






事务的隔离性上,从低到高可能产生的读现象分别是:脏读、不可重复读、幻读。
脏读指读到了未提交的数据。
不可重复读指一次事务内的多次相同查询,读取到了不同的结果。
幻读师不可重复读的特殊场景。一次事务内的多次范围查询得到了不同的结果。
通过在写的时候加锁,可以解决脏读。
通过在读的时候加锁,可以解决不可重复读。
通过串行化,可以解决幻读。
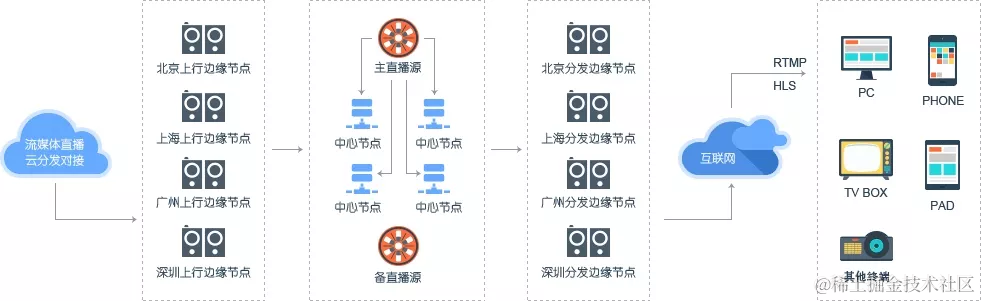
据了解,2018年1月,阿里云为虎牙提供了边缘节点服务(ENS)。基于阿里云ENS,可以轻松地将业务模块放到边缘运行,在主播的推流时,实现就近节点进行转码和分发,同时支持了高并发实时弹幕的边缘分发。在获得网络低时延的同时,减少了对中心的压力,节省了30%以上的中心带宽成本,并且实现了边缘节点网络连接小于5毫秒延时,提升了主播上行质量,以及用户成功连接占比等数指标,有效提升了用户观看体验。ENS中最主要的技术就是CDN。
CDN的全称是Content Delivery Network,即内容分发网络。
"内容分发网络"就像前面提到的"全国仓配网络"一样,解决了因分布、带宽、服务器性能带来的访问延迟问题,适用于站点加速、点播、直播等场景。使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度和成功率。
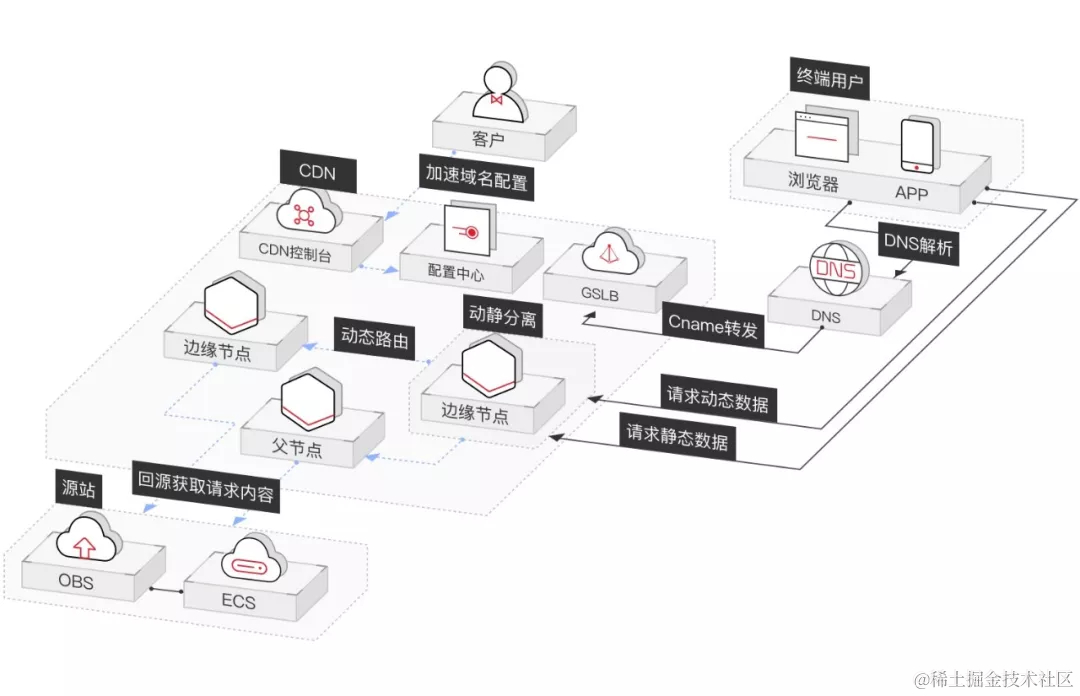
CDN全局负载均衡设备与CDN区域负载均衡设备根据用户IP地址,将域名解析成相应节点中缓存服务器的IP地址,实现用户就近访问,从而提高服务端响应内容的速度。
CDN的组成
一个仓配网络是由多个仓库组成的,同理,内容分发网络(CDN)是由多个节点组成的。一般来讲,CDN网络主要由中心节点、边缘节点两部分构成。
中心节点
中心节点包括CDN网管中心和全局负载均衡DNS重定向解析系统,负责整个CDN网络的分发及管理。
边缘节点
CDN边缘节点主要指异地分发节点,由负载均衡设备、高速缓存服务器两部分组成。
负载均衡设备负责每个节点中各个Cache的负载均衡,保证节点的工作效率;同时还负责收集节点与周围环境的信息,保持与全局负载均衡DNS的通信,实现整个系统的负载均衡。
高速缓存服务器(Cache)负责存储客户网站的大量信息,就像一个靠近用户的网站服务器一样响应本地用户的访问请求。通过全局负载均衡DNS的控制,用户的请求被透明地指向离他最近的节点,节点中Cache服务器就像网站的原始服务器一样,响应终端用户的请求。因其距离用户更近,故其响应时间才更快。
中心节点就像仓配网络中负责货物调配的总仓,而边缘节点就是负责存储货物的各个城市的本地仓库。
目前,主要由很多提供CDN服务的云厂商在各地部署了很多个CDN节点,拿阿里云举例,我们可以在阿里云的官网上了解到:阿里云在全球拥有2500+节点。中国大陆拥有2000+节点,覆盖34个省级区域,大量节点位于省会等一线城市。海外和港澳台拥有500+节点,覆盖70多个国家和地区。
1、如何妥善的将货物分发到各个城市的本地仓。
2、如何妥善的各个本地仓存储货物。
3、如何根据用户的收货地址,智能的匹配出应该优先从哪个仓库发货,选用哪种物流方式等。
4、对于整个仓配系统如何进行管理,如整体货物分发的精确度、仓配的时效性、发货地的匹配度等。
CDN中最重要的四大技术不谋而合,那就是内容发布、内容存储、内容路由以及内容管理等。
内容发布
它借助于建立索引、缓存、流分裂、组播(Multicast)等技术,将内容发布或投递到距离用户最近的远程服务点(POP)处。
内容存储
对于CDN系统而言,需要考虑两个方面的内容存储问题。一个是内容源的存储,一个是内容在 Cache节点中的存储。
内容路由
