







数据库基础
一、学习任务
1、数据库基本概念
2、数据库常用的数据类型
3、数据库约束
4、数据库DDL
5、三大范式
6、数据库DML
7、数据库DQL
8、数据库高阶概念
二、授课进程
1、数据库安装【略过】
2、数据库相关概念
- 数据库:存储数据的仓库。
- 用什么方式存的? 文件
- 数据库管理系统
- 用来管理数据库的软件。比如:MySQL,Oracle,db2,sybase
- 数据:计算机中用来保存信息使用符号。文字、图片、视频、声音
- 人生存的世界:信息世界
- 计算机的世界:数据世界
- 数据库系统或数据库应用系统
- 使用数据库来完成特定业务的软件
3、数据库发展历史
- 使用普通文件保存数据:文件型数据
- 方便使用,不便于管理和维护
- 关系型数据库
- 方便使用,便于维护和管理,效率有不足之处
- 关系-对象型数据库
- 方便软件的设计与实现
4、关系型数据库核心概念
-
关系:一张符合特定要求的二维表。 二维:行和列
- 行:记录、实体
- 列:字段、属性
-
关系型数据库:由二维表构成的数据库
-
关系之间的关系,说白了表和表之间的关系
- 一对一:
- 一对多:
- 多对多:
-
数据库管理系统(DBMS)分类
- 关系型数据
- ACCESS
- MS SQL SERVER
- DB2
- Sybase
- Oracle
- MySQL
- NoSQL数据库: 非关系型
- Redis
- MongoDB
- HBase
- Memcache
- 内存数据库
- extrmeDB
- Oracle timesten
- solidDB
- sqlite
- H2 database
- 关系型数据
-
数据库操作语言:结构化查询语言(SQL structure query language)
- DDL:数据定义语言
- DML:数据操作语言
- DQL:数据查询语言
- DCL:数据控制语言
5、DDL
-
环境配置
-
安装navicat
-
配置系统的环境变量 win键+r
-
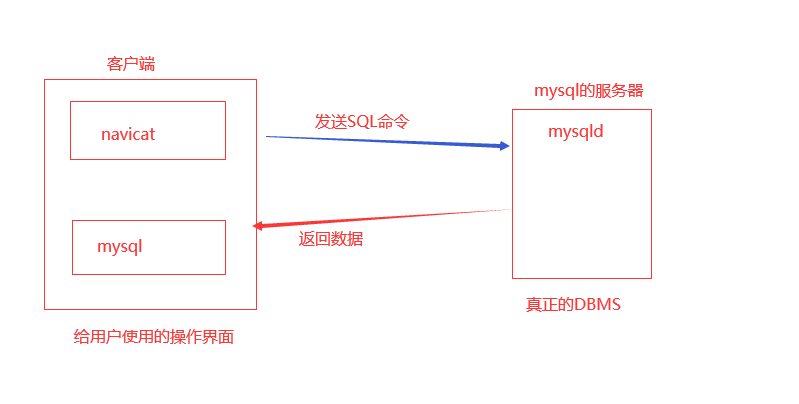
使用命令行来连接数据库服务器
mysql -u root -p-u : 用户名
-p:输入密码
-h:跟ip地址
-P:跟端口号,默认3306
-
-
create 命令
-
创建数据库
create database [if not exists] <dbname> character set utf8;[if not exists] :如果后面的数据库名不存在,则创建数据库,否则不创建;[] 代表可选的语法
<dbname> :必须要填写数据库名。 <> 表示必填
dbname命名规范
- 首字符的要求
- Unicode 标准 3.0 所定义的字母(包括拉丁字母 a-z 和 A-Z,以及来自其它语言的字母字符)
- 下划线 (_)、at 符号 (@) 或者数字符号 (#)
- 后续的字符
- 可以是字母、数字
- 符号只能是@、$、_
- 不允许使用保留字:create、drop、MySQL使用的命令单词
- 保留字:MySQL自己已经使用过的单词。
- 推荐用法:使用有业务含义的单词加后缀来命名。比如:demo_db, demo_tbl
- utf8: 字符编码格式,统一字符编码集8位版,兼容中文和各国文字。
- SQL语言大小写不敏感,不区分大小写,A和a是一个意思。
- 首字符的要求
-
修改数据库的字符集
alter database <dbname> character set 'utf8'; -
删除数据库
drop database <dbname>;
