






 本文围绕美团广告系统展开,介绍了计算广告的类别、核心问题及典型投放系统。重点阐述搜索广告,包括其收费模式、从请求到展现的召回、预估、排序三部分。召回采用显示查询扩展和隐式向量召回结合;预估用AUC等评价,多采用深度学习模型;机制涉及流量分配和定价,要平衡多方利益。
本文围绕美团广告系统展开,介绍了计算广告的类别、核心问题及典型投放系统。重点阐述搜索广告,包括其收费模式、从请求到展现的召回、预估、排序三部分。召回采用显示查询扩展和隐式向量召回结合;预估用AUC等评价,多采用深度学习模型;机制涉及流量分配和定价,要平衡多方利益。
系列文章
总览
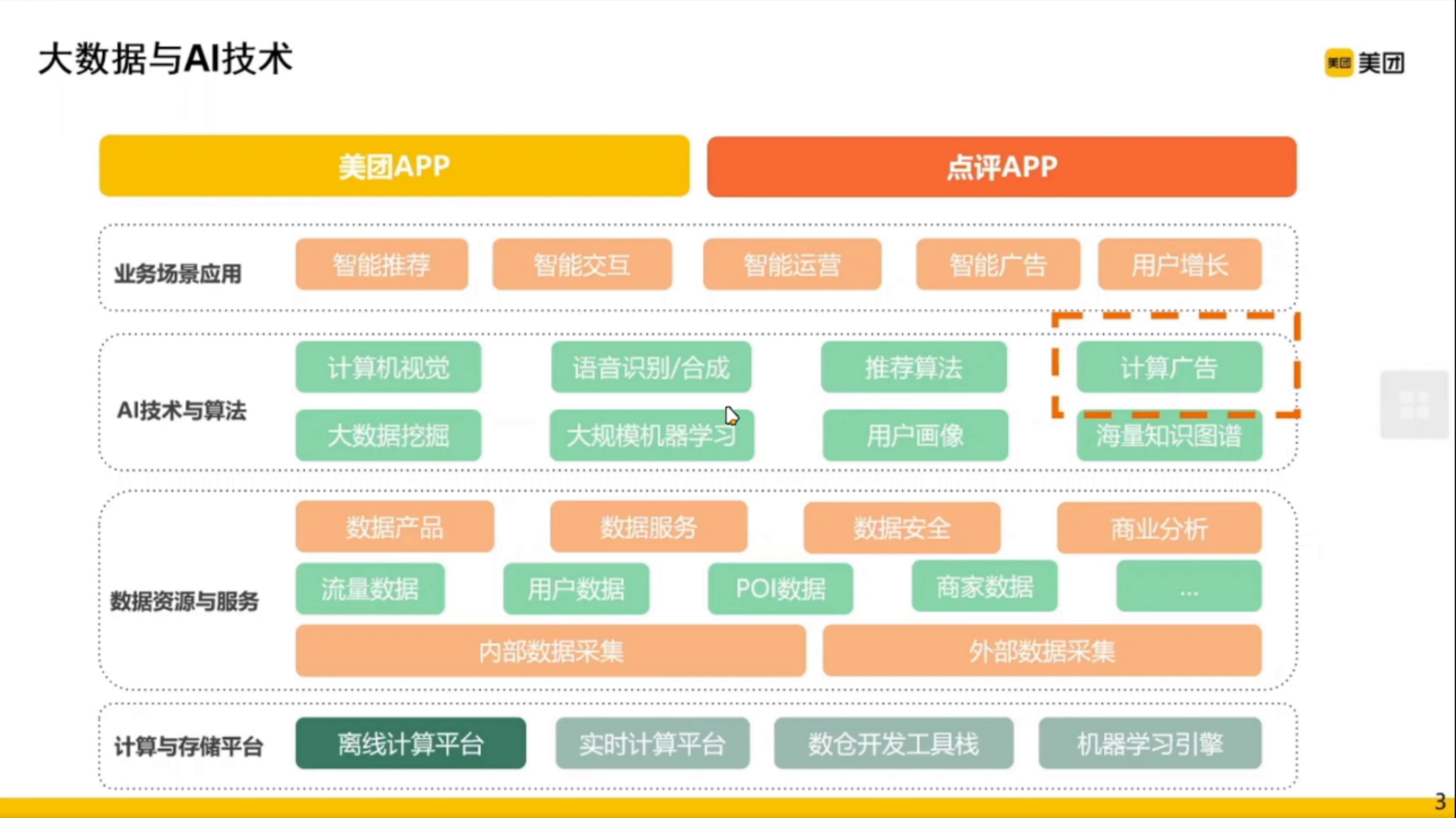
一、计算广告
计算广告,那什么是广告呢?

