签值之间的损失
loss.backward()
optimizer.step()
# test
running_loss += loss.item()
if step % 10 == 9: # print every 10 mini-batches 每10次打印出一下
with torch.no_grad():
outputs = net(test_images) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1] # dim=1在10这个位置,[1]即是index
accuracy = torch.eq(predict_y, test_labels).sum().item() / test_labels.size(0) # test_labels.size(0)代表测试样本的数目
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, step + 1, running_loss / 10,accuracy)) # running_loss/100 是因为我们在上面每100步打印了一次,所以在这里需要算进去
running_loss = 0.0
if ((epoch+1) % 5 == 0):
save_path = './model/Res_Model'+str(epoch+1)+'.pth'
torch.save(net, save_path)
print('save model in '+str(epoch+1))
if __name__ == '__main__':
main(20)
print('Finished Training')
注意:保存模型需使用torch.save()将模型文件与参数文件一起保存,后续转onnx需要加载带模型的参数文件。
[4]. 模型验证(pth),创建predict.py文件加载训练好的网络模型进行预测
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def main():
#net.load_state_dict(torch.load('./model/Lenet.pth')) # 载入保存的权重文件
net = torch.load('./model/Res_Model6.pth')
im = Image.open('./data/cifar_pictures/NO.11class3cat.jpg') # 导入的图像一般都是 height、width、channel
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W] batch、channel height width
net.eval()#关闭dropout方法
with torch.no_grad():#不需要求损失梯度
outputs = net(im)
predict = torch.softmax(outputs, dim=1) #softmax获取概率分布
predict_index = torch.max(predict, dim=1)[1].numpy() # 寻找输出中的最大值的index
print(classes[int(predict_index)])
if __name__ == '__main__':
main()