-
-
创建表
-
语法
create table <tbname>( 字段名 数据类型(长度) 约束类型 , ............ , 字段名 数据类型(长度) 约束类型 )engine=innodb [character set 'utf8'] -
数据类型
-
数字类型
-
整数
- tinyint 极小整数 (-128,127)(0,255) 占 1字节
- int 整数 (-2147483648,2147483647)(0,4294967295) 占 4 字节
- bigint 大整数 占8字节
-
小数:浮点数
-
float 单精度浮点数 精度:7位小数 占4字节
-
double 双精度浮点数 精度:15位小数 占8字节
-
decimal 大浮点数 精度:30位小数 占17字节
-
-
定义方法【重点】
- age int(3)
- salary float(7,2): 7包含小数位
- distance decimal(30,29)
-
-
字符串
- 定义:在SQL语言中使用单引号括起来的数据统称为字符串。‘’
- 类型
- char(n) 定长字符串 范围:0-255
- varchar(n) 变长字符串 范围:0-65535
- text(n) 文本型 范围:0-65535
- binary(n) 二进制字符串 范围:0-n
- char和varchar的区别【重点】
- 使用空间的方式不同:char(10)尽管你可能只存了’test’,实际还是分配10字符的空间。varchar(10),也是存放’test’,只需要分配4个字符的空间。
- char处理速度要快于varchar
- 如果能够预估所存内容的长度,就用char,比如身份证号。如果没有办法预估内容的长度,就用varchar,比如姓名。家庭住址,个人爱好。
- 使用方法
- sname varchar(20)
-
日期
- 类型
- year yyyy
- date yyyy-mm-dd
- time HH:MM:SS
- timestamp yyyy-mm-dd HH:MM:SS
- datetime yyyy-mm-dd HH:MM:SS
- 使用方式:
- birthday date,
- 类型
-
二进制【了解】
- tinyblob 0-255
- blob 65k
- mediumblob 16M
- longblob 4G
-
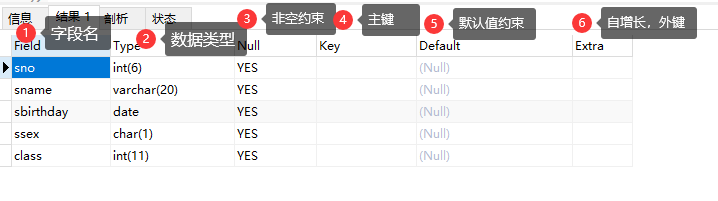
查看表结构
-
desc <tbname>
-
show create table <tbname>
show create table student; CREATE TABLE `student` ( `sno` int(6) DEFAULT NULL, `sname` varchar(20) DEFAULT NULL, `sbirthday` date DEFAULT NULL, `ssex` char(1) DEFAULT NULL, `class` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8
-
-
-
6、约束类型
-
概念
- 什么是约束:为了保证数据库中的数据的完整性、准确性而设置一些限制规则。
-
数据的完整性
- 实体完整性:约束记录的
- 域完整性:field,字段里面数据的完整性
- 参照完整性:约束表和表之间的引用关系的完整性
- 自定义完整性:用户自己定义的一些要求
-
主键约束
-
什么是主键?
- 它是数据表中的一个或者多个字段的组合。
-
主键的作用是什么?
