






Kafka学习笔记
安装
省略
linux下面的安装就简单的尼玛离谱
zooker.config改一下
开放一下kafka的端口就ok
Kafka运作的方法论
首先要明白什么是消息队列。
信息的传递一定有发送方和接收方
发送方和接收方如果同步接受消息会带来很多不便,比如,发送方和接收方不一定同时有空,如果能有一个中间的人,存也在这个人里面存,出也是这个人出,那就方便很多了。消息中间件应运而生。
消息队列有很多模式
点对点模式

点对点的特点:
- 一个producer产生的消息只被一个consumer消费
- 消费者无法感知Queue中是否有消息(所以需要增加额外的线程)
发布订阅模式

3. 一个producer的订阅者可以接受这个producer的消息
4. 但是传递消息的速度不确定,因为不同机器处理消息的速度,能力不同
Kafka模型架构

- producer:消息的生产者
- kafka cluster
- Broker:Broker是Kafka的实例,每一个服务器上有一个或者多个Kafka实例,我们姑且认为一台broker对应一台服务器。每一个kafka集群内的broker都有一个不重复的编号。
- Topic:消息主题,可以理解为消息的分类,Kafka的数据保存在topic中,每一个broker都可以创建多个topic
- Partition:Topic的分区,每一个topic可以有多个分区,分区的作用是负载,提高Kafka的吞吐量。同在一个topic中的不同分区数据不相同。可以理解为这个时数据库分表。
- Replication:每一个分区都有一个或者多个副本。副本的作用是主分区故障的时候,还能有机子顶上。这么分析,foller和leaer的关系就显而易见了。
对应关系是
kafka cluster 包含 多个broker ,broker包含多个Topic,Topic包含多个partition.其中,每一个分区对多个Replication,存放在不同机子中,实现高可用。副本的数量绝对不能大于broker的数量,也就是说一个broke中不可能存在两个包含相同内容的Replicaition - Message:每一条发送的消息
- Consumer:消费者,就是消息的发送方,用于消费信息,是消息的出口。
- Consumer Group:可以将多个消费者组成一个消费者组。同一个消费者组的消费者可以消费同一个topic不同分区的信息。
Kafka的工作流程
生产者发送消息 to Kafka Cluster
- 生产者获得集群中learder的信息
- 生产者发送信息给Leader
- leader写信息在本地
- leader发送信息给follower
- follower写完,发送ack给leader
- leader收到所有follower的ack发送消息给producer
采用分区的目的是为了,方便扩展,提高并发,那么不同分区存放的是不同的内容,服务器是如何将不同的请求分发到不同的partition中去的呢?
7. 人工制定partition
8. 数据如果有key,用hash的手段去得到一个partition
9. 轮询出一个patition。
要知道,在消息队列中,保证数据不丢失是一件很重要的事情。它是通过一个叫做ack的参数来保证的。
0表示producer在往集群中发送数据的时候不需要等到集群返回。
1表示就是leader级别的停等协议,保证leader接收到应答信息,就可以发送下一条。
all 表示所有的leader follower接收到消息,才能继续发送下一条数据。
Kafka是如何保存数据的
像Kafka需要高并发额组件,它会单独开辟一块连续的磁盘空间,顺序写入数据。
Partition结构
一个Partition包含多个Segement
一个Segment包含
- xx.index索引文件
- xx.loag信息存储文件
- xx.timeindex索引文件
存储策略
无论信息是否被消费,Kafka都会保存所有信息。 - 基于时间,7天删除
消费数据
消息存储在log文件后,消费者就可以进行消费了。首先Kafka采用的是 点对点的模式(???我记得不是发布订阅吗,这个待斟酌)其次,消费者也是主动去kafka集群中找leader拉去信息。每一个消费者都有一个组id,同一个消费者组的可以消费同一个topic下不同分区的数据。简单来说,如果A B同属与一个消费者组,对于Topic test这个主题下的一个patition并不能都读取,只能用一个读。

所以会出现某一个消费者消费多个partition的情况,一般消费者组的consumer数量和partion数量一一对应。不然那一个消费者处理两个partition会可能效率更不上。多个消费者反正也不能两个消费者消费同一个partition
Kafka实践操作
- 简单介绍一下server.properties
- broker.id 每一个broker在集群中的唯一表示,要求是正数。当broker.id没有发生变化,则不会影响consumers的消息情况。
- log.dirs kafka数据存放的地址
- port broker server的服务端口
- message.max.byte,消息体的最大大小,单位是字节
- num.network.threads,broker能处理消息的最大线程数,一般为cpu核数