print("Run Finished")
2.2.3 模型转换
在深度学习模型落地的过程中,会面临将模型部署的问题,模型训练使用不同的框架,则推理的时候也需要使用相同的框架,但不同类型的平台,调优和实现起来非常困难,因为每个平台都有不同的功能和特性。如果需要在该平台上运行多种框架,则会增加复杂性,所以ONNX便派上了用场。可以通过将不同框架训练的模型转换成通用的ONNX模型,再进而转换成各个平台支持的格式,就可以实现简化部署。
ONNX 是 Open Neural Network Exchange 的简称,也叫开放神经网络交换,是一个用于表示深度学习模型的标准,可使模型在不同框架直接转换。ONNX 是迈向开放式生态系统的第一步,使得开发人员不局限于某种特定的开发工具,为模型提供了开源格式。
ONNX 目前支持的框架有:Caffe2、PyTorch、TensorFlow、MXNet、TensorRT、CNTK 等,模型转换示例代码:
def torchtoonnx():
x = torch.randn(1, 3, 32, 32, device="cpu")
model = torch.load('./model/mynet.pth', map_location=torch.device('cpu'))
model.eval()
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model, x, "GlandMynet.onnx", verbose=True, input_names=input_names, output_names=output_names,opset_version=11)
onnx_model = onnx.load("GlandMynet.onnx")
onnx.checker.check_model(onnx_model)
2.2.4 VM算法模块搭建
[1]. 使用VM算子生成工具创建算子三层架构文件;

[2]. 执行Cs工程生成界面文件并将生成的dll复制到模块界面文件夹下;
[3]. 打开C++算法工程配置界面参数交互
首先需确定模块需要的输入,如需要用户在界面选择并加载模型文件,需在界面开放文件选择控件;
i. 在模块***ModuAlgorithmTab.xml配置文件夹内<Tab_Basic Params>节点下的节点内添加文件控件,如下所示:
<AlgorithmTabRoot>
<Tabs>
<Tab Name="Tab_Basic Params">
<Categorys>
<GroupLinkItem Name="ImageSourceGroup">
<LinkName>ImageSourceGroup</LinkName>
</GroupLinkItem>
<Category Name="Tab_ROI Area">
<Items>
<GroupLinkItem Name="RoiSelectGroup">
<LinkName>RoiSelectGroup</LinkName>
</GroupLinkItem>
<ROISelecter Name="RoiType">
<Description>Shape</Description>
<DisplayName>Shape</DisplayName>
<Visibility>Beginner</Visibility>