它是整体性的网络负载均衡技术,通过内容路由器中的重定向(DNS)机制,在多个远程POP上均衡用户的请求,以使用户请求得到最近内容源的响应。
内容管理
它通过内部和外部监控系统,获取网络部件的状况信息,测量内容发布的端到端性能(如包丢失、延时、平均带宽、启动时间、帧速率等),保证网络处于最佳的运行状态。
使用Spring的@Autowired和@Qualifier注解来注入名为"cassandraSession"的Session bean。通常,@Autowired用于自动装配Spring容器中的bean,而@Qualifier用于指定要注入的bean的名称(或者使用@Primary注解来指定首选的bean)。在这种情况下,它注入了名为"cassandraSession"的Cassandra数据库会话(Session) bean,以便在代码中使用该会话执行Cassandra数据库操作。
这样的注入允许您在Spring管理的组件中访问Cassandra数据库会话,以便执行相关的数据库操作,如查询、插入、更新或删除数据。
LinkedHashMap是Java中的一个类,它继承自HashMap类,具有以下特点:
有序性:
LinkedHashMap保留了元素的插入顺序,即当您遍历LinkedHashMap时,元素的顺序与它们插入到映射中的顺序相同。这使得LinkedHashMap可以按照插入的顺序迭代元素。允许空键和空值:与
HashMap一样,LinkedHashMap允许您在映射中使用null键和null值。性能:
LinkedHashMap的性能与HashMap类似,因为它们都基于哈希表实现,具有O(1)的平均时间复杂度的插入、查找和删除操作。线程不安全:
LinkedHashMap不是线程安全的,如果需要在多个线程之间共享,需要考虑使用同步机制或线程安全的替代品(如ConcurrentHashMap)。用途:由于其有序性,
LinkedHashMap通常用于需要维护元素顺序的情况,例如LRU(最近最少使用)缓存。
以下是创建和使用LinkedHashMap的简单示例:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapExample {
public static void main(String[] args) {
// 创建一个LinkedHashMap
Map<String, Integer> linkedHashMap = new LinkedHashMap<>();
// 向LinkedHashMap添加元素
linkedHashMap.put("one", 1);
linkedHashMap.put("two", 2);
linkedHashMap.put("three", 3);
// 遍历LinkedHashMap并按插入顺序输出元素
for (Map.Entry<String, Integer> entry : linkedHashMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}输出将按照元素插入的顺序:
one: 1
two: 2
three: 3一个名为 "esRestBulkProcessor" 的 BulkProcessor bean 注入到当前类中的 esRestBulkProcessor 字段中,以便在后续的代码中使用 esRestBulkProcessor 来执行批量处理操作,通常用于与 Elasticsearch 进行批量索引或删除等操作。
RestHighLevelClient bean 注入到当前类中的 esRestHighLevelClient 字段中,以便在后续的代码中使用 esRestHighLevelClient 来访问 Elasticsearch 的高级 REST 客户端功能。