- 唯一标识一行记录。
- 排序,帮助提高查询效率
-
怎么设置主键
-
定义表的时候,设置主键
create table class( id int primary key, # primary key 的作用就是标记该字段是主键 class_name varchar(10) )engine=innodb;在指定的字段名后面加上primary key,标记该字段为主键。
这种用法只能指定一个字段做主键。
-
复合主键设置
create table class( id int , class_name varchar(10), primary key(id,class_name) # 使用primary key(字段列表)来指定复合主键 )engine=innodb;以上两种方法都无法解决一个问题:创建数据表的时候,忘记定义主键,过后又需要主键
-
通过修改表结构的方法增加主键
CREATE TABLE student ( sno INT ( 6 ), sname VARCHAR ( 20 ), sbirthday date, ssex CHAR ( 1 ), class INT )engine=innodb ; alter table student add sno int primary key; # alter table 可以实现变更表结构,来加上约束 alter table course add primary key(cno); #直接增加一个主键 alter table student modify sno int primary key; desc student;alter table 命令中涉及到的关键字
add #增加字段,增加约束 modify # 修改字段的类型或约束,不能改字段名 change # 可以修改字段名,类型,约束 alter table teachar change department depart int; alter table teachar change depart department varchar(10); drop #删除字段,或者约束 alter table score drop primary key; # 删除主键 -
随堂练习:
- 给上一节课创建的数据表增加主键约束,score表不要加
-
设置主键有没有注意事项?
- 最少性:作为主键的字段,越少越好。能用一个字段做主键,就不要用两个。
- 稳定性:作为主键的字段,数据的变更频率越低越好。
-
-
-
非空约束
-
什么是非空约束?
- 指的是字段的数据不允许为空
-
作用就是当被非空约束的字段在插入数据的时候,必须要赋值。
-
如何设定非空约束
-
定义表的时候,在字段名的数据类型后面加上,not null即可。
-
变更表的方式去追加 not null。
alter table student modify sname varchar(20) not null; # 定义表结构的时候,增加not null create table demo( sname varchar(20) not null, resume varchar(200) not null )
-
注意事项:
1、使用了非空约束的时候,插入数据就一定要赋值。
2、非空可以和默认值、唯一约束、检查约束一起组合使用
-
-
默认值约束
-
可以给字段设置默认值,当插入数据的时候,如果没有给字段赋值,就会自动使用默认值
-
设置方法: 字段名 数据类型 default 默认值
-
sbirthday date default '2000-1-1' # 改表结构的方式 alter table student modify class int default 1;
-
随堂练习:
1、给原来的表加上非空、默认值约束,注意分析哪些字段需要非空,哪些字段需要默认值。
-
-
自增长
- 被约束字段在数据记录增加的时候其值会自动递增。解释:在原来的最大值的基础上自动加1
- 语法: 字段名 数据类型 auto_increment;
- 注意事项:
- 一般搭配主键使用
- 每个表只允许一个自动使用这个约束
- 自增长的序列是单独存放的,也就是我们删除最后一条记录,不影响序列。
- truncate table 删除数据,这种删除无法回复。
-
检查约束
- MySQL不支持检查约束,设置了可选内容的约束
- 也就是给字段设置了检查约束,那么字段的值只能在指定的范围内挑选
- 设置方式
- 字段名 enum(‘v1’,‘v2’,…)
- 字段名 set(‘v1’,‘v2’,…)
- enum只能从指定的值里面任选一个,set可以多选
- MySQL不支持检查约束,设置了可选内容的约束
-
唯一约束
- 被唯一约束字段,它的值不可重复
- 设置方法: 字段名 数据类型 unique
- 注意事项
- unique使用的时候,字段的业务含义需要符合唯一要求。
- unique不能和默认值约束一起用。
- 随堂练习
- 给student字段的ssex设置检查约束
- 给所有主键设置自增长约束
-
外键约束
-
外键是什么? 字段
-
作用是什么?