<AccessMode>RW</AccessMode>
<FullScreenEnable>True</FullScreenEnable>
<SelectType>Single</SelectType>
<CustomVisible>False</CustomVisible>
<ROISelection>Box</ROISelection>
</ROISelecter>
<GroupLinkItem Name="InheritWayGroup">
<LinkName>InheritWayGroup</LinkName>
</GroupLinkItem>
</Items>
</Category>
<Category Name="Tab_Modle File">
<Items>
<OpenFileForCNNDialog Name="LoadModelPath">
<Description>Model File Path</Description>
<DisplayName>Model File Path</DisplayName>
<AccessMode>RW</AccessMode>
<CurValue></CurValue>
<DefaultValue></DefaultValue>
<FileOption>
<IsMultiselect>false</IsMultiselect>
<FilterName>模型文件|*.onnx</FilterName>
</FileOption>
</OpenFileForCNNDialog>
</Items>
</Category>
</Categorys>
</Tab>
</AlgorithmTabRoot>
ii. 在模块ModuAlgorithm.xml文件夹内添加保存算法参数节点,添加后节点参数会保存在方案文件内;如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<AlgorithmParamList>
<ParamItem>
<Name>kClass</Name>
<DefaultValue>1</DefaultValue>
</ParamItem>
<ParamItem>
<Name>LoadModelPath</Name>
<DefaultValue></DefaultValue>
</ParamItem>
</AlgorithmParamList>
iii.算法工程内添加界面交互代码;SetParam()函数内添加模型文件路径设置到底层代码,界面选择文件夹后触发;GetParam()函数内添加获取底层路径代码,触发时机为打开模块界面,用于从底层获取参数值;
//SetParam()
else if (0 == strcmp("LoadModelPath", szParamName))
{
m_chModelPathName = pData;
nErrCode = (int)classifyNet.readModel(net, m_chModelPathName, false);//加载模型
if (!nErrCode)
isLoadModel = true;
}
//GetParam()
else if (0 == strcmp("LoadModelPath", szParamName))
{
strcpy(pBuff, m_chModelPathName.c_str());