使用了 Elasticsearch 的 Java 高级 REST 客户端(
esRestHighLevelClient)执行查询请求,这是一个优化点,确保您的应用已正确配置并引入了 Elasticsearch 客户端依赖。在构建 Elasticsearch 查询时,使用了布尔查询构建器
BoolQueryBuilder,这样可以更灵活地构建查询条件。代码中使用了分页参数
from和size来控制查询结果的分页,这是一个良好的做法,确保查询结果可以分页返回。在处理查询结果时,将命中的文档数据提取出来并存储在
retList中,然后将总记录数和查询结果存储在ElasticSResultSet中返回。这个过程很清晰和高效。matchAllQuery():创建一个匹配所有文档的查询。matchQuery(String name, Object text):创建一个匹配字段name包含文本text的查询。multiMatchQuery(Object text, String... fieldNames):创建一个多字段匹配查询,用于匹配多个字段包含文本text的文档。termQuery(String name, Object value):创建一个精确匹配查询,用于匹配字段name的值等于value的文档。boolQuery():创建一个布尔查询,用于组合多个查询条件,支持与、或、非等逻辑运算符。rangeQuery(String name):创建一个范围查询,用于匹配字段name的值在指定范围内的文档。wildcardQuery(String name, String query):创建一个通配符查询,用于匹配字段name的值符合通配符表达式query的文档。regexpQuery(String name, String regexp):创建一个正则表达式查询,用于匹配字段name的值符合正则表达式regexp的文档。idsQuery():创建一个文档ID查询,用于匹配指定文档ID的文档。termsQuery(String name, String... values):创建一个字段值包含在给定值列表中的查询。existsQuery(String name):创建一个存在性查询,用于匹配具有字段name的文档。
QueryBuilder.batch() 和 QueryBuilder.unloggedBatch() 在 Apache Cassandra 中有不同的用途和行为:
QueryBuilder.batch(): 这是标准批处理(logged batch)。使用这种类型的批处理时,Cassandra 会将所有批处理中的操作写入日志,然后在后台应用这些操作。这意味着如果批处理中的某些操作失败,它们将被回滚,并且在应用中可以检测到失败的操作。这对于需要事务性保证的操作非常有用,因为它确保了 ACID 特性。
优点:提供了事务性保证,可以回滚失败的操作,适用于需要强一致性和事务性的场景。
缺点:写入操作会被日志记录,可能会引入一些性能开销。
QueryBuilder.unloggedBatch(): 这是无日志批处理(unlogged batch)。使用这种类型的批处理时,Cassandra 不会将操作写入日志,而是尽可能快速地将它们应用到数据中。这种批处理通常用于不需要事务性保证的情况,例如批量插入或更新操作,其中失败的操作不会回滚。
优点:更轻量级,适用于不需要事务性保证的场景,性能较高。
缺点:不提供事务性保证,失败的操作不会回滚。
因此,选择哪种类型的批处理取决于您的应用程序需求。如果您需要确保一组操作的事务性,以便在失败时回滚它们,应使用标准批处理(QueryBuilder.batch())。如果您只是希望提高性能,并且不需要事务性保证,那么无日志批处理(QueryBuilder.unloggedBatch())可能更合适。