- 从表中用来和主表进行建立关联关系的字段
- 主表是拥有主键的表,而引用主表的主键的表称为从表
- 主键字段被其他的表引用的表就是主表
- 引用其他表的主键字段的表就是被引用的表的从表
-
如何设置外键约束
-
定义表的时候,设置外键
create table score( sno int, cno int, degree int, foreign key(sno) references student(sno), foreign key(cno) references course(cno) )engine=innodb; -
变更表结构的方式设置
alter table course add foreign key(tno) references teachar(tno) on delete restrict on update cascade; # 翻译: course的tno引用teachar表主键tno,不允许删除主键,可以和主键一起变更。 -
随堂练习
- 给成绩表,课程表加上外键约束,自己判断那个字段是外键,那个字段是主键
-
-
注意事项
-
2个行为,4种约束方式
- update 更新数据
- delete 删除数据
-
4种约束方式
- restrict 拒绝变更,没有删除或变更从表的数据,主表不允许变化
- no action 效果同上
- cascade 级联操作:如果主键的值发生变化,外键跟随变化
- set null 设置外键为空:如果主键发生变化,外键的值设为空,前提是外键没有非空约束。如果有,效果同restrict。
-
删除外键
-
语法
-
alter table <tbname> drop foreign key 外键名;
-
-
-
7、DML数据操作语言
-
insert:把数据插入到数据表中
-
语法:
# 最完整的语法 insert into <tbname>(字段列表) values(值列表) # 懒人的语法 insert into <tbname> values(值列表) # 除了自增长id字段,其他的字段都必须给数据 # 批量插入数据 insert into <tbname>(字段列表) values(值列表),(值列表),......插入数据的原则:
1、字段列表中个数和值的个数一一对应
2、字段列表中各字段的数据类型和值一一对应
3、字段列表中字段和值的对应顺序一一对应
个数一致、类型一致、顺序一致
-
示例:
insert into student(sname,ssex,class,sbirthday) values('丽丽','女',95233,'2002-10-5'); insert into student(sname,ssex,class,sbirthday) values ('欧阳修','女',95233,'2002-10-5'), ('李白','女',95233,'2002-1-5'), ('王伟','男',95233,'2002-10-15'); -
随堂练习
- 学生表中插入10条学生信息
- 课程表插入五门课程信息
- 教师表插入5名教师信息
-
-
update:对数据表中的数据进行变更(修改)
-
语法
-
update <tbname> set 字段名=值[,字段名=值],..... [where 条件表达式] # where子句缺少,就会把整个表中指定的字段的值改成同一个。 # where子句的作用限制修改的范围
-
-
where子句
-
条件表达式:运算结果为true或者false的运算公式,例如:A=3
-
运算符
- 算术运算符:+、-、*、/、mod、power、sqrt
- 比较运算符:>,<,=,>=,<=,<> 或 != ; 用法:A>3,A>=3
- 成员运算符:in,is
- 逻辑运算符:
- And : A=B and A>C, 这里可以看出and将其左右两边的条件表达式连接形成一个新的条件表达式
- 左右两边的条件表达式的结果都为true,新的表达式的结果才能为true,否则就是false
- or: A=B or A>C,只要or左右任何一个条件表达式的值为true,新的表达式的结果为true。
- not: not A=B,作用是取反,如果A=B成立,整个表达式的结果为false,反之为true
- And : A=B and A>C, 这里可以看出and将其左右两边的条件表达式连接形成一个新的条件表达式
-
示例
# 将学生信息表中的名字为丽丽的记录的学生名修改为李丽。 update student set sname='李丽' where sname='丽丽'; # 将学生信息表中生日为'2000-1-1'并且学号为4的学生的生日修改为'2003-3-19' update student set sbirthday='2003-3-19' ,class=95535 where sbirthday='2000-1-1' and sno=4;
-
-
-
delete: 删除表中的数据记录
-
语法
-