- num.io.threads brokers处理磁盘IO的线程数
- hostname broker的主机地址。如果设置了,就会绑定到这个低智商,若是没有,就会绑定到所有接口上,并将其中之一发送到
- zookeeper.connect zookeeper集群的地址,可以是多个
- zookeeper.session.timeout.ms zookeeper最大的超时时间
- zookeeper.connection.timeouout.ms
- listener:监听端口
Kafka对于很多节点的功能都是通过zookeeper来完成的
- 实操命令
- 服务器启动
zkServer.sh start
创建主题
[root@k8s-master1 kafka_2.13-3.0.0]# bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic heima --partitions 2 --replication-factor 1
kafka-topics.sh这个大类中
用–bootstrap-server localhost:9092来代替 --zookeeper localhost:2081
–creae是定义动作
–topic后面跟了一些信息
名称
parition:设置分区数量
replication-factor,定义副本数量
- 启动服务器
bin/kafka-server-start.sh config/server.properties
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ice
启动客户端,绑定主题
这是生产者,生产信息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic ice
以一个简单的Java例子来讲解一下kafka
首先要在Maven中配置
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
来一个消费者实例
public class ProducerFastStart {
private static final String brokerList = "192.168.236.137:9092";
private static final String topic = "ice";
public static void main(String[] args) {
Properties properties = new Properties();
// properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.RETRIES_CONFIG,10);
//设置值序列化器
// properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
//设置集群地址
// properties.put("bootstrap.servers",brokerList);
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
//record封装了对象
ProducerRecord<String,String> record = new ProducerRecord<>(topic,"kafka-demo","123");
try {
Future<RecordMetadata> send = producer.send(record);
RecordMetadata recordMetadata = send.get();
System.out.println("topic = "+recordMetadata.topic());
System.out.println("partition = "+recordMetadata.partition());
System.out.println("offset = " + recordMetadata.offset());
}catch (Exception e){
e.printStackTrace();
}
producer.close();
}
}
首先要指定brokerlist的ip与端口,你要告诉这个生产者去哪儿放消息。指定一个topic,告诉去去哪个主题下放信息。
整一个信息在Java中,是以Message的形式存在,这个Message是以properties为配置工具配置的。
properties.put(ProducerConfig.RETRIES_CONFIG,10);
配置一下如果发送失败,总计重传几次
在使用java在kafka中传送信息的时候,一般都要跟上key和value。
而且 key和value都需要序列化。
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);
在这里绑定了properties中的一些信息,实现了Kafka的一个配置
ProducerRecord<String,String> record = new ProducerRecord<>(topic,“kafka-demo”,“123”);
在这里设置了信息,用key value键值对的形式产生。
