






目录
Flink与Spark的根本不同
Spark作为批处理引擎 在执行任务之前 数据已经存储在分布式集群当中了 Driver端将应用程序构成DAG之后将任务分发到离数据最近的节点 所以可以说Spark是数据等任务
Flink数据是在任务提交之后才源源不断的流来 需要将数据传输到相应的TaskManager中执行操作所以可以说Flink是任务等数据
Flink 是流式计算框架。它的程序结构,其实就是定义了一连串的处理操作,每一个数据
输入之后都会依次调用每一步计算。在 Flink 代码中,我们定义的每一个处理转换操作都叫作
“算子”(Operator),所以我们的程序可以看作是一串算子构成的管道,数据则像水流一样有序
地流过
运行架构
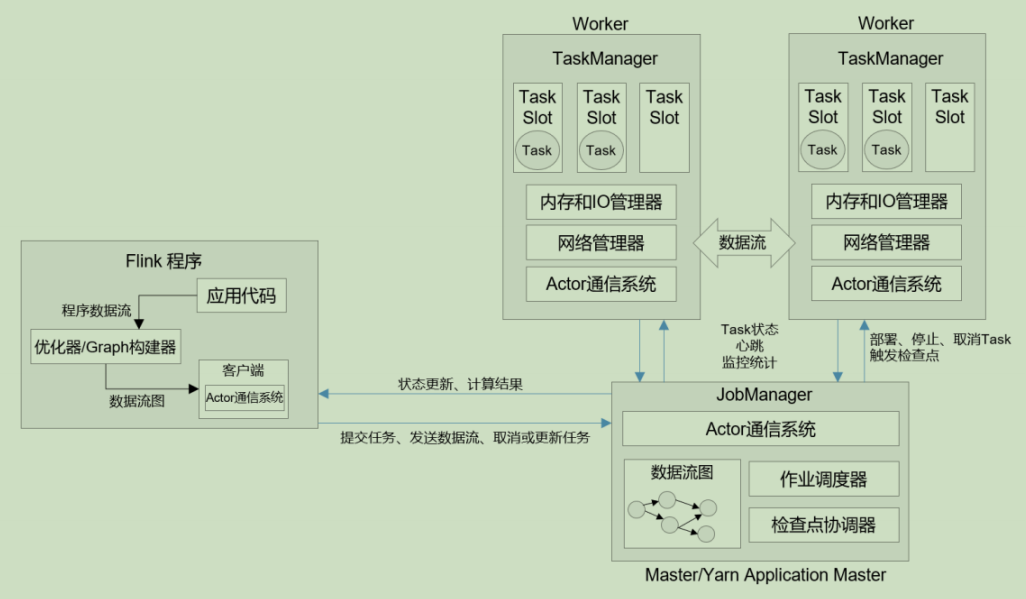
部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。 Flink 为各
种场景提供了不同的部署模式,主要有以下三种:
⚫ 会话模式(Session Mode)
⚫ 单作业模式(Per-Job Mode)
⚫ 应用模式(Application Mode)
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的 main 方法到底