// 创建 Cassandra 集群连接
Cluster cluster = Cluster.builder()
.addContactPoint("Cassandra 主机地址") // 设置 Cassandra 主机地址
.withPort(9042) // 设置 Cassandra 端口号,默认为 9042
.withCredentials("用户名", "密码") // 设置连接凭据,如果需要的话
.build();
// 获取 Cassandra 集群的元数据信息
Metadata metadata = cluster.getMetadata();
// 输出所有连接到集群的主机信息
for (Host host : metadata.getAllHosts()) {
logger.info("主机地址:" + host.getAddress());
}
// 输出集群中的所有键空间信息
for (KeyspaceMetadata keyspaceMetadata : metadata.getKeyspaces()) {
logger.info("键空间名称:" + keyspaceMetadata.getName());
}一些注释和优化建议:
在创建 Cassandra 集群连接时,确保设置正确的 Cassandra 主机地址、端口号和凭据(如果需要的话)。
使用
cluster.getMetadata()获取 Cassandra 集群的元数据信息,这允许您查看有关集群的一些基本信息。使用
metadata.getAllHosts()获取所有连接到集群的主机信息,这有助于了解集群中的节点。使用
metadata.getKeyspaces()获取所有键空间的信息,这对于查看可用键空间非常有用。创建 Cassandra 会话
Session session = cluster.connect(),以便可以执行查询和操作。最后,您准备了要插入的数据,并将其存储在
dataMap中。请确保在实际使用时将正确的值分配给键。
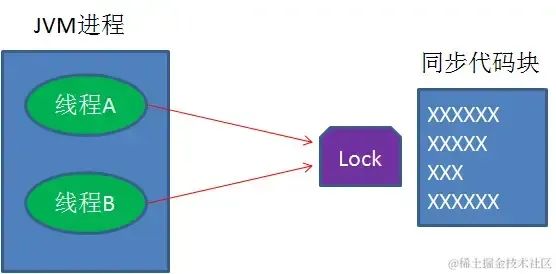
在多线程并发的情况下,如何保证一个代码块在同一时间只能由一个线程访问?
可以用锁来保证,比如java的synchronized语法,以及reentrantlock类等等。
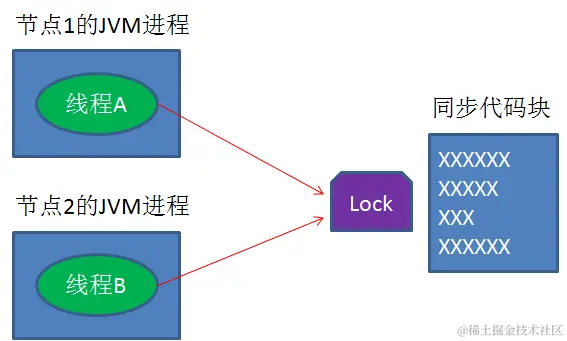 怎么能够在分布式系统中,实现不同线程对代码和资源的同步访问呢?
怎么能够在分布式系统中,实现不同线程对代码和资源的同步访问呢?
对于单进程的并发场景,我们可以使用语言和类库提供的锁。对于分布式场景,我们可以使用【分布式锁】
分布式锁?怎么才能实现 分布式系统中的 锁呢?
集群节点,副本同步,分区概念,同步消费异步消费
分布式锁的实现有哪些?
1.Memcached分布式锁
利用Memcached的add命令。此命令是原子性操作,只有在key不存在的情况下,才能add成功,也就意味着线程得到了锁。
2.Redis分布式锁
和Memcached的方式类似,利用Redis的setnx命令。此命令同样是原子性操作,只有在key不存在的情况下,才能set成功。(setnx命令并不完善,后续会介绍替代方案)
3.Zookeeper分布式锁
利用Zookeeper的顺序临时节点,来实现分布式锁和等待队列。Zookeeper设计的初衷,就是为了实现分布式锁服务的。
4.Chubby
Google公司实现的粗粒度分布式锁服务,底层利用了Paxos一致性算法。
如何用Redis实现分布式锁?
