






目录
StoreFIle Compaction & Region Split
面对百亿数据,HBase为什么查询速度依然非常快?_努力成为咸鱼的博客-CSDN博客_hbase查询性能
为什么不用Mysql而用HBase?
1:Mysql是单机的数据库 而HBase是分布式数据库 后者可以应对更大的数据量
2:Mysql是行式存储,HBase是列式存储 适合于新增列以及多维表
3:HBase是Key\Value存储类型 适应于稀松数据
为什么不用Hive而用HBase?
Hive自己并不管理数据 只是对存在HDFS上的数据进行了表结构映射 本质上只是一个类SQL解析器来进行OLAP
HBase虽然数据最终也存储在HDFS上,但数据通过自己进行管理 最终存储的形式是二进制格式
是实打实的数据库(分布式HDFS的数据库)
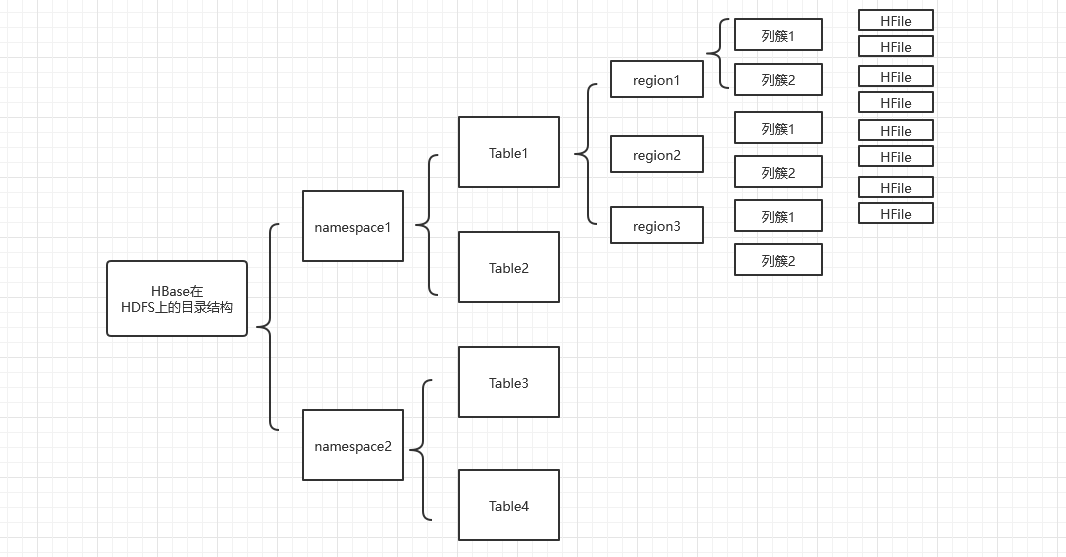
HBase存储逻辑结构

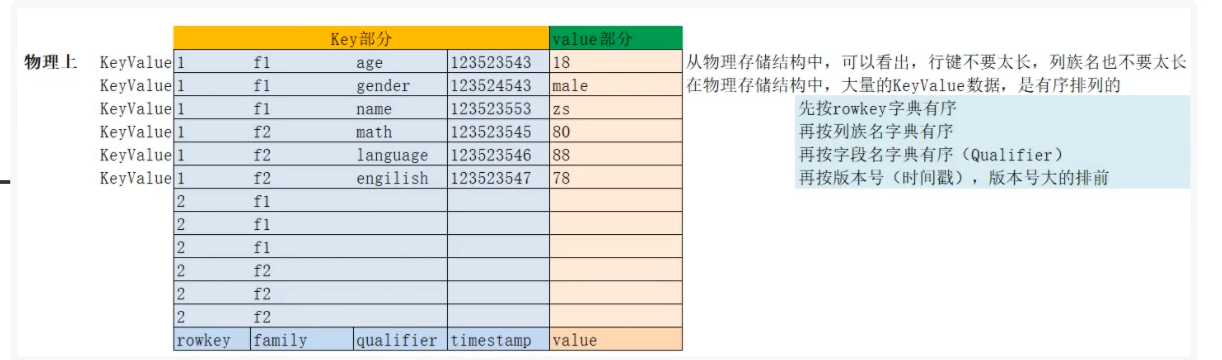
HBase存储物理结构
每个Region的不同列簇存在不同的StoreFile中
HBase架构


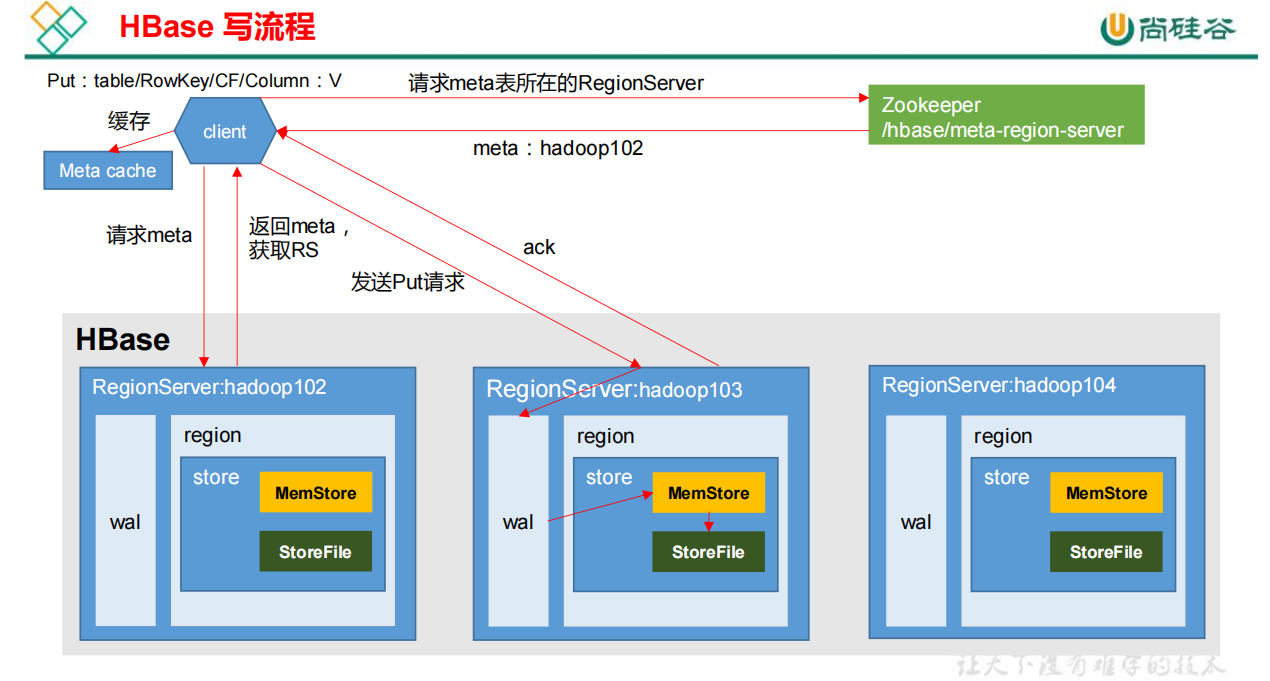
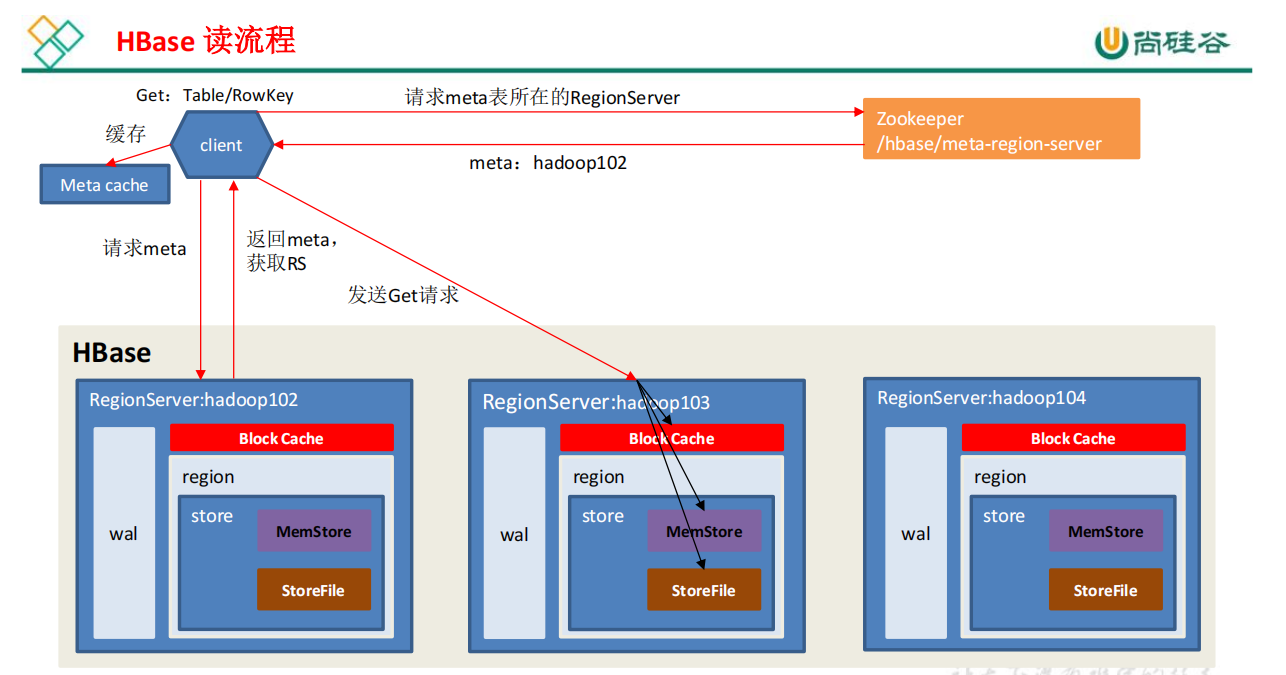
HBase读写流程


StoreFIle Compaction & Region Split
这两部其实多多少少都是因为写入数据引起的