在哪里执行——客户端(Client)还是 JobManager。
会话模式
我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业,如图所示。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源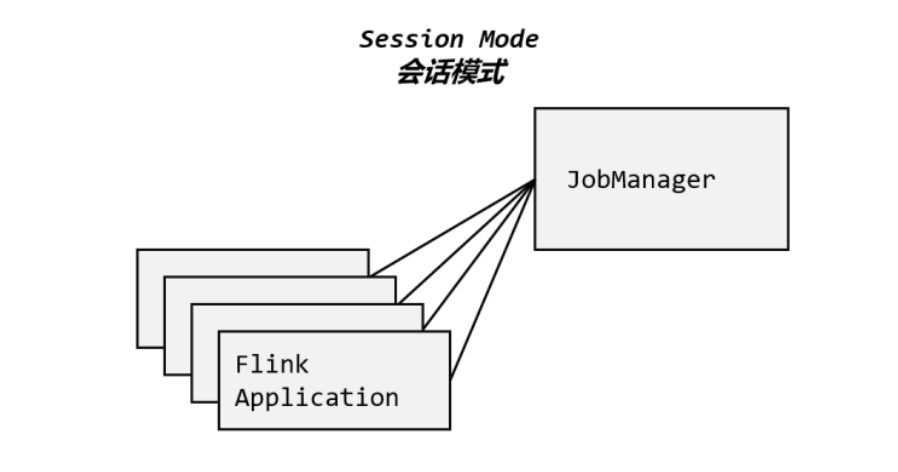
这样的好处很明显,我们只需要一个集群,就像一个大箱子,所有的作业提交之后都塞进去;
集群的生命周期是超越于作业之上的,铁打的营盘流水的兵,作业结束了就释放资源,集群依然正常运行。
当然缺点也是显而易见的:因为资源是共享的,所以资源不够了,提交新的作业就会失败。另外,同一个 TaskManager 上可能运行了很多作业,如果其中一个发生故障导致 TaskManager 宕机,那么所有作业都会受到影响。
单作业模式
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。需要借助Yarn等
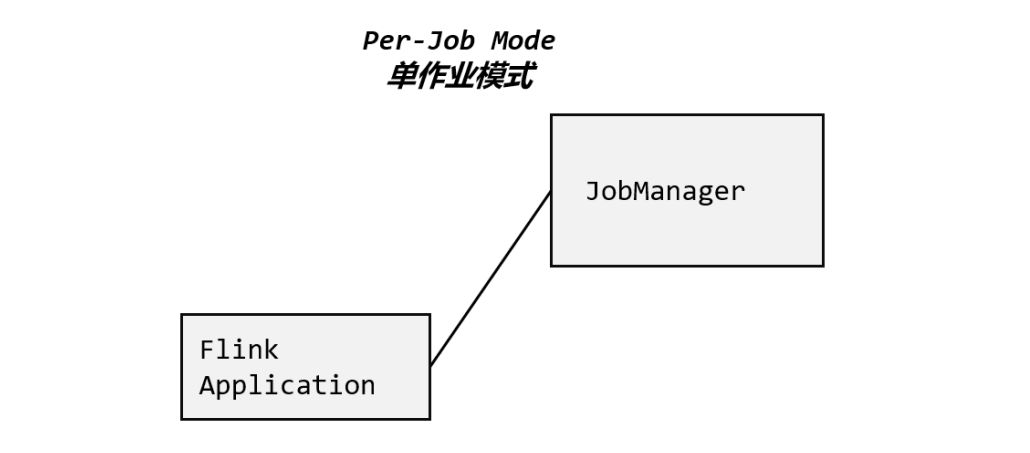
单作业模式也很好理解,就是严格的一对一,集群只为这个作业而生。同样由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。
应用模式