delete from <tbname> [where 子句] # 删除满足条件的数据记录,where子句起到条件限制的作用
-
-
示例
-
# 删除学生姓名为空的记录 delete from student where sname is null; # 删除学生姓名为空字符的记录 delete from student where sname ='';
-
-
truncate table <tbname> #清空全表数据,初始化自增长序列,不能违反外键约束。
-
-
随堂练习
- 删除数据表中自己认为不正确的数据记录
- 修改课程表中的课程编号,使用4位整数做编号
- 修改教师表中老师的工号tno,使用4位整数,注意检查外键约束
- 修改学生信息表,其中的class使用以下数据中的任一个:95033,95031,95035,95036
-
小结
- delete 删除数据的话,如果删除操作放在事务中,事务没有提交之前,可以恢复。
- truncate 删除数据的同时初始化自增长序列,无法恢复。
- drop 删除表和表结构。
8、DCL命令
-
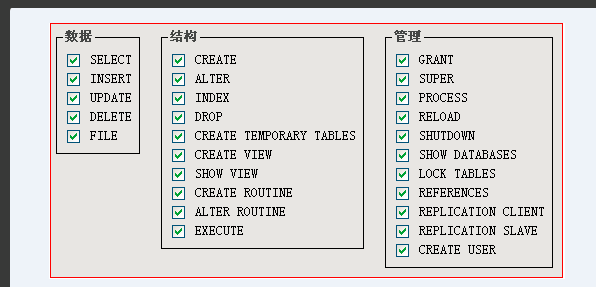
grant:授权
-
权限:用户可以使用的数据库操作或命令
-
语法:
-
grant <权限列表> on 数据库.对象名 to '用户名'@'允许登录的地址' identified by '密码' -
权限列表:
- 分的比较细: select,update,delete,insert
- 使用 all privilege 代替所有权限。
-
对象名:表table、视图view、过程procedure; *.* 代表所有的数据库中的所有对象
-
如果用户名不存在,grant可以创建用户。
-
-
示例
-
给root用户分配远程访问的权限**【重点】**
grant all privileges on *.* to 'root'@'%' identified by 'root123'; flush privileges; # 刷新权限缓存
-
-
-
revoke:解除权限
-
语法
revoke <权限列表> on 数据库名.对象名 from '用户名'@'允许登录的地址' -
示例
-
收回dbtester对woniusales数据库的插入数据权限
-
revoke insert on woniusales.* from 'dbtester'@'%';
-
-
9、三大范式
- 范式:normal format设计数据表的标准格式。
- 意义:如果要设计一套关系型数据库表,必须要严格的按照范式执行。
- 数据库范式有多少?
- 目前有6大范式,一个比一个严格。第4,5,6范式企业还没有使用
- 第一范式;
- 表中的字段不可拆分
- 第一范式中有哪些问题
- 数据的新增、删除、修改都会产生异常
- 第二范式:
- 表中每一行必须唯一,非主键必须完全依赖主键
- 表中每一行必须唯一:避免出现重复数据,数据冗余
- 非主键必须完全依赖主键:我们在建表的时候,可能会使用复合主键,
- 建表的时候必须要设立主键,而且能用一个字段做主键,就不要用两个
- 第二范式继承了第一范式的问题
- 表中每一行必须唯一,非主键必须完全依赖主键
- 第三范式:
- 每列都和主键直接相关,而不是间接相关
- 拆分表格
- 后遗症:表和表之间数据的完整性怎么保持?
- 外键约束
- 连接查询解决多张表的字段需要显示的问题
- 后遗症:表和表之间数据的完整性怎么保持?
- 小结
- 第二范式浪费空间,但是查询效率。
- 第三范式节省空间,查询效率低。
10、DQL
-
select: 筛选数据
-
语法
select [distinct] 字段名,字段名,... from 表名 [where 子句] [group by 分组字段] [having子句] [order by 子句] [limit分页条件] -
最简查询
select * from tablename;
缺点:当数据表的数据量非常大的时候,响应速度极慢。
* 代表返回数据表中的所有字段,如果需要返回具体的字段,需要使用字段名替换*
select sno,sname from student;
-
使用指定的条件进行查询,需要使用where子句来设置筛选的条件
# 查询生日是2000-1-1之后的学生的姓名 select sname,sbirthday from student where sbirthday>'2000-1-1' and ssex='女'; -
范围查询:
-
select * from table where 18<=age and age<=30; select * from table where age between 18 and 30; -
between … and … : 包含边界值
-
-
排序
-
关键字:order by
-
排序的类型: 升序:ASC 缺省模式。 降序:DESC
-
语法:
-
order by 字段名 ASC|DESC