分布式锁实现的三个核心要素:
1.加锁
最简单的方法是使用setnx命令。key是锁的唯一标识,按业务来决定命名。比如想要给一种商品的秒杀活动加锁,可以给key命名为 “lock_sale_商品ID” 。而value设置成什么呢?我们可以姑且设置成1。加锁的伪代码如下:
setnx(key,1)
当一个线程执行setnx返回1,说明key原本不存在,该线程成功得到了锁;当一个线程执行setnx返回0,说明key已经存在,该线程抢锁失败。
2.解锁
有加锁就得有解锁。当得到锁的线程执行完任务,需要释放锁,以便其他线程可以进入。释放锁的最简单方式是执行del指令,伪代码如下:
del(key)
释放锁之后,其他线程就可以继续执行setnx命令来获得锁。
3.锁超时
锁超时是什么意思呢?如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住,别的线程再也别想进来。
所以,setnx的key必须设置一个超时时间,以保证即使没有被显式释放,这把锁也要在一定时间后自动释放。setnx不支持超时参数,所以需要额外的指令,伪代码如下:
expire(key, 30)
1. setnx和expire的非原子性
设想一个极端场景,当某线程执行setnx,成功得到了锁:
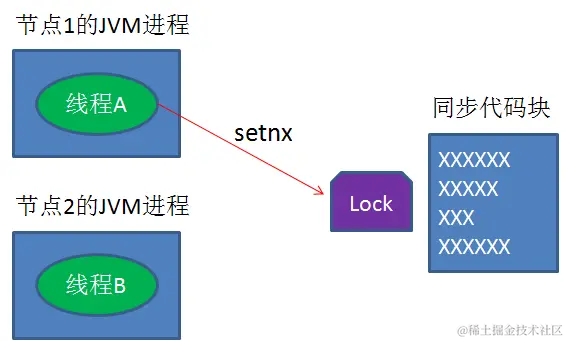
setnx刚执行成功,还未来得及执行expire指令,节点1 Duang的一声挂掉了。
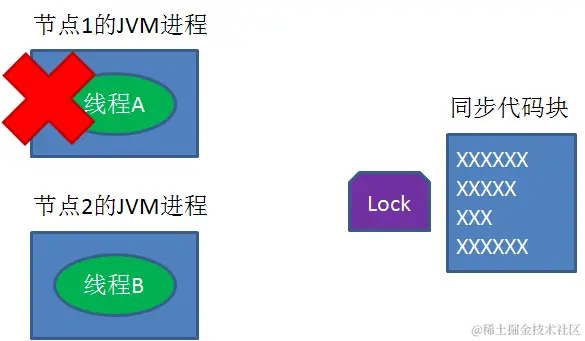
这样一来,这把锁就没有设置过期时间,变得“长生不老”,别的线程再也无法获得锁了。
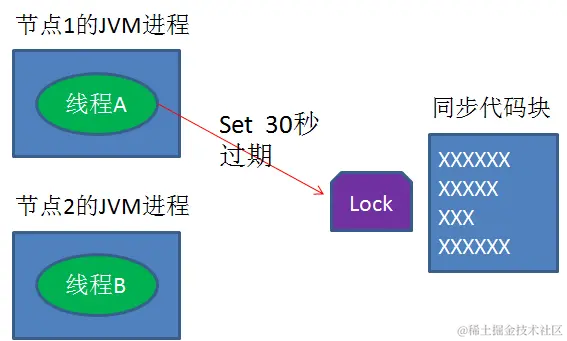
怎么解决呢?setnx指令本身是不支持传入超时时间的,幸好Redis 2.6.12以上版本为set指令增加了可选参数,伪代码如下:
set(key,1,30,NX)
这样就可以取代setnx指令。
2. del 导致误删
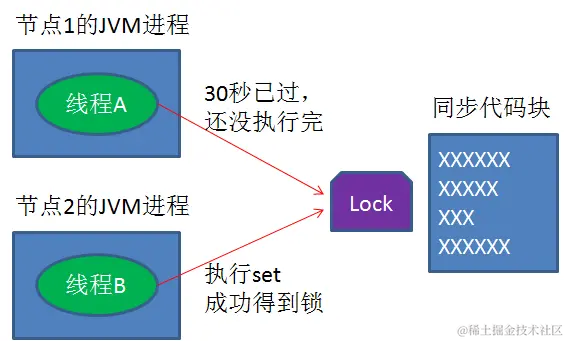
又是一个极端场景,假如某线程成功得到了锁,并且设置的超时时间是30秒。
如果某些原因导致线程B执行的很慢很慢,过了30秒都没执行完,这时候锁过期自动释放,线程B得到了锁。
随后,线程A执行完了任务,线程A接着执行del指令来释放锁。但这时候线程B还没执行完,线程A实际上删除的是线程B加的锁。
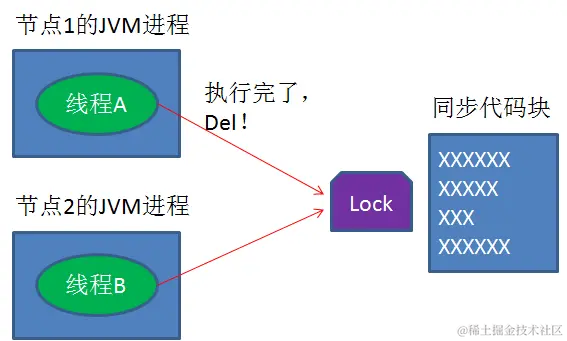
第一阶段,线程A刚开始查询优惠券缓存,线程B正尝试获取分布式锁:

第二阶段,由于缓存不存在,线程A开始查询数据库,线程B成功获得锁,开始更新缓存:

第三阶段,线程A尝试获得分布式锁,而线程B已经释放分布式锁:

第四阶段,线程A获得了锁,又一次更新缓存,而线程B已经成功返回:

就这样,缓存被重复更新了两次,所以再次出现数据重复的bug。
修改后的逻辑:
1.查询缓存,如果缓存存在,返回结果
2.缓存不存在,查询数据库
3.争夺分布式锁
4.成功获得锁,把查询数据库的结果循环放入缓存
5.释放分布式锁
修改后的逻辑:
1.查询缓存,如果缓存存在,返回结果
2.缓存不存在,查询数据库
3.争夺分布式锁
4.成功获得锁,再次判断缓存的存在
5.如果缓存仍旧不存在,把查询数据库的结果循环放入缓存
6.释放分布式锁
如何进行加密呢?
对称加密方式,并且约定一个随机生成的密钥。后续的通信中,信息发送方都使用密钥对信息加密,而信息接收方通过同样的密钥对信息解密。
使用非对称加密,为密钥的传输做一层额外的保护。
非对称加密的一组秘钥对中,包含一个公钥和一个私钥。明文既可以用公钥加密,用私钥解密;也可以用私钥加密,用公钥解密。
收到公钥以后,自己生成一个用于对称加密的密钥Key2,并且用刚才接收的公钥Key1对Key2进行加密
利用自己非对称加密的私钥,解开了公钥Key1的加密,获得了Key2的内容。
在通信过程中,即使中间人在一开始就截获了公钥Key1,由于不知道私钥是什么,也无从解密。
中间人虽然不知道私钥是什么,但是在截获了公钥Key1之后,却可以偷天换日,自己另外生成一对公钥私钥,把自己的公钥Key3发送。
是什么解决方案呢?难道再把公钥进行一次加密吗?这样只会陷入鸡生蛋蛋生鸡,永无止境的困局。
这时候,我们有必要引入第三方,一个权威的证书颁发机构(CA)来解决。
流程如下:
1.作为服务端,首先把自己的公钥发给证书颁发机构,向证书颁发机构申请证书。
2.证书颁发机构自己也有一对公钥私钥。机构利用自己的私钥来加密Key1,并且通过服务端网址等信息生成一个证书签名,证书签名同样经过机构的私钥加密。证书制作完成后,机构把证书发送给了服务端。
请求通信的时候,不再直接返回自己的公钥,而是把自己申请的证书返回。
收到证书以后,要做的第一件事情是验证证书的真伪。需要说明的是,各大浏览器和操作系统已经维护了所有权威证书机构的名称和公钥。所以只需要知道是哪个机构颁布的证书,就可以从本地找到对应的机构公钥,解密出证书签名。
按照同样的签名规则,自己也生成一个证书签名,如果两个签名一致,说明证书是有效的。
再次利用机构公钥,解密出服务端公钥Key1。
生成自己的对称加密密钥Key2,并且用服务端公钥Key1加密Key2
加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview














 2318
2318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









