







从HDFS的存储说起
HDFS存储过程
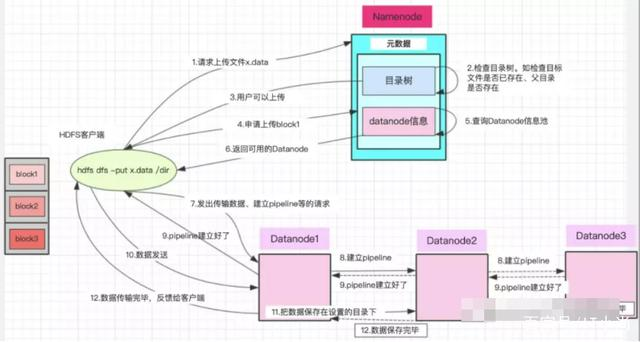
存储涉及到分块(Block)和分片(Split)
Blcok是物理概念,是在HDFS上存储的基本单位,调用的是getSplits()方法
Split是逻辑概念,是MR任务运行的分区数,两者默认情况是相同的
计算spliteSize分片的尺寸:
首先取blockSize与maxSize之间的最小值即blockSize
然后取blockSize与minSize之间的最大值,即为blockSize=128M,所以分片尺寸默认为128M
无法分片的(snappy等格式)将直接生成一个Block,这也意味着以这些无法分片数据作为输入数据时,并行度只能为1
深层次原因是因为分布式系统无法找出该文件的不同起始位置(因为无法分片)
/**
* Generate the list of files and make them into FileSplits.
* @param job the job context
* @throws IOException
*/
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
/*
* 1、minSize默认最小值为1
* maxSize默认最大值为9,223,372,036,854,775,807
* */
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
/*
* 2、获取所有需要处理的文件
* */
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
/*
* 3、获取文件的大小
* */
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
/*
* 4、获取文件的block,比如一个500M的文件,默认一个Block为128M,500M的文件会分布在4个DataNode节点上进行存储
* */
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
/*
* 5、Hadoop如不特殊指定,默认用的HDFS文件系统,只会走上面if分支
* */
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
/*
* 6、获取Block块的大小,默认为128M
* */
long blockSize = file.getBlockSize();
/*
* 7、计算spliteSize分片的尺寸,首先取blockSize与maxSize之间的最小值即blockSize,
* 然后取blockSize与minSize之间的最大值,即为blockSize=128M,所以分片尺寸默认为128M
* */
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
/*
* 8、计算分片file文件可以在逻辑上划分为多少个数据切片,并把切片信息加入到List集合中
* */
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
/*
* 9、如果文件最后一个切片不满128M,单独切分到一个数据切片中
* */
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
/*
* 10、如果文件不可以切分,比如压缩文件,会创建一个数据切片
* */
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length file
/*
* 11、如果为空文件,创建一个空的数据切片
* */
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
大数据中常用的数据格式
Parquet
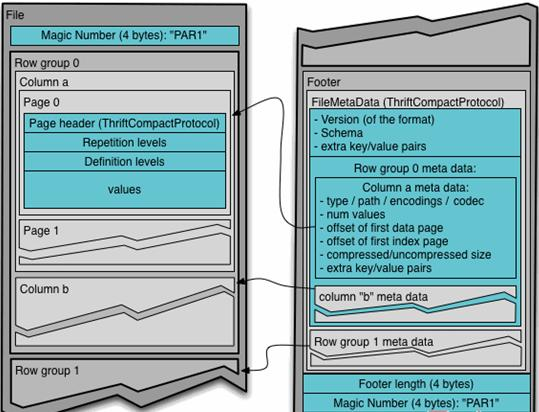
Parquet存储结构
Parquet在每一个RowGroup中 把一列数据存储完再存储另一列 所以可以实现只读取某一列数据
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
(1)行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
(2)列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
(3)页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式。
Parquet使用要点
若已在Hive创建了一张Parquet格式的表,读取其它格式的数据会报错
正确做法:(其实相当于执行了一次MR)
1)创建一个临时表
CREATE TABLE raw (id INT,name STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
2)将数据导入到临时表中
LOAD DATA LOCAL INPATH '/var/lib/hadoop-hdfs/test.gz' INTO TABLE raw;
3)将该临时表的数据导入到Parquet表
SET hive.exec.compress.output=true;
INSERT OVERWRITE TABLE raw_sequence SELECT * FROM raw;
ORC+Snappy
LZO同为列式存储格式,其存储效率比Parquet高,但其默认的压缩格式不支持切片
如果输入多个用不可分割的压缩算法(Snappy,GZip)的大文件:
- 因为文件解压后占用空间过大 Spill到硬盘中 时间猛增
- 空间过大导致OOM
如果无法更改存储格式 如何解决该问题?
