







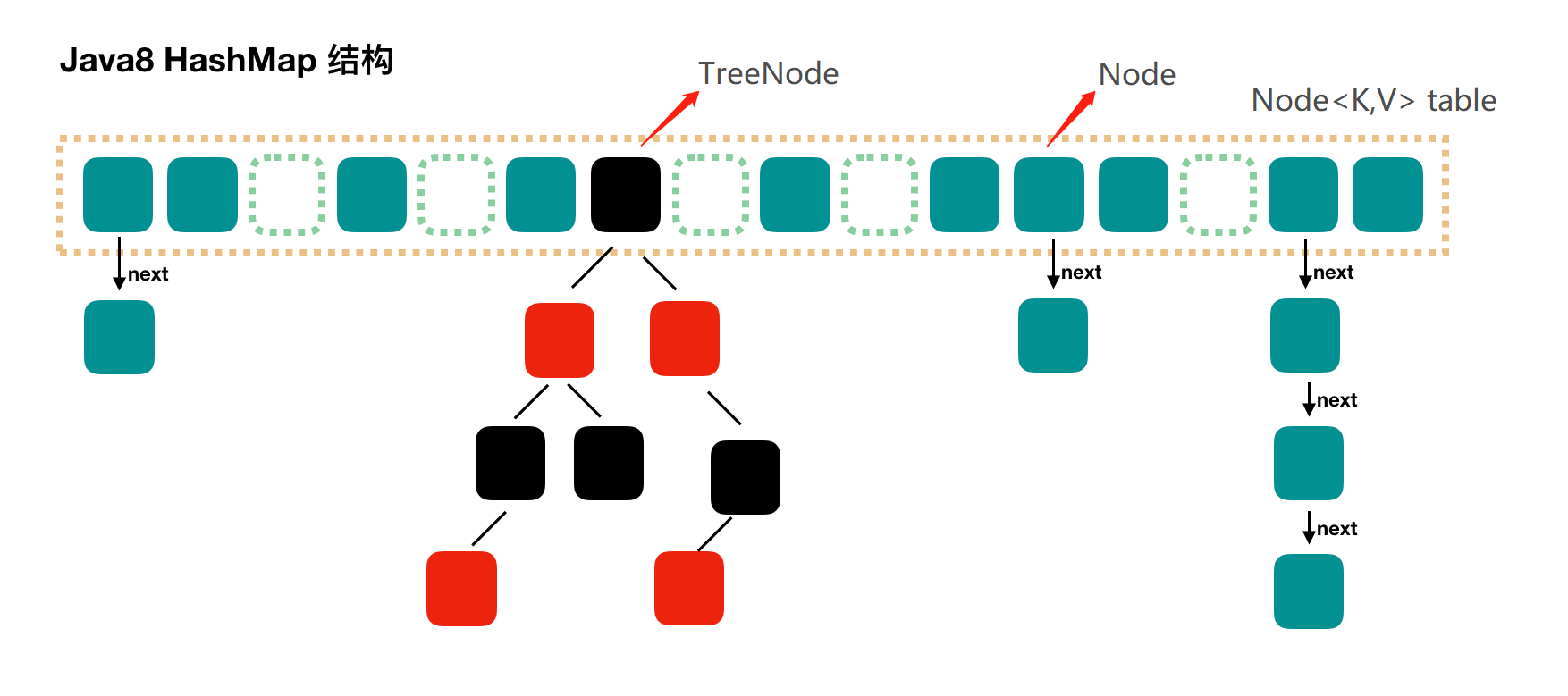
JAVA8中的HashMap
存储结构
HashMap中Table数组初始默认大小为16
HashMap 与2的幂次方
我们知道HashMap的容量总是2的幂次方.
那我们从两方面思考一下:
1.为什么一定要是2的幂次方?
2.如果给定的构造容量不是2的幂次方这时会怎样?
为什么是2^n?