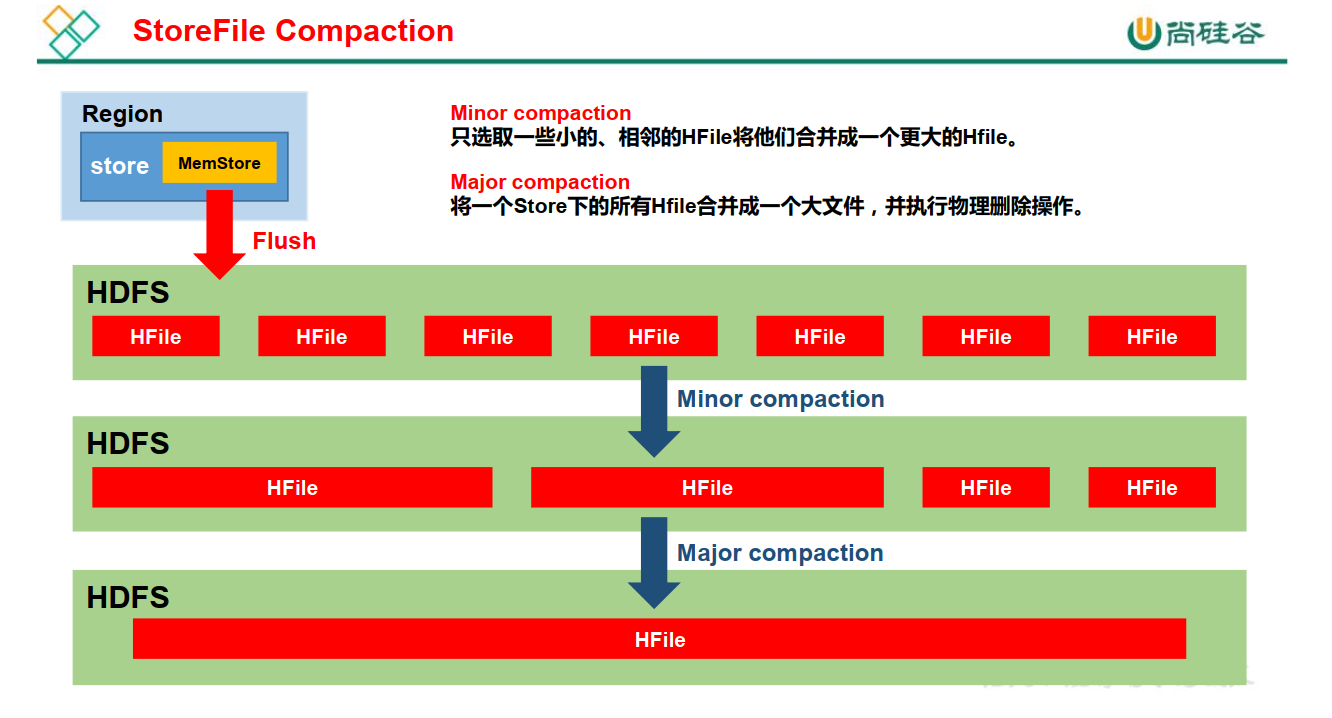
StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。
为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。
Minor Compaction 会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期 和删除的数据
Region Split

HBase底层--LSM树
哈希存储引擎、B树存储引擎、LSM树存储引擎详解_一个写湿的程序猿的博客-CSDN博客_哈希存储引擎
HBase在大规模数据下为什么依旧稳定
总的来说就是通过不断分解来缩小查询的范围
面对百亿数据,HBase为什么查询速度依然非常快?_努力成为咸鱼的博客-CSDN博客_hbase查询性能
RowKey设计问题
原则一:长度原则
我们可以看到因为有不同的列簇和不同的时间戳 导致同一个RowKey也会有很多条数据 若RowKey本身长度过长 存储的key键的冗余程度就会增加
原则二:rowkey 唯一原则
原则三:散列原则
散列原则是为了避免引起热点问题 也就是数据倾斜问题
而引起数据倾斜的一部分原因就是因为RowKey是有序的 会导致热门数据堆积到一个RegionServer之中
所以就是通过打散RowKey来解决这个问题
=================================================================