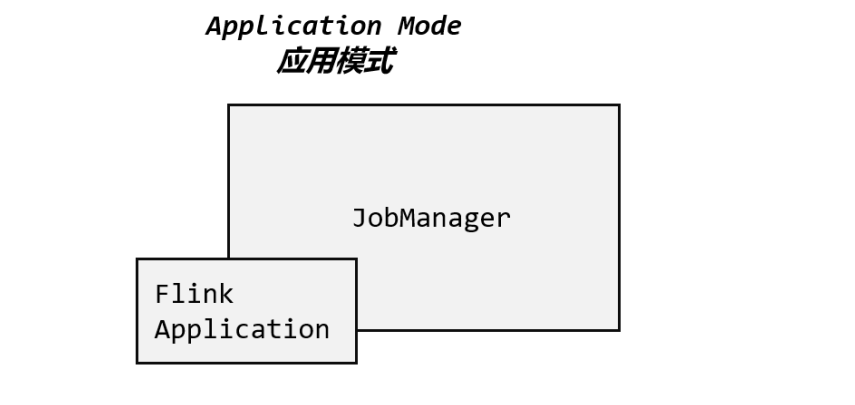
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给 JobManager的。
但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;
加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到 JobManger 上运行(类似Spark的Yarn-Cluster模式)。
而这也就代表着,我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所谓的应用模式
三种模式对比

Flink的任务生成过程
之前提到 Flink的计算过程就是运算等数据 那么我们该如何确定需要几个运算任务以及这些任务之间的关系呢? ==> 通过图
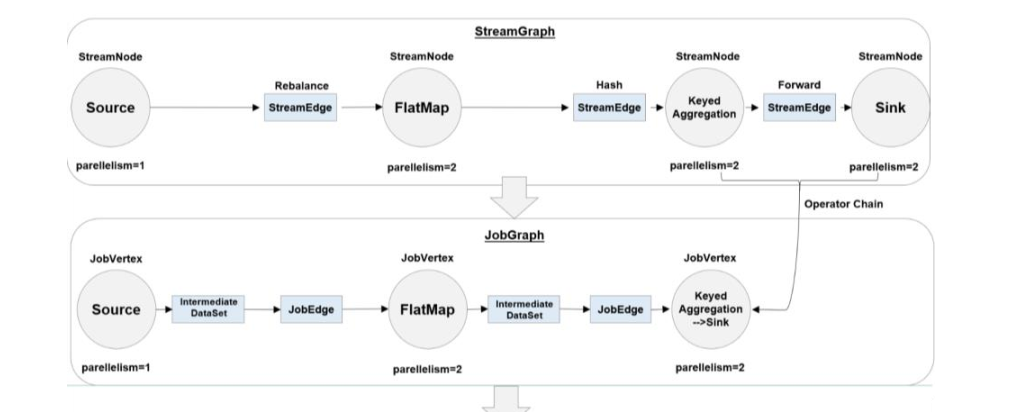
STEP1:客户端解析任务的DataStream算子 完全按照DS的顺序和个数生成逻辑流图
STEP2:根据算子的执行顺序 若两算子相邻且平行度一致 则合并成一个算子链
减少了算子个数 生成了作业图 并将其送至JobManager
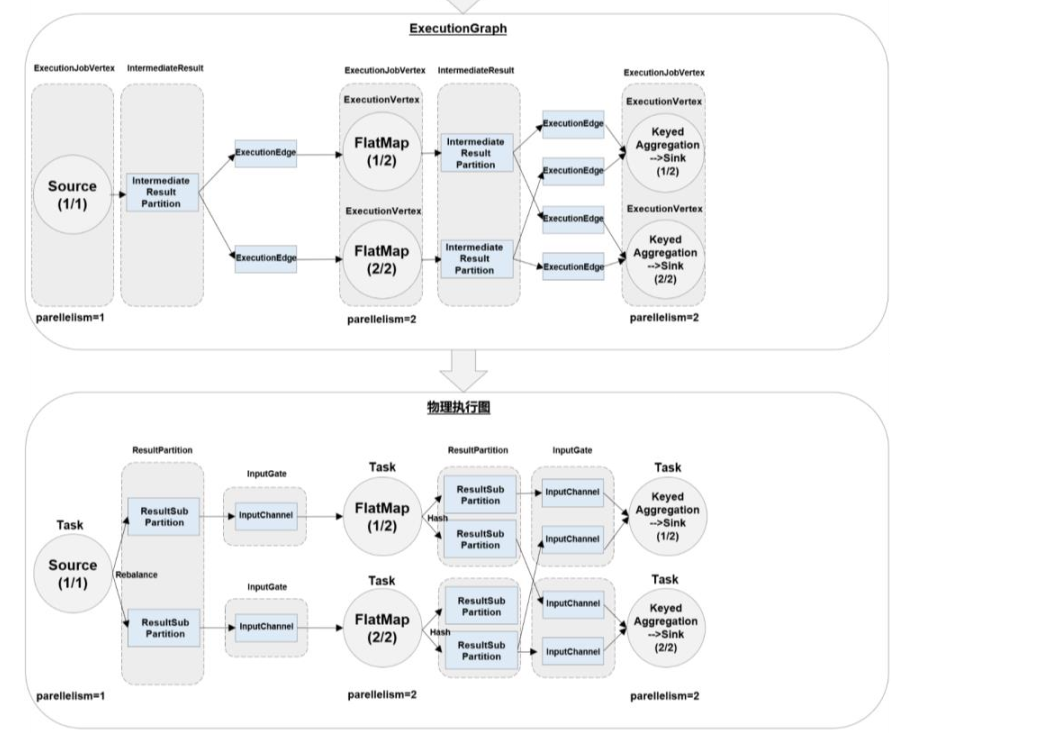