我们都知道,要想让100个球放入10个桶中,需要通过100%10来计算每个球放入的桶序号
同理,在HashMap要将大量的数据存放在不同的数组中,我们需要使用:hash%table.size
来保证每个数据都有数组存且存储的数组不会越界
但是对于大计算量来说取余操作很慢
巧的是当n为2次幂时,会满足一个公式:(n - 1) & hash = hash % n
这样一来既能实现原先的功能速度又有了提升
hash(key)的改进
hash值是一个32位的数,如果仅仅和(2^n-1)相与,岂不是只有低位参与了运算,不同数产生hash碰撞的几率不就大大增加了么?
-----------------------------------------
java8中就此提出了一个改进:
首先将hash的高16位与低16位进行异或运算,让其相互影响;
接下来还是(n - 1) & hash 但是因为此时的低16位已经受到了高位的影响,其结果就会分散开来
整个过程就像晃动鸡尾酒一样
如果不是2^n会怎样?
假如小明就是不按常规出牌,给定HashMap的初试容量为17,此时HashMap的真实容量是?
答案:32
原因在下面这段代码里:
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
//cap-1后,n的二进制最右一位肯定和cap的最右一位不同,即一个为0,一个为1,例如cap=17(00010001),n=cap-1=16(00010000)
int n = cap - 1;
//n = (00010000 | 00001000) = 00011000
n |= n >>> 1;
//n = (00011000 | 00000110) = 00011110
n |= n >>> 2;
//n = (00011110 | 00000001) = 00011111
n |= n >>> 4;
//n = (00011111 | 00000000) = 00011111
n |= n >>> 8;
//n = (00011111 | 00000000) = 00011111
n |= n >>> 16;
//n = 00011111 = 31
//n = 31 + 1 = 32, 即最终的cap = 32 = 2 的 (n=5)次方
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap-resieze()
resize即HashMap中的扩容方法,那么什么时候会触发呢?
在避免产生更多次Hash碰撞时触发
--------------------------
==> 默认构造即初试容量为16
1.初始化HashMap
==> 给定容量
2.当前HashMap的容量大于阈值(threshold = DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACIT)
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // 对应数组扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将数组大小扩大一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 将阈值扩大一倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 对应使用 new HashMap(int initialCapacity) 初始化后,第一次 put 的时候
newCap = oldThr;
else {// 对应使用 new HashMap() 初始化后,第一次 put 的时候
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 用新的数组大小初始化新的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // 如果是初始化数组,到这里就结束了,返回 newTab 即可
if (oldTab != null) {
// 开始遍历原数组,进行数据迁移。
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果该数组位置上只有单个元素,那就简单了,简单迁移这个元素就可以了
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是红黑树,具体我们就不展开了
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 这块是处理链表的情况,
// 需要将此链表拆成两个链表,放到新的数组中,并且保留原来的先后顺序
// loHead、loTail 对应一条链表,hiHead、hiTail 对应另一条链表,代码还是比较简单的
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 第一条链表
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第二条链表的新的位置是 j + oldCap,这个很好理解
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
给Table扩容就是为了避免Hash碰撞,现在容量扩充了,就要对原来的链表进行拆分.