方法一:
下次向HDFS存储时,将repartition()增大 增加文件数的同时减少每个文件数据量
方法二:
首先明确Spark的内存划分:
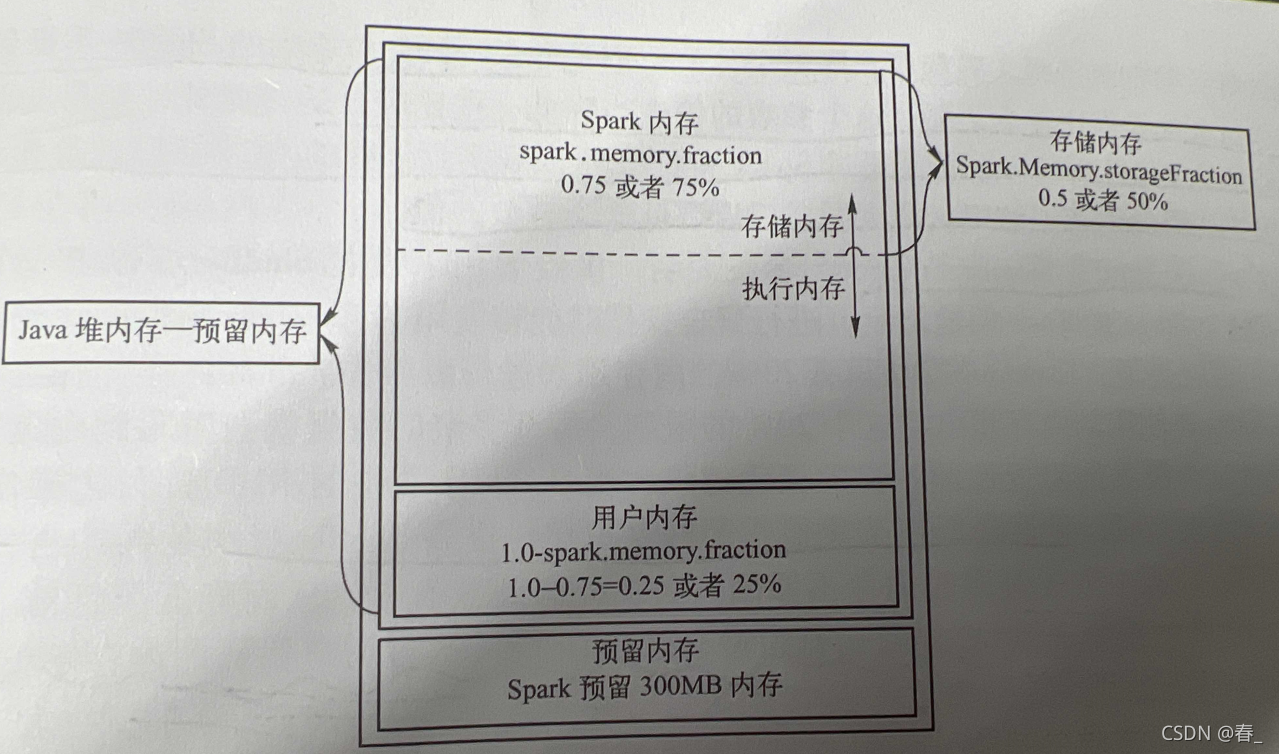
JVM内存分为:Spark内存(75%)+用户内存(25%)+预留内存(300M)
 假设在submit任务时提交的参数executor.memeory =10G
假设在submit任务时提交的参数executor.memeory =10G
Spark存储内存=Spark内存storageFraction = (100-75)G * 0.5 = 3.75G
Spark执行内存=Spark内存storageFraction = (100-75)G * 0.5 = 3.75G
在本例中读取的数据过大撑爆了堆内存 可以调大spark.memory.storageFraction以此调大存储内存
如果遇到需要大量Shuffle撑爆了内存 可以调小spark.memory.storageFraction以此来变相调大执行内存
https://blog.csdn.net/weixin_43736084/article/details/121541393
参考:https://blog.csdn.net/weixin_43736084/article/details/121419435?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-121419435-blog-113058562.pc_relevant_aa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-121419435-blog-113058562.pc_relevant_aa&utm_relevant_index=5














 7353
7353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