consumer的java实现
private static final String brokerList = "192.168.236.135:9092";
private static final String topic = "ice";
private static final String groupId = "group.demo";
public static void main(String[] args) {
Properties properties = new Properties();
// properties.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,brokerList);
properties.put("bootstrap.servers",brokerList);
properties.put("group.id",groupId);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton(topic));
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(5000));
for (ConsumerRecord<String,String> record:records){
System.out.println(record.value());
}
}
}
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
在这里,之前的producer是要序列化,那么对应取出来的信息我们要反序列化,这样才能获取到信息。
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
在这里,在这里value也是也是需要反序列化的
properties.put("bootstrap.servers",brokerList);
properties.put("group.id",groupId);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
不同的是,要设置消费者的组才行。
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singleton(topic));
然后需要让consumer订阅一下topic主题
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(5000));
for (ConsumerRecord<String,String> record:records){
System.out.println(record.value());
}
}
设置监听的时间,并且解析监听得到的信息。
浅分析一下producer的写入过程
- 客户端写程序。通过KafkaProducer这个类来连接broker,会通过properties制定broker的地址,并且制定kv的序列化类型,topic,partition等信息。
- 通过ProducerRecord来封装要发送的消息。
- KafkaProducer装载ProducerRecord,并且通过send()函数发送。在这个时候会一个序列化器进入一个分区器。
- 序列化器,序列化信息,分区器,来决定这个信息被放入分区器中的那个分区中。
注意,分区器和序列化器都是可以由我们自己重写的。 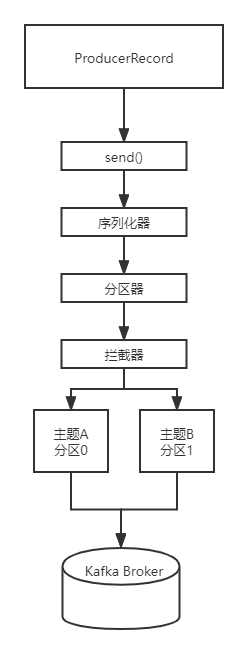
最后还有一个拦截器,拦截器的作用就像AOP的作用一样,相当于一个增强的功能。
浅分析一下consumer的读取过程
首先来讲解一下位移的概念。首先他和在分区中的位移不是一会儿是,虽然他们的英文都是Offset。消费的位移是指,这个位移记录了Consumer要消费的下一条消息的位移。是下一条消息的位移,不是最新消费消息的位移。
比如,一个分区中有10条信息,位移分别是0-9.某个Consumer应用已经消费了5条信息,那么说明这个Consumer消费了位移为0-4的五条消息,此时Consumer的位移是5,指向了下一条消息的位移。
并且,Consumer需要向Kafka汇报自己的位移数据,这个汇报过程被称为提交位移(Committing Offsets)。因为Consumer能够同事消费讴歌分区的数据,所以位移的提交是在分区的粒度上进行的。Consumer需要分配给他每个分区,都进行位移提交。
这个位移的存在是为了保障你不会消费之前已经消费了的数据。而且Kafka对于位移的提交容忍能力非常强,可以分为自动提交和手动提交。自动提交,就是Kafka默默地为你提交位移,作为用户你完全不必操心这些事,而手动提交是指自己提交位移,Kafka Consumer不用管。
自动提交的Kafka使用的大概5s就自动提交一次位移。
但是自动提交会到来一个重复消费的问题,核心问题在于
开启自动提交
props.put("enable.auto.commit","true");
props.put(""auto.commit.interval.ms,"2000")
总体来说还是很简单的