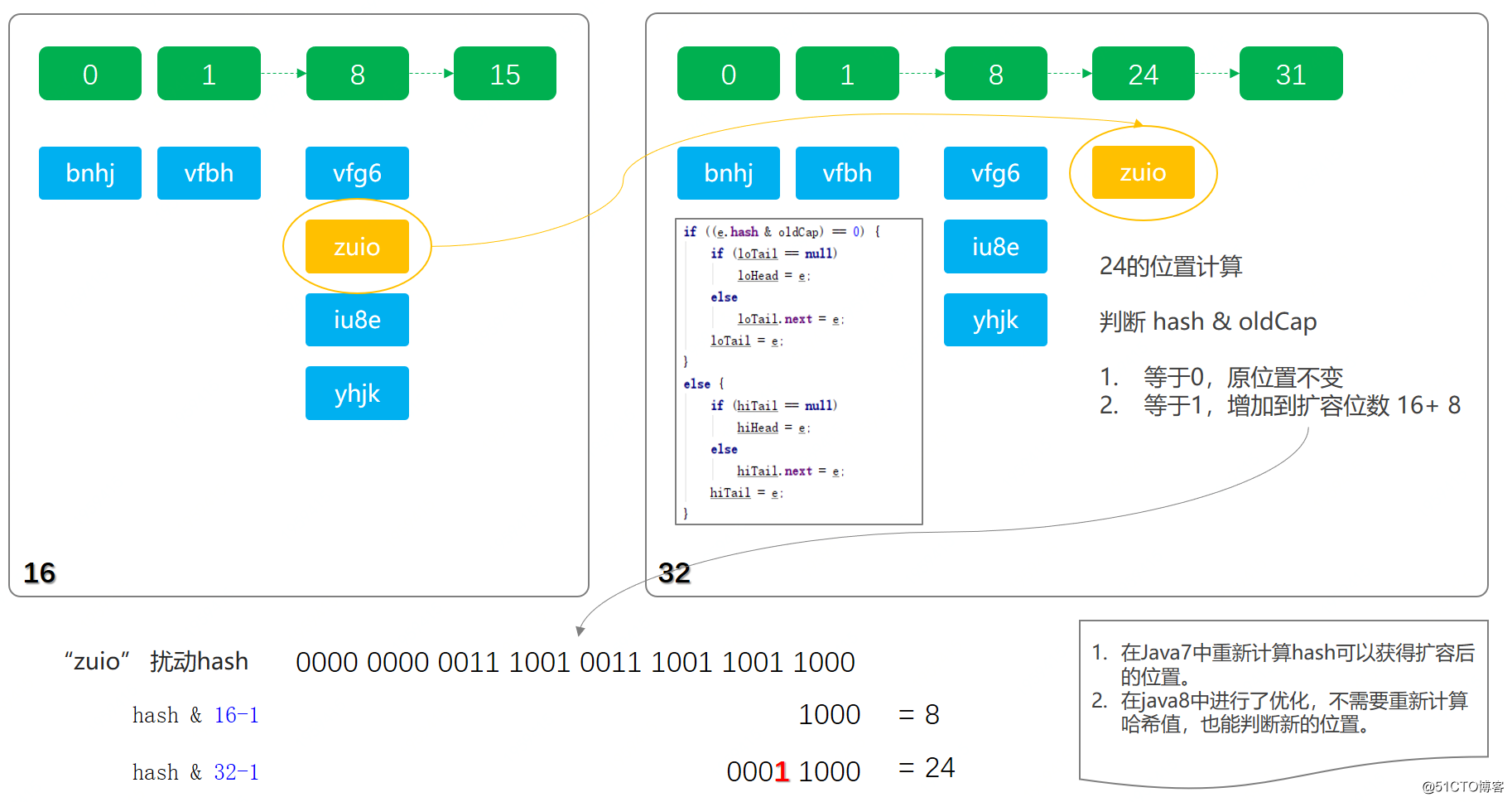 我们深入的想一下,当数组扩充之后再与Hash相与,其实相当于向前多取了(多考虑)了一位Hash值
我们深入的想一下,当数组扩充之后再与Hash相与,其实相当于向前多取了(多考虑)了一位Hash值
这一位其实就是oldCap的最高位(看上图)所对应的Hash值
若该位置的Hash值为0那不影响其相与的结果,所以还在原链表
若该位置的Hash值为1那相与的结果就会增加,而增加的大小正是oldCap 所以该结点去新的链表
参考:https://blog.51cto.com/u_14943622/3309790
http://www.bjpowernode.com/hot/2533.html
需要记住的一点就是:oldCap不仅是之前的容量,也是新老容量之差(容量扩为原来的2倍)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