STEP3:JobManager将作业图解析 根据并行度拆分算子(此时已经知道需要多少个线程)
生成执行图 并发往各个TaskManager
STEP4:各TaskManager根据执行图部署 最终执行后会生成一个物理意义(实际发生)的图
即为物理图
通过上面的流程可以发现 执行图是最关键的 它告诉TaskManager需要几个线程以及这几个线程需要进行什么算子操作
任务和任务槽
通过执行图我们知道需要的线程数 可能会下意识的认为线程数=需要的任务槽数
其实是不对的 因为:
只要属于同一个作业,那么对于不同任务节点的并行子任务,就可以放到同一个 slot 上执行。
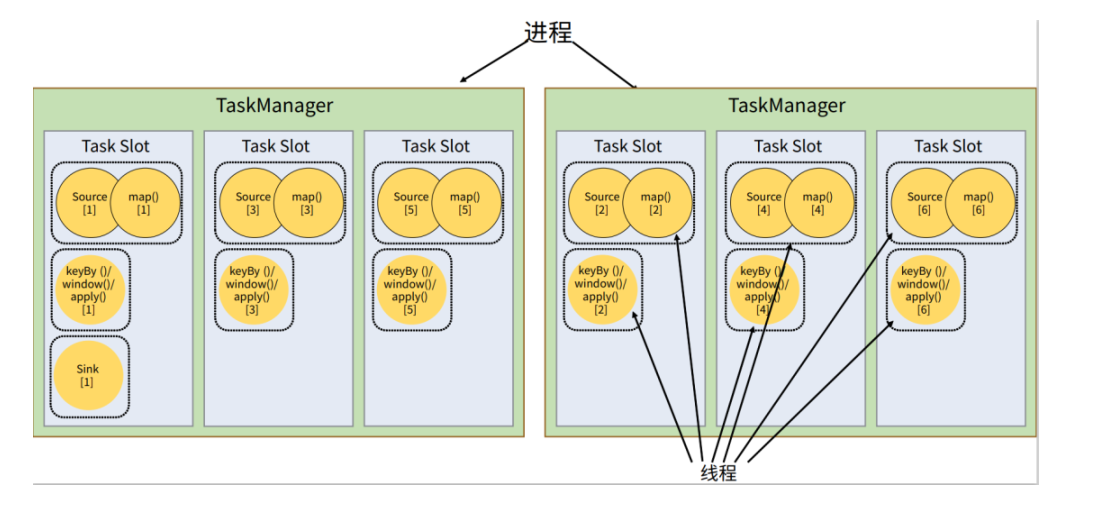
对于第一个任务节点 source→map,它的 6 个并行子任务必须分到不同的 slot 上(如果在同一slot 就没法数据并行了)
而第二个任务节点 keyBy/window/apply 的并行子任务却可以和第一个任务节点共享 slot
每个任务节点的并行子任务一字排开,占据不同的 slot;而不同的任务节点的子任务可以共享 slot。一个 slot 中,可以将程序处理的所有任务都放在这里执行,我们把它叫作保存了整个作业的运行管道
背压问题
我们追求的是任务的隔离和并行 为何现在又要共享slot?