}
[4]. C++算法工程配置算法环境
配置OpenCV环境,库目录、包含目录及链接器输入。

[5]. 网络调用类封装
主要封装两个函数,读取模型文件函数和模型预测函数;示例代码如下:
#include "ClassifyNetC.h"
#include <opencv2\opencv.hpp>
using namespace cv;
using namespace cv::dnn;
/// <summary>
/// 模型加载
/// </summary>
/// <param name="net"></param>
/// <param name="netPath"></param>
/// <param name="isCuda"></param>
/// <returns></returns>
int ClassifyNetC::readModel(cv::dnn::Net& net, std::string& netPath, bool isCuda)
{
try {
net = readNet(netPath);
}
catch (const std::exception)
{
return 1;
}
if (isCuda)
{
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA_FP16);
}
else
{
net.setPreferableBackend(cv::dnn::DNN_BACKEND_DEFAULT);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
}
return 0;
}
/// <summary>
/// 模型预测
/// </summary>
/// <param name="srcImg"></param>
/// <param name="net"></param>
/// <param name="output"></param>
/// <returns></returns>
bool ClassifyNetC::Detect(cv::Mat& srcImg, cv::dnn::Net& net, std::vector<float>& output)
{
Mat blob;
int col = srcImg.cols;
int row = srcImg.rows;
int maxLen = MAX(col, row);
Mat netInputImg = srcImg.clone();
if (maxLen > 1.2 * col || maxLen > 1.2 * row) {
Mat resizeImg = Mat::zeros(maxLen, maxLen, CV_8UC3);
srcImg.copyTo(resizeImg(Rect(0, 0, col, row)));
netInputImg = resizeImg;
}
blobFromImage(netInputImg, blob, 1 / 255.0, cv::Size(netWidth, netHeight), cv::Scalar(0, 0, 0), true, false);
net.setInput(blob);
float* netOutPutTensor = new float[10];