-
-
示例
-
# 查询学生成绩,按照分数倒序排序 select * from score order by degree desc; # 查询学生信息,按照学号进行排序 select * from student order by sno ;
-
-
多字段排序**【重点】**
-
语法
-
order by 字段名1 ASC|DESC , 字段名2 ASC|DESC , ... -
例如: 查询学生的成绩,按照分数进行倒序排序,按照学号进行升序排序
-
先按照分数倒序排序,如果分数出现了相同的值再按照学号升序排
-
select * from score order by degree DESC, sno ;
-
-
-
模糊查询
-
关键字: like
-
语法
-
where 字段名 like 表达式; -
表达式和通配符
- %:代表任意个任意字符
- _ :代表任意的一个字符
-
示例
-
# 查询学生信息表中张姓同学的信息 select * from student where sname like '张%' ; # 查询学生信息表中张姓或李姓的同学的信息 【难点】 select * from student where sname like '张%' or sname like '李%'; -
注意: 表达式中通配符可以放多个,也可以放在字符串的任意位置
-
-
-
查重
-
去掉返回的数据中重复记录,称为查重
-
关键字: distinct
-
语法
-
select distinct 字段列表 from tablename [where 子句]
-
-
distinct用法
-
使用在统计函数中,目的是对被统计字段进行先去重后统计的作用
-
select count(distinct degree) from tablename;
-
-
-
distinct的位置**【难点】**
- 放在select后面,对筛选出来的记录去重
- 放在函数里面,对被统计的字段去重
-
-
分页查询
-
控制查询返回的记录数量
-
关键字 limit
-
语法
-
limit x,y -
x: 表示查询起点的行数,从0开始计数,缺省就是0,也就是第一条记录。
-
y:表示需要返回y行
-
-
示例
-
# 查询成绩中最高分的记录 select * from score order by degree desc limit 1; # 查询全班成绩的前三名 select * from score order by degree desc limit 3; # 查询全班成绩的第5名到第10名 select * from score order by degree desc limit 4,6;
-
-
-
-
分组查询和聚合函数
-
聚合函数:对指定字段进行统计计算,计算的结果只有一个。
-
sum(字段名):求和
-
count(字段名|*|数字):计数
-
# 查询demo表中的记录数 select count(*) from demo ; # 查询demo表中的班级的数量 ,当使用字段名为参数的时候,会自动筛选非空记录 select count(class) from demo; # 查询demo表中的班级的数量 select count(1) from demo where class is not null;
-
-
avg(字段名):求平均值
-
max(字段名):求最大值
-
min(字段名):求最小值
-
-
聚合函数中去掉NULL记录的简便写法
-
ifnull(字段名,0) : 如果字段的值为NULL,则使用0代替
# 查询demo表中的degree平均值 select avg(ifnull(degree,0)) from demo;
-
-
分组查询
-
什么叫分组:分类查询
-
语法
-
select 分类字段 , 聚合函数(字段名) from tablename group by 分类字段 [having 子句]
-
-
示例
-
# 查询学生表中男女数量 select ssex , count(*) from student group by ssex; # 查询每科成绩的平均分 select cno,avg(degree) from score group by cno;
-
-
having子句
-
作用:对分组之后的记录进行筛选
-
# 查询每个学员的平均分及格的记录 select sno,avg(degree) from score group by sno having avg(degree)>=60;
-
-
having和where的区别
- 作用对象不一样:having作用于分组后的数据,where是作用于分组前的数据
- 位置不一样:having只能放在group by后面,where只能方法group by前面
-
-
-
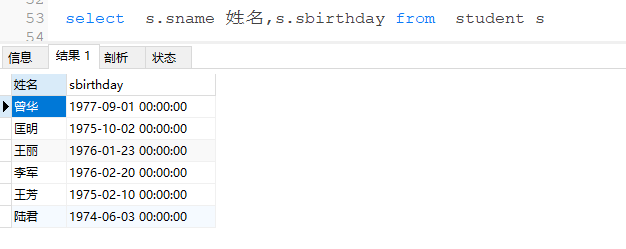
查询中的别名系统
-
别名的作用:把复杂的表达式简单化,将子查询的返回的数据作为表使用