时间语义、水位线
时间语义
Flink本身是分布式计算引擎 那么就逃不开分布式系统的限制 在分布式系统中 各个节点各自为政互不干扰 时间上也很难统一
若想通过JobManager来同步时间的话 因为网络的延迟会导致各节点时间不一致
另一个问题就是流数据所带来的的:数据在不同节点是不停流动的 同样会有延迟
对于一个8点59分产生的数据 若其9点1分才到达节点 其到底是归属于哪一个时间窗口?
基于以上的考虑 Flink提供了三种时间语义以及水位线的功能
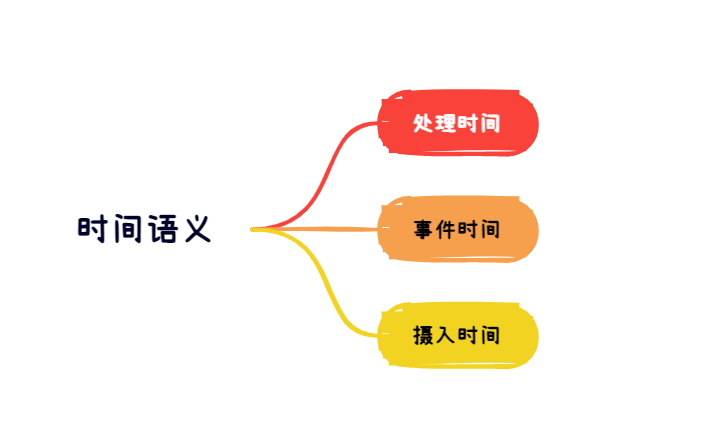
处理时间:数据计算时的系统时间
事件时间:数据产生时的系统时间
摄入时间:source读取数据时的系统时间
处理时间抛弃那些因为网络延迟而没有按时到达的数据 虽然实时性最好 但是准确率不佳
事件时间在极端条件下可以保证所有数据被计算到 所以准确率最高 但是实时性较差
摄入时间取了两者的中间 能较好地平衡准确率和实时性
水位线
为什么需要水位线?


水位线在有序流和无序流中的不同
在有序流中 因为数据是一条接着一条有序而来的 提取每个数据事件语义作为水位线 在准确度上来说没有问题 但是提取的频率会很高 甚至有时候提取并不会促进水位线的前进 所以一般都是按周期取
但是这种直接提取事件语义作为水位线的做法在无序流中并不适用 因为9秒产生的数据可能晚于7秒产生的数据到达节点.可能产生水位线下降的情况 解决办法也很简单 判断当前的事件是否大于水位线 若大于再更新
但是这样会导致数据丢失(比如上文中7秒产生的数据就不能进入0~9 这个时间窗口) 所以我们将事件时间减去一定的时间 作为时间戳 (比如9秒产生的数据 减去3秒 生成的时间戳是6秒) 来生成水位线 这样一来 只有等12秒产生的数据到来(减去3秒后为9秒) 水位线为9秒 这样能一定程度上的保证数据不丢失

这样一来 不论是有序流还是无序流 水位线都能一定程度上的保证之前的数据已经到达
CheckPoint容错机制

检查点其实就是对各算子状态做快照的节点
这里和Spark的Checkpoint也有很大的区别:
原因就在于 Spark在当前Job完成后再进行保存Checkpoint这一操作 又因为离线处理时 数据是已知的 job完成一定意味着当前数据全部处理完成
但是Flink因为是实时处理的 在t1时刻执行checkpoint操作 并不能保证t1之前的数据全部处理完毕(乱序+网络延迟影响)
何时保存检查点?