std::vector<cv::Mat> netOutputImg;
net.forward(netOutputImg, net.getUnconnectedOutLayersNames());
auto outLayer = netOutputImg.at(0);
float* pdata = (float*)outLayer.data;
for(int i = 0;i< outLayer.cols;i++)
{
output.push_back(pdata[i]);
}
return false;
}
/// <summary>
/// softmax
/// </summary>
/// <param name="input"></param>
void ClassifyNetC::softmax(std::vector<float>& input) {
float maxn = 0.0;
float sum = 0.0;
maxn = *max_element(input.begin(), input.end());
std::for_each(input.begin(), input.end(),
[maxn, &sum](float& d) {
d = exp(d - maxn);
sum += d; }); //cmath c11
std::for_each(input.begin(), input.end(), [sum](float& d) { d = d / sum; });
return;
}
[6]. CAlgorithmModule::Process函数执行逻辑编写;
Process函数在界面点击执行时触发,可编写模块执行逻辑;顺序一般为:获取输入->算法处理->模块输出;示例代码如下:
int CAlgorithmModule::Process(IN void* hInput, IN void* hOutput, IN MVDSDK_BASE_MODU_INPUT* modu_input)
{
//定义变量
int nErrCode = IMVS_EC_UNKNOWN;
int nModuStatu = 0;
double fStart = AlgCommon_TimeMilliseconds();
std::vector<float> output;
std::string className = "";
float ClassifyConfidence = 0.0f;
try
{
// 1.获取输入
HKA_IMAGE inputimage;
int nLen;
if (modu_input->pImageInObj->GetPixelFormat() == MVD_PIXEL_MONO_08)
{
inputimage = { HKA_IMG_MONO_08 ,0 };
inputimage.width = modu_input->pImageInObj->GetWidth();
inputimage.height = modu_input->pImageInObj->GetHeight();
inputimage.step[0] = inputimage.width;
nLen = inputimage.height * inputimage.width;
}
else
{
inputimage = { HKA_IMG_RGB_RGB24_C3,0 };