自动提交,Kafka会保证在调用poll方法时,提交上次poll返回的所有消息。从顺序上说,poll方法的逻辑是先提交上一批消息的位移,再处理下一批消息。但是如果发生了Rebalance就会变得不同,具体怎么不同到时候再说。
手动提交很灵活,但是commitSync()调用的时候Consumer会处于一个阻塞状态,知道远端的Broker返回提交结果,这个状态才会结束。就是因为非资源原因导致的系统阻塞降低了效率。
这就来了异步提交。
但是我的项目里用的是同步提交嘛,接受传递来的数据,然后进行切割预处理,然后进行使用。
异步处理,会导致信息丢失,因为这个时候重试是没有意义的,你重试的时候,这个有效信息位都不知道去哪儿了。
最好的方法其实是两个叠加
Kafka知识点
-
Kafka是什么
- 一个分布式 发布订阅系统
- 是一个流式数据的处理系统
-
Kafka的优势
- 并发性好
- 围绕着Kafka的生态比较好
-
Kafka的多副本机制提高容灾能力,并且因为有多个partition存在,,因此有比较好的并发能力
-
Zookeeper在Kafka中的作用
- 提供元数据管理等工作
- 注册Broker这种
-
Kafka如何保证消息消费的顺序
- 消息一般都放在partition的末尾
- 但是只保证在一个partition中是有序的,如果你一个topic只有一个partition,那么当然你无敌,但是这个违反了Kafka设计的初衷
-
Kafka如何保证消息不被重复利用
-
重复被利用的原因有 offset没有被利用起来
-
触发了rebalance导致offset被改变了
-
关闭offset自动提交手动提交
-
幂等校验
-
-
为什么要使用消息队列
- 异步通信。不要球接收方和发送方同时空闲
- 解耦
- 缓冲和削峰 当一下子有大量数据冲击的时候也不会有太大的问题。
- 冗余 一个生产者生产的消息可以被多个订阅者订阅到
-
Kafka中的broker topice partition分别是什么
- 在一个Kafka集群中有多个broker。可以暂且认为这个broker就是一个Kafka的实例,对应一台服务机器。每一个Kafka集群中的broker都有一个唯一的编号。
- broker中有很多个topice。每一个topic可以有很多个分区,分区的作用是提高Kafka的吞吐量。可以理解为这个是数据库表的横向切分。
- Replication。这个是Kafka的容灾机制当主节点出问题之后,子节点可以顶上。
- Consumer Group 消费者组。同一个组的消费者,只能消费一个topic中的不同Partition的数据。
- Consumer:消费者,就是消息的发送方。
-
Kafka的工作流程
- 生产者生产信息到broker
- leader先拿到消息,然后更写入follower
- follower写完发送ack给leader
- leader收到消息之后发送ack给producer
- 消费者pull数据
-
选择Partition是可以通过认为定义,或者Hash,轮盘这种算法选择出的。
-
Kafka是如何保证数据不丢失的
分为三者来说- 消费者通过offset commmit来保证
- broker通过partition机制来保证
- Kafka通过ack机制。就是发送一个消息会要有一个确认反馈的机制保证消息能被接受到。
-
消息队列有两种模式
- 点对点。一个Producer生产的消息只有只有一个Consumer可以消费
- 发布订阅,只要订阅了就都可以消费。
-
Kafka的Rebalnce机制
首先要明确,为什么要Rebalnce,我们很清楚一个broker中有很多个topic,一个topic中很有很分区。而且一个消费者组的消费者,一个消费者只能消费一个分区中的信息。这就导致了一个问题,如何分配分区给消费者,才能达到消费信息速度最大化呢。这个是需要让一个优化器决定的,所以在一个消费者组有成员加入,有成员离开的时候就可能会出发rebalance机制。 -
Kafka的offset机制
首先一个producer往一个partition里面写信息是追加写。然后就算有消费者消费了这个信息,这个信息也是不会删除的,所以这个就是它能支持给多个consumer访问的原因。
在客户端通过offset来保障客户端没有重复读取信息。客户端消费一个信息,自己就记录offset移动一下,每隔一段时间,客户端就会提交一下自身的offset。但是在其中如果有一个客户端在发送自身的offset之前,服务器宕机了,或者触发了rebalance就可能会造成重复读取,这个时候就要通过幂等校验balabala的去测试。 -
Kafka采用的是pull方式还是push的方式
Kafka是在,producer到broker的部分采用的是pull方式。但是消费者consumer从broker拉去信息的时候采用的是push拉信息的方式。 -
Kafka和传统消息传递系统的不同
- Kafka是分布式的系统
- Kafka支持流式数据
-
数据传输的事务定义有哪三种
- 最多一次:消息不会被重复发送,最多被发送一次。
- 最少一次:可能会重复发送,最少发送一次
- 情却一次: 只发送一次
-
Kafka如何判断节点是否还活着
- 通过Zookeeper的心跳机制















 5919
5919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