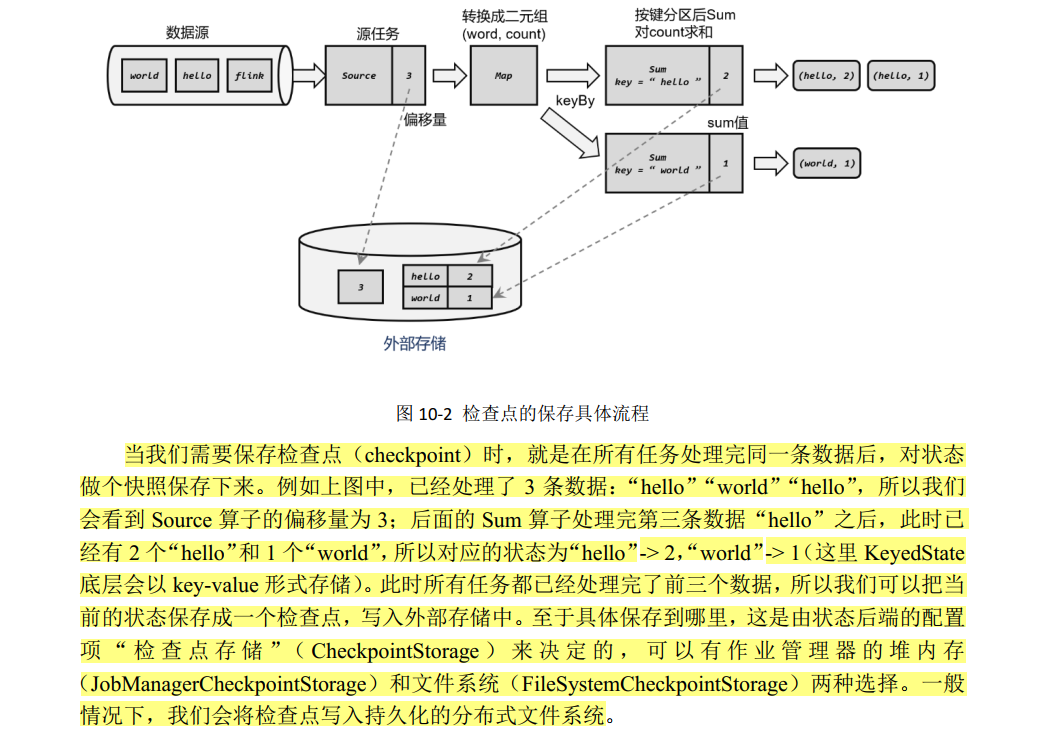
检查点算法
我们如何让分布式系统知道相同批次数据被处理完成 ==> barrier
最开始的时候这里理解出现了偏差 认为barrier代表的是处理到“同一个数据”,而事实并非如此。
假设我们用并行度为2的source读取kafka中同一topic下不同partition的数据(每个partition的数据各不相同 它们汇总后才构成一个完整的topic数据),因为读取的数据源内的数据并不相同 我们根本就等不到"相同数据"的出现,即便出现了"相同数据" 那也只是数值相同但意义(时间上)并不相同.
所以才强调"同一批次".其实source向数据流中插入barrier是受JobManager控制的 "并行的source受到一个JobManager控制" 这其实也符合检查点算法"当上游任务向下游多个并行任务发送barrier时需要广播"这一原则
而为什么能通过检查点实现Exactly-Once 是因为一个数据只会在一个批次当中(这就需要进行barrier对齐 若不进行对齐实现的是AtLeastOnce) 而每个批次状态都有CheckPoint来保存 也就保证了同一个数据只会被处理一次


端到端精准一次








在电商实时数仓中是如何实现Exactly-Once的?
消费kafka:将kafka自动提交offset关闭并且与flink的CheckPoint绑定。
Flink内部:启用状态后端 模式设为Exactly-Once
生产Kafka:FlinkKafkaProducer.Semantic.EXACTLY_ONCE设置kafka为精确一次
Flink-Exactly-once一致性系列实践1_瘦瘦的肥羊的博客-CSDN博客
















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