inputimage.width = modu_input->pImageInObj->GetWidth();
inputimage.height = modu_input->pImageInObj->GetHeight();
inputimage.step[0] = inputimage.width * 3;
nLen = inputimage.height * inputimage.width * 3;
}
char* pSharedName = NULL;
nErrCode = AllocateSharedMemory(m_nModuleId, nLen, (char**)(&inputimage.data), &pSharedName);//申请共享内存代替malloc
if (inputimage.data[0] != NULL&&IMVS_EC_OK == nErrCode)
{
memset(inputimage.data[0], 0, nLen);
memcpy_s(inputimage.data[0], nLen, modu_input->pImageInObj->GetImageData(0)->pData, modu_input->pImageInObj->GetImageData(0)->nSize);
}
// 2.算法处理
Mat img = HKAImageToMat(inputimage);//算子图像转Mat
if (!isLoadModel)//模型加载
{
nErrCode = (int)classifyNet.readModel(net, m_chModelPathName, false); // 加载模型
if (IMVS_EC_OK == nErrCode)
isLoadModel = true;
}
if (isLoadModel)//模型预测
{
classifyNet.Detect(img, net, output);
classifyNet.softmax(output);
int maxPosition = max_element(output.begin(), output.end()) - output.begin();
className = myClassType[maxPosition];
ClassifyConfidence = output[maxPosition];
nErrCode = IMVS_EC_OK;
}
// 3.输出结果
HKA_IMAGE output_image = MatToHKAImage(img);//Mat转算子
if (IMVS_EC_OK == nErrCode)
{
if (modu_input->pImageInObj->GetPixelFormat() == MVD_PIXEL_MONO_08)
{
VmModule_OutputImageByName_8u_C3R(hOutput, 1, "OutImage", "OutImageWidth",
"OutImageHeight", "OutImagePixelFormat", &inputimage, 0, pSharedName);
}
else if (modu_input->pImageInObj->GetPixelFormat() == MVD_PIXEL_RGB_RGB24_C3)
{