知识点补充:在HBase中检索数据时使用到RowKey的一共有三种方式:
get:通过指定单个RowKey来获取对应的唯一一条记录;
like:通过RowKey的range来进行匹配;
scan:通过设置startRow和stopRow参数来进行范围匹配(注意:如果不设置就是全表扫描)
方法一:反转
4.2.1、反转(Reversing)
第一种咱们要分析的方法是反转,顾名思义它就是把固定长度或者数字格式的 rowkey进行反转,反转分为一般数据反转和时间戳反转,其中以时间戳反转较常见。
适用场景:
比如咱们初步设计出的RowKey在数据分布上不均匀,但RowKey尾部的数据却呈现出了良好的随机性(注意:随机性强代表经常改变,没意义,但分布较好),此时,可以考虑将RowKey的信息翻转,或者直接将尾部的bytes提前到RowKey的开头。反转可以有效的使RowKey随机分布,但是反转后有序性肯定就得不到保障了,因此它牺牲了RowKey的有序性。
缺点:
利于Get操作,但不利于Scan操作,因为数据在原RowKey上的自然顺序已经被打乱。
举例:
比如咱们通常会有需要快速获取数据的最近版本的数据处理需求,这时候就需要把时间戳作为RowKey来查询了,但是时间戳正常情况下是这样的:
1588610367373
1588610367396
前面这部分是相同的,在查询的时候就容易造成热点现象,因此需要使用时间戳反转的方式来处理。实际生产中可以用 Long.Max_Value - timestamp 追加到 key 的末尾,比如 [key][reverse_timestamp], [key] 的最新值可以通过 scan [key]获得[key]的第一条记录,因为HBase中RowKey是有序的,所以第一条记录是最后录入的数据。
常见的场景,比如需要保存一个用户的操作记录,就可以按照操作时间倒序排序,在设计rowkey的时候,可以这样设计 [反转后的userId][Long.Max_Value - timestamp],
在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow 是 [反转后的userId][000000000000],stopRow 是 [反转后的userId][Long.Max_Value - timestamp]。如果需要查询某段时间的操作记录,startRow 是[反转后的userId[Long.Max_Value - 起始时间], stopRow 是[反转后的userId][Long.Max_Value - 结束时间]。
方法二:加盐
首先我们需要明确 RowKey是根据字典序进行排序的 所以给原来RowKey的末尾加随机数并不能有效的打散数据. 要加也是将随机数作为前缀
但是通过加随机数的方式来打散数据 会导致将来读取数据的时候 需要全表扫描(因为不知道作为前缀的随机数到底是几) 不利于查找数据
方法三:哈希
通过hash算法来弥补加盐法的随机性 使我们能够还原出本身的RowKey 方便查找
















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