-
select sno,avg(degree) as avgrlt from score group by sno having avgrlt>=60;
-
-
别名的两种写法
- 字段名 as 别名
- 字段名 别名
-
别名影响的对象
- 字段
- 表
-
示例
-
-
-
多表查询
-
连接查询
-
连接种类
- 内连接
- 外连接
- 左外连接
- 右外连接
-
图示
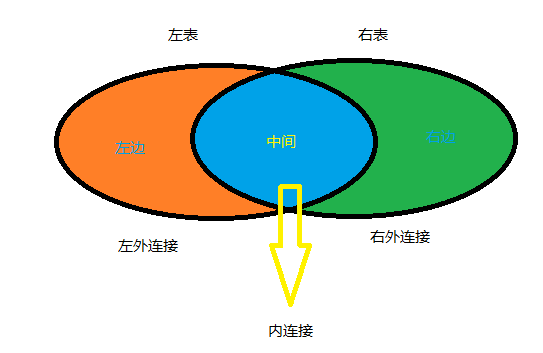
-
查询中的表达方式
-
内连接
-
简洁方式
-
select * from a ,b where a.pk=b.fk [and 条件表达式]
-
-
完全方式
-
select * from a inner join b on a.pk=b.fk [where 子句]
-
-
懒汉方式
-
select * from a join b on a.pk=b.fk [where 子句]
-
-
特点
- 只有两边都匹配上的数据才显示,其他数据不显示
-
-
外连接
-
左外
-
select * from a left join b on a.fk=b.pk -
特点:
- 左表的数据全部显示,右表和左表匹配上的显示,匹配不上的数据显示为NULL
-
-
右外
-
select * from a right join b on a.fk=b.pk -
特点:
- 右表的数据全部显示,左表和右表匹配上的显示,匹配不上的数据显示为NULL
-
-
-
-
使用场景
- 当查询返回的数据在多张表中时候,就需要使用连接查询
- 先确认表和表之间的关联关系,根据关联关系进行连接,注意选择连接的类型。
-
-
子查询
-
子查询指的是嵌入到其他的SQL语句中的查询语句
-
特性
- 子查询的返回是一个虚表,存放内存中一个二维表
-
作用
- 作为数据源,用来存放数据
- 当返回结果为单列,可以用来查询条件中的数据
-
演示
-
-- 20、查询成绩总分大于150分的学员信息 -- 当显示的字段在同一个数据表中,而涉及到的又是多张表的时候,可以选择子查询 select * from student where sno in (select sno from score group by sno having sum(degree)>150 ) -- 21、查询成绩总分大于150分的学员信息和总分 select s.*,a.total from student s,(select sno,sum(degree) total from score group by sno having total>150) a where s.sno=a.sno -- 22、查询成绩总分大于150分的学员信息和总分、平均分 select s.*,a.total,a.avgdegree from student s,(select sno,sum(degree) total,avg(degree) avgdegree from score group by sno having total>150) a where s.sno=a.sno -
in和exists 【重点】
IN 操作符执行顺序:
- 首先查询子查询的表
- 将内表和外表做一个笛卡尔积
- 使用where条件进行筛选
所以相对而言,内表比较小的时候,in的速度较快!
EXISTS 操作符执行顺序:
- 查询外表,遍历循环外表
- 将外表的数据代入到子查询中,判断子查询返回True还是False
- 如果返回True,则将外表循环的数据加入到返回结果集中;否则,不加入
- 最后,将结果集中数据返回给用户
所以相对而言,内表比较多的时候,exists的速度较快!
-
-
-
组合查询
-
定义:就是将多个查询的返回结果进行组合显示
-
语法:
-
(select语句) union | union all (select 语句)
-
-
特性
- 组合查询之后字段数量不会增加,只增加记录数
-
适用场景
-
需要将不同的数据表当中的同类的数据进行组合显示的时候
-
-- 25、查询女性教师的姓名和生日以及女生姓名和生日 select tname 姓名,tbirthday 生日 from teacher where tsex='女' union select sname,sbirthday from student where ssex='女'
-
-
union 和union all区别
- union自动去重,union all不会去重
-
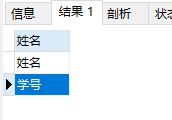
特殊的用法
-
select '姓名' union select '学号' -
-
-
-
-
三、查漏补缺
1、左外右外:数据匹配的多少,如果没有多出来的部分就看不到null的部分
2、左外和右外什么时候用? 查询需求里面是否有需要全部显示左表或者右表的数据
3、外键是什么?作用?怎么用?注意事项?