VmModule_OutputImageByName_8u_C3R(hOutput, 1, "OutImage", "OutImageWidth",
"OutImageHeight", "OutImagePixelFormat", &inputimage, 0, pSharedName);
}
VM_M_SetString(hOutput, "ClassifyResult", 0, className.c_str());
VM_M_SetFloat(hOutput,"ClassifyConfidence",0, ClassifyConfidence);
}
}
catch (const std::exception&)
{
nErrCode = IMVS_EC_UNKNOWN;
}
//设置模块状态
if(IMVS_EC_OK == nErrCode)
VM_M_SetInt(hOutput, "ModuStatus", 0, 1);
else
VM_M_SetInt(hOutput, "ModuStatus", 0, 0);
double fEnd = AlgCommon_TimeMilliseconds();
//统计模块耗时
MODULE_RUNTIME_INFO struRunInfo = { 0 };
struRunInfo.fAlgorithmTime = fEnd - fStart;
VM_M_SetModuleRuntimeInfo(m_hModule, &struRunInfo);
return nErrCode;
[7]. 编译C++算法工程,生成dll文件复制到模块配置文件夹内。
2.2.5 模块打包测试
[1]. 打包部署
i.将包含模块配置xml、界面库dll及算法库dll的文件夹复制到\VisionMaster4.3.0\Applications\Module(sp)\x64\UserTools文件夹下;
ii.将对应版本opencv运行时库opencv_world470.dll复制到系统环境变量文件夹下,如:D:\Program Files\VisionMaster4.3.0\Applications\PublicFile\x64路径下。
iii.打开VM拖拽模块测试;
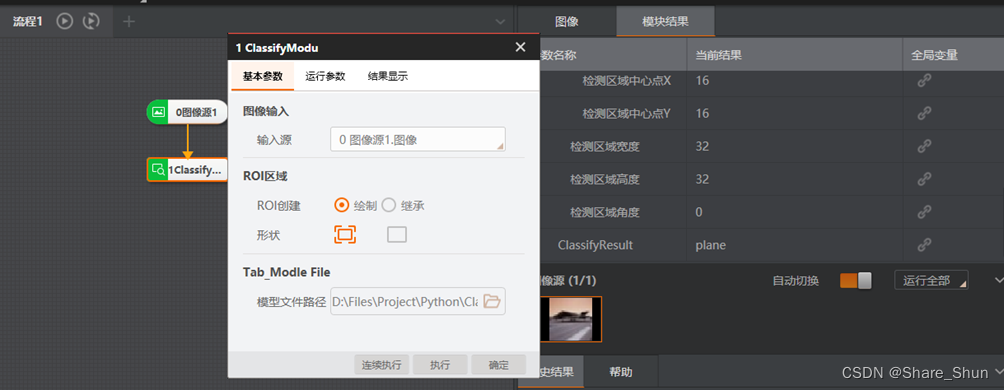
[2]. 断点调试
调试方法:
i. 将算法工程输出目录改为VM模块目录;
ii. 工程本地调试命令内添加VisionMaster.exe路径;
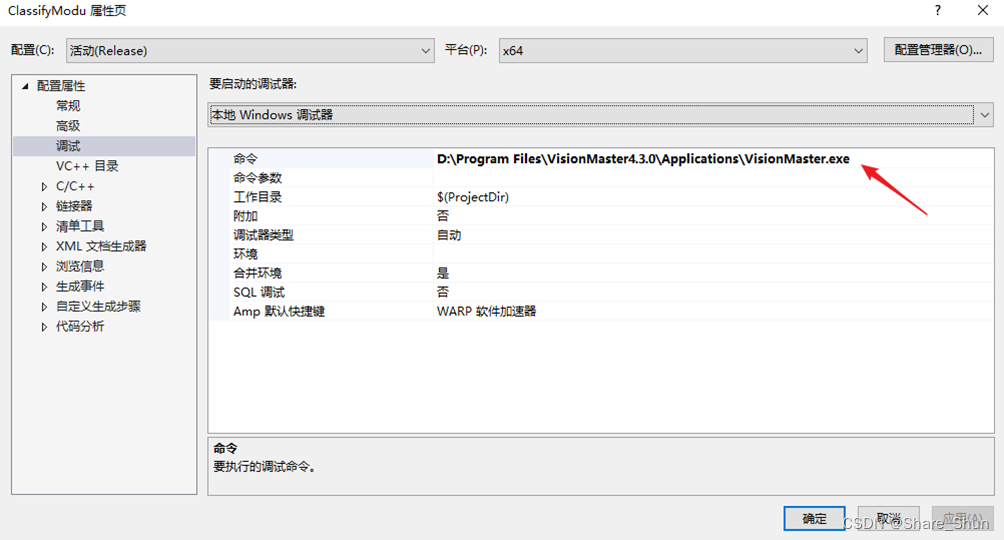
iii. 代码内添加断点,点击本地Windows调试器进行调试
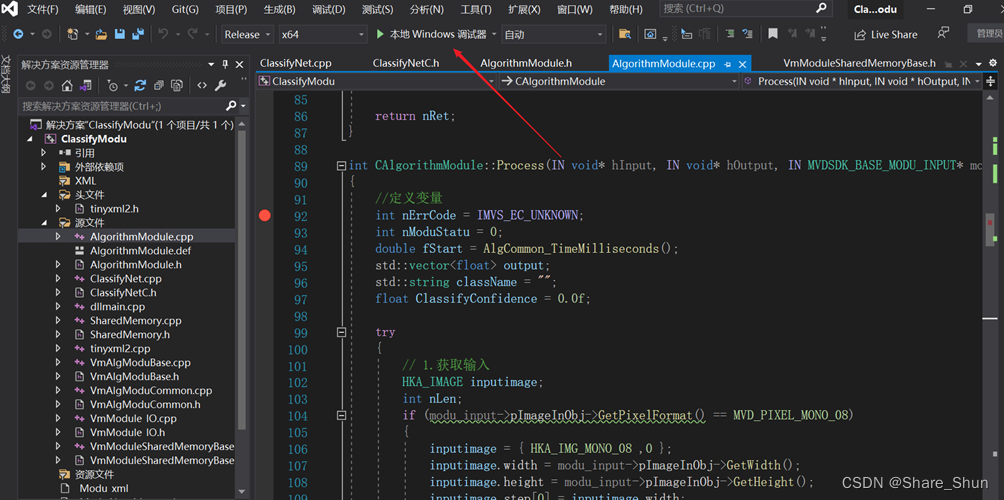
3 结果篇
3.1 分类模块运行结果
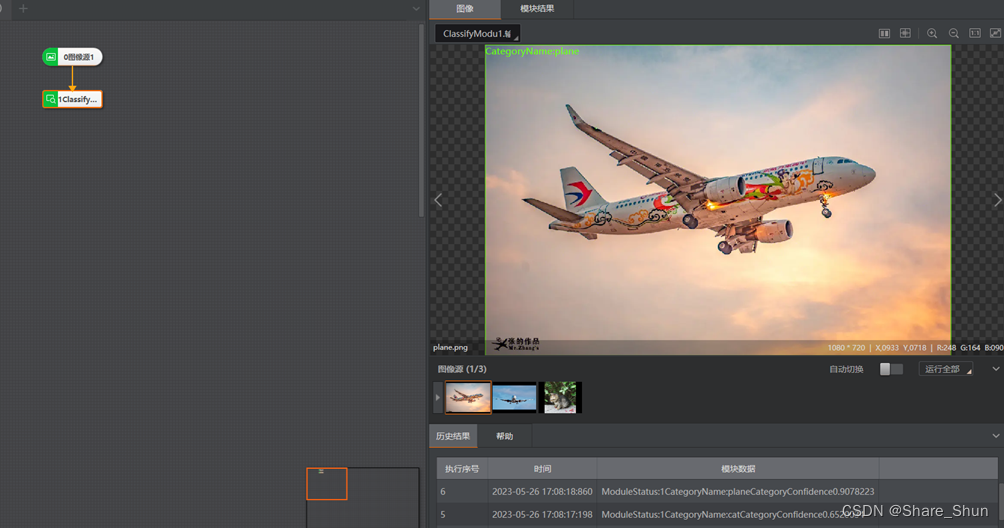
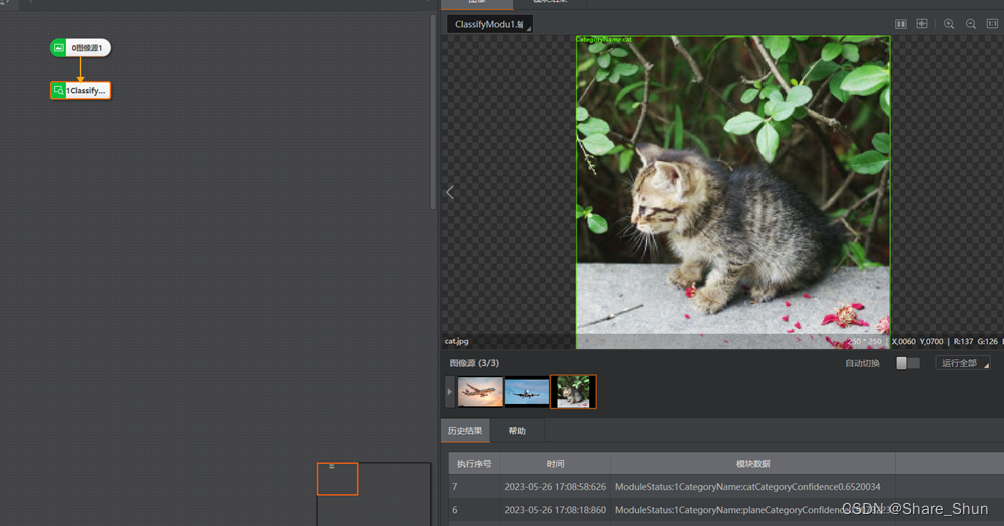
3.2 目标检测模块运行结果
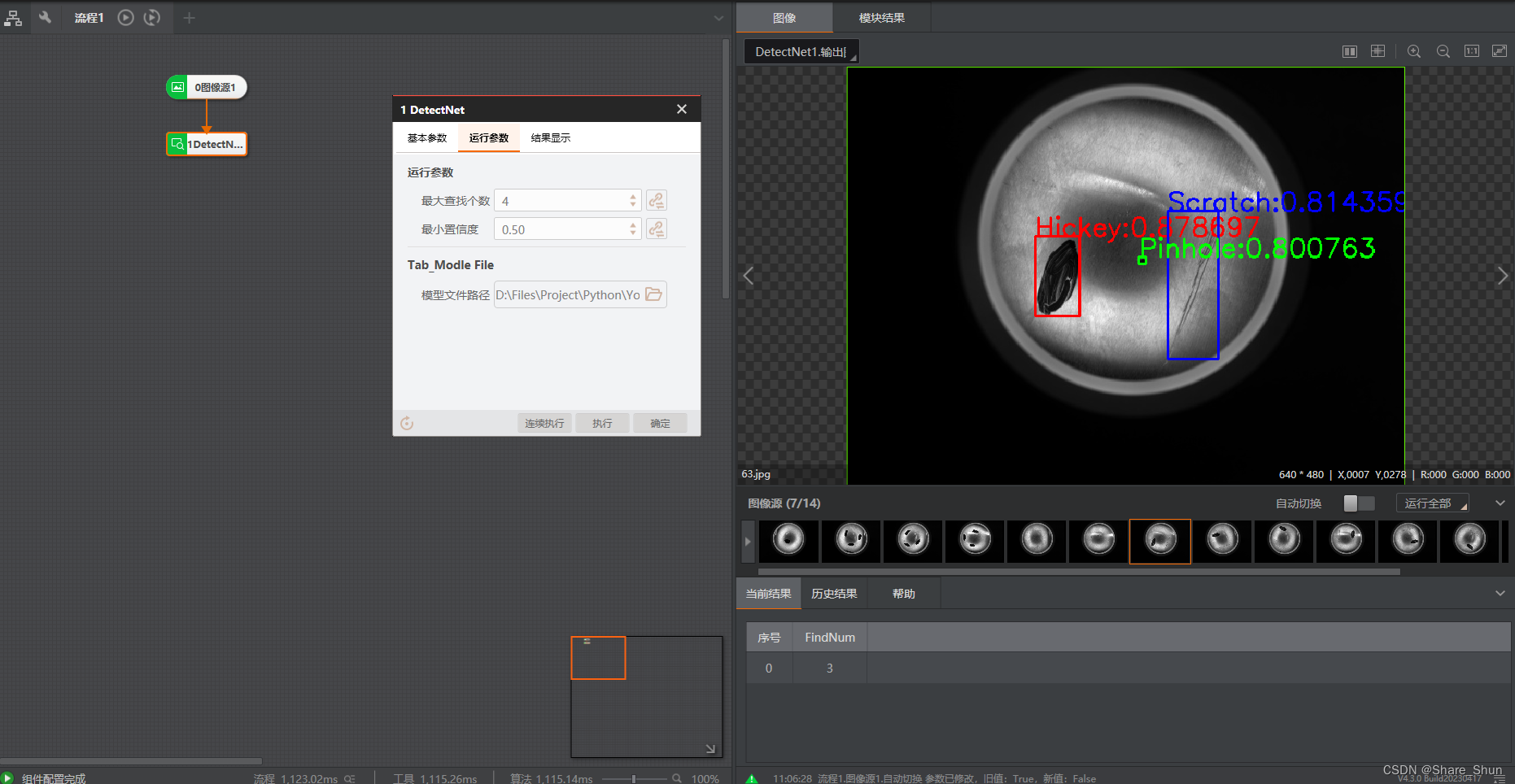
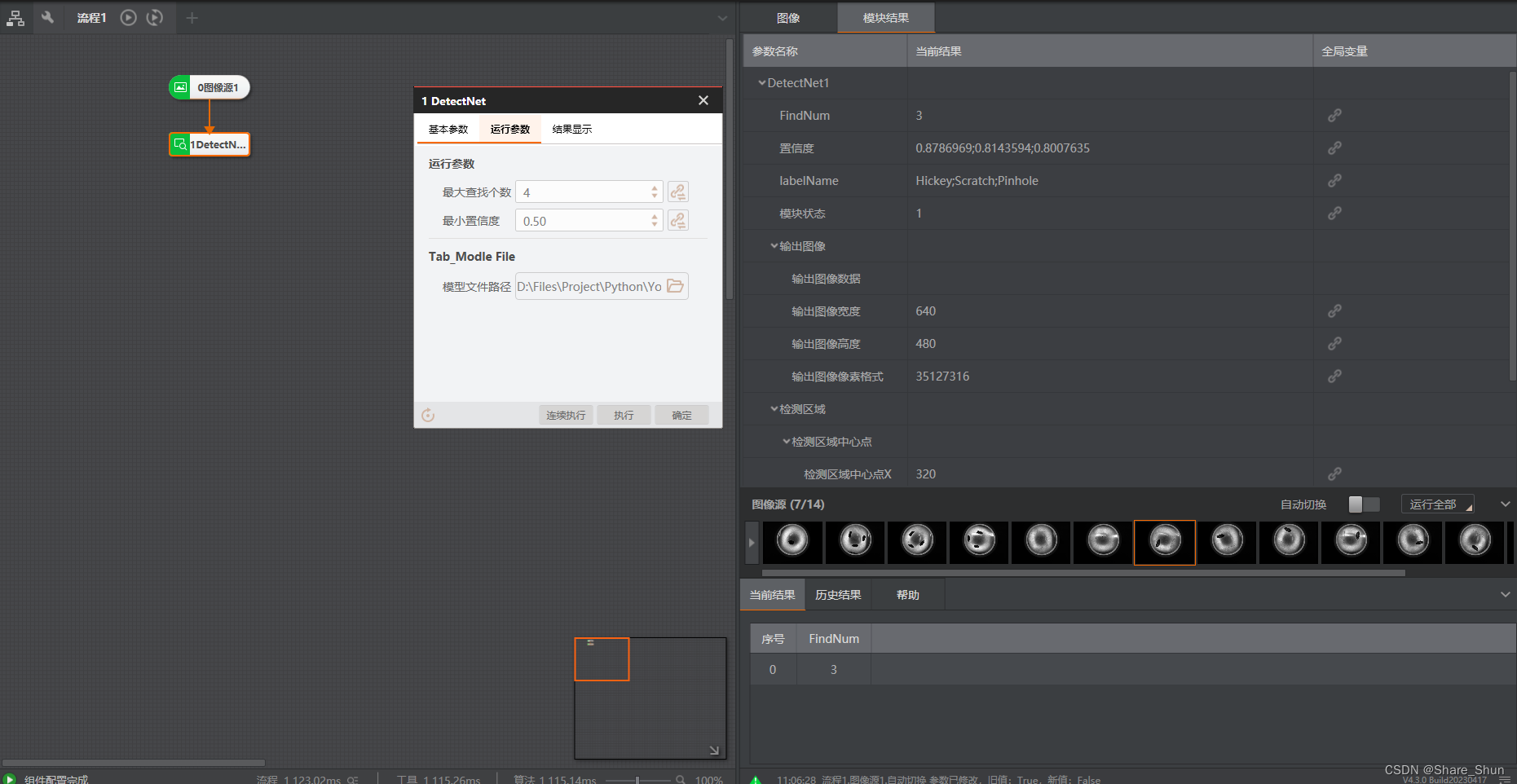


















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