4、select语句执行顺序:
- from
- join on
- where
- group by
- having
- select
- order by
- distinct
- limit
5、DCL:远处赋权语句
6、拿到查询需求怎么写出查询语句
- 看需要显示的字段:目的是定位第一个数据源
- 看筛选条件: 目的是定位第二张表
- 分析这些表之间是否存在关联关系
- 如果有,选择连接类型,连表
- 如果没有,查找两张表的中间表,选择连接类型,连表。
- 分析筛选条件,构造where子句
- 在确定分组,主要看需求之中有没有聚合函数方面的需求
- 确定分组字段
- 确定聚合的类型
- 再确定分组之后的筛选条件
- 排序
- 查重
- 分页
7、having和where在什么时候用
- 如果筛选条件的字段在分组后有出现,where和having都可以
- 如果筛选条件的字段在分组之后不出现,必须使用where
- 比如:查询张老师所带的平均分及格的学生姓名和平均分。tname不会在分组之后出现,先用where筛选
- 比如:查询平均分及格的学号大于102的学号和平均分。sno在分组后还有,所以可以是where也可以使用having解决。
8、什么时候用and,什么时候用or
9、成员运算符:子查询用的多
10、自连接:连接查询的一个特例,表自己和自己连接
- 雇员表:雇员编号、姓名、部门经理编号; emp
- select * from emp e1,emp e2 where e1.empno=e2.managerid
11、多字段分组
- select f1,f2,sum(f4) from tbname group by f1,f2
- f1会重复出现
- 查询各系的学生考试总分
12、数据库学习对于测试工程师工作意义?
- 如果是自主设计实现测试框架,需要用到三范式、约束、数据类型来设计数据库和表。
- 如果做性能测试,需要用到三范式、数据类型、查询优化、索引、试图、缓存
- 如果做功能测试:约束、增删改查,最多的是查询。
- 如果做数据库开发:复杂查询
img-PgOupW0S-1669104378467)]
三、查漏补缺
1、左外右外:数据匹配的多少,如果没有多出来的部分就看不到null的部分
2、左外和右外什么时候用? 查询需求里面是否有需要全部显示左表或者右表的数据
3、外键是什么?作用?怎么用?注意事项?
4、select语句执行顺序:
- from
- join on
- where
- group by
- having
- select
- order by
- distinct
- limit
5、DCL:远处赋权语句
6、拿到查询需求怎么写出查询语句
- 看需要显示的字段:目的是定位第一个数据源
- 看筛选条件: 目的是定位第二张表
- 分析这些表之间是否存在关联关系
- 如果有,选择连接类型,连表
- 如果没有,查找两张表的中间表,选择连接类型,连表。
- 分析筛选条件,构造where子句
- 在确定分组,主要看需求之中有没有聚合函数方面的需求
- 确定分组字段
- 确定聚合的类型
- 再确定分组之后的筛选条件
- 排序
- 查重
- 分页
7、having和where在什么时候用
- 如果筛选条件的字段在分组后有出现,where和having都可以
- 如果筛选条件的字段在分组之后不出现,必须使用where
- 比如:查询张老师所带的平均分及格的学生姓名和平均分。tname不会在分组之后出现,先用where筛选
- 比如:查询平均分及格的学号大于102的学号和平均分。sno在分组后还有,所以可以是where也可以使用having解决。
8、什么时候用and,什么时候用or
9、成员运算符:子查询用的多
10、自连接:连接查询的一个特例,表自己和自己连接
- 雇员表:雇员编号、姓名、部门经理编号; emp
- select * from emp e1,emp e2 where e1.empno=e2.managerid
11、多字段分组
- select f1,f2,sum(f4) from tbname group by f1,f2
- f1会重复出现
- 查询各系的学生考试总分
12、数据库学习对于测试工程师工作意义?
- 如果是自主设计实现测试框架,需要用到三范式、约束、数据类型来设计数据库和表。
- 如果做性能测试,需要用到三范式、数据类型、查询优化、索引、试图、缓存
- 如果做功能测试:约束、增删改查,最多的是查询。
- 如果做数据库开发:复杂查询
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