广告的类别:
- 品牌广告:创造独特的良好的品牌或产品形象,目的在于提升较长时期内的离线转化率。(例:钻石恒久远,一颗永流传)
- 效果广告:有短期内明确用户转化行为诉求的广告。用户转化行为例如:下载、注册、激活、购买等。
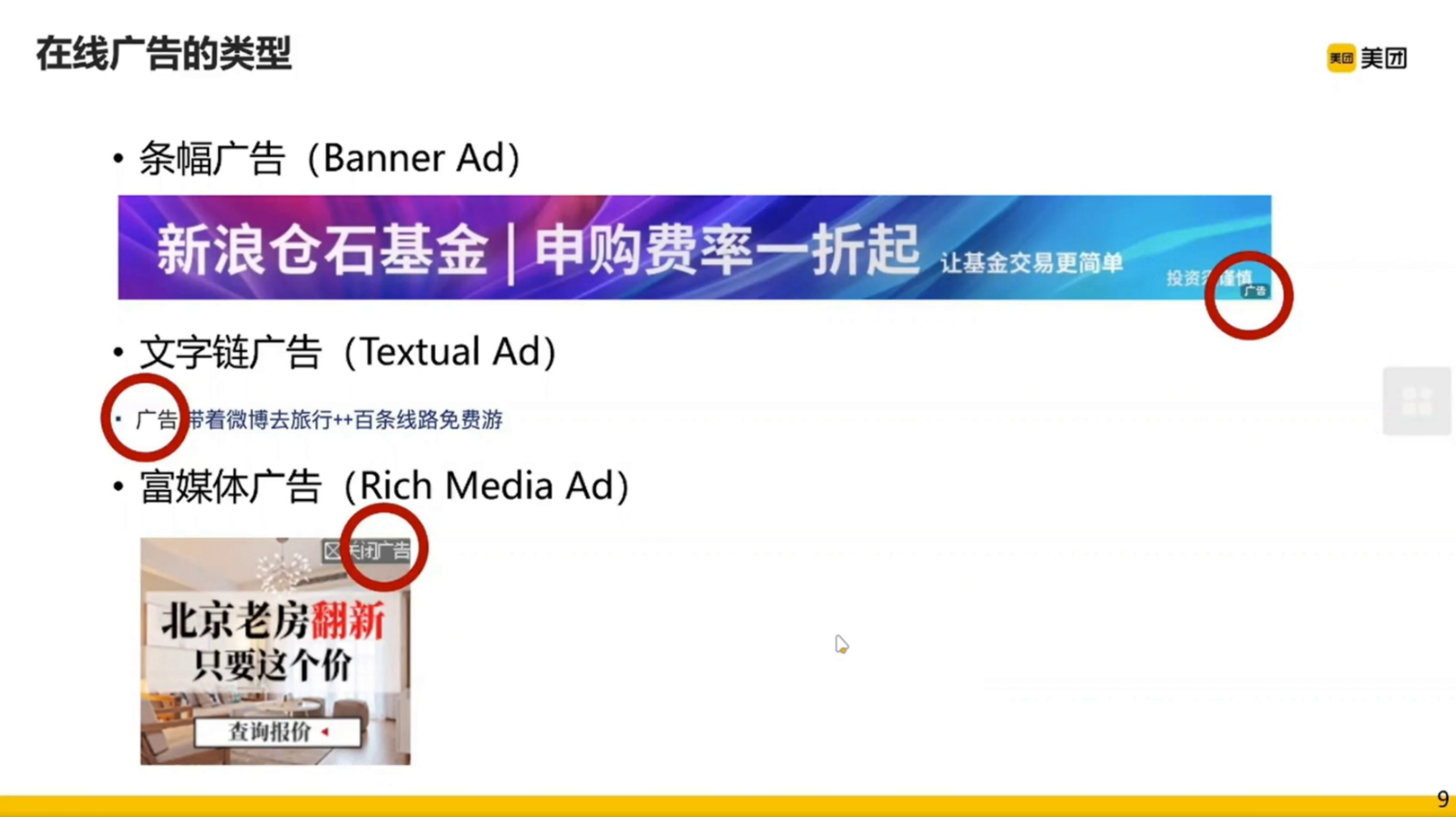
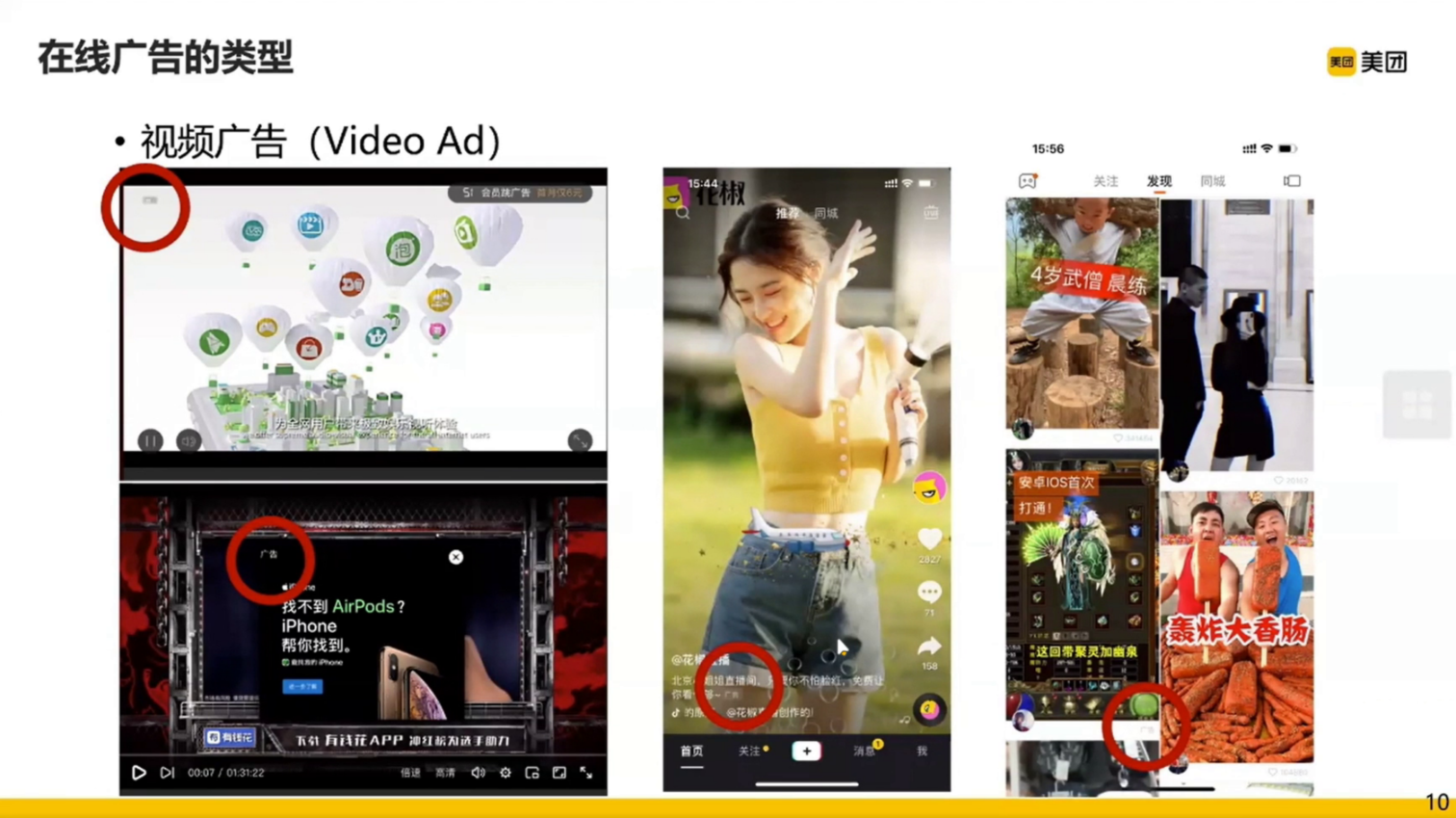

在线广告的核心问题:如何找到一个用户 u 在给定上下文 c 的情况下最匹配的广告 a 。
ROI :投入产出比

m a x a 1 , . . . , T ∑ i = 1 T R O I ( a i , u i , c i ) max_{a_1,...,T}\sum^T_{i=1}ROI(a_i, u_i,c_i) maxa1,...,T∑i=1TROI(ai,ui,ci) —— 使得所有 T 个广告总投入产出比最高
I n v e s t m e n t = X ∗ C P X ( X = M , C , A 等 ) Investment = X * CPX (X= M,C,A 等) Investment=X∗CPX(X=M,C,A等)
-
CPM(Cost Per Mille) :展现成本,或者叫千人展现成本。
-
CPC(Cost Per Click): 点击成本,即每产生一次点击所花费的成本。
-
CPA(Cost Per Action):每转化成本。即按转化收费。
R e t u r n = ∑ i = 1 T μ ( a i , u i , c i ) v ( a i , u i ) = ∑ i = 1 T e ( a i , u i , c i ) Return = \sum^T_{i=1}\mu(a_i, u_i,c_i)v(a_i,u_i) = \sum^T_{i=1}e(a_i,u_i,c_i) Return=∑i=1Tμ(ai,ui,ci)v(ai,ui)=∑i=1Te(ai,ui,ci)
- μ \mu μ 为点击率
- ( a i , u i , c i ) (a_i, u_i,c_i) (ai,ui,ci) 为点击量
- v ( a i , u i ) v(a_i,u_i) v(ai,ui) 每次点击产生的价值
$ROI = \frac{Return}{Investment} * 100% $
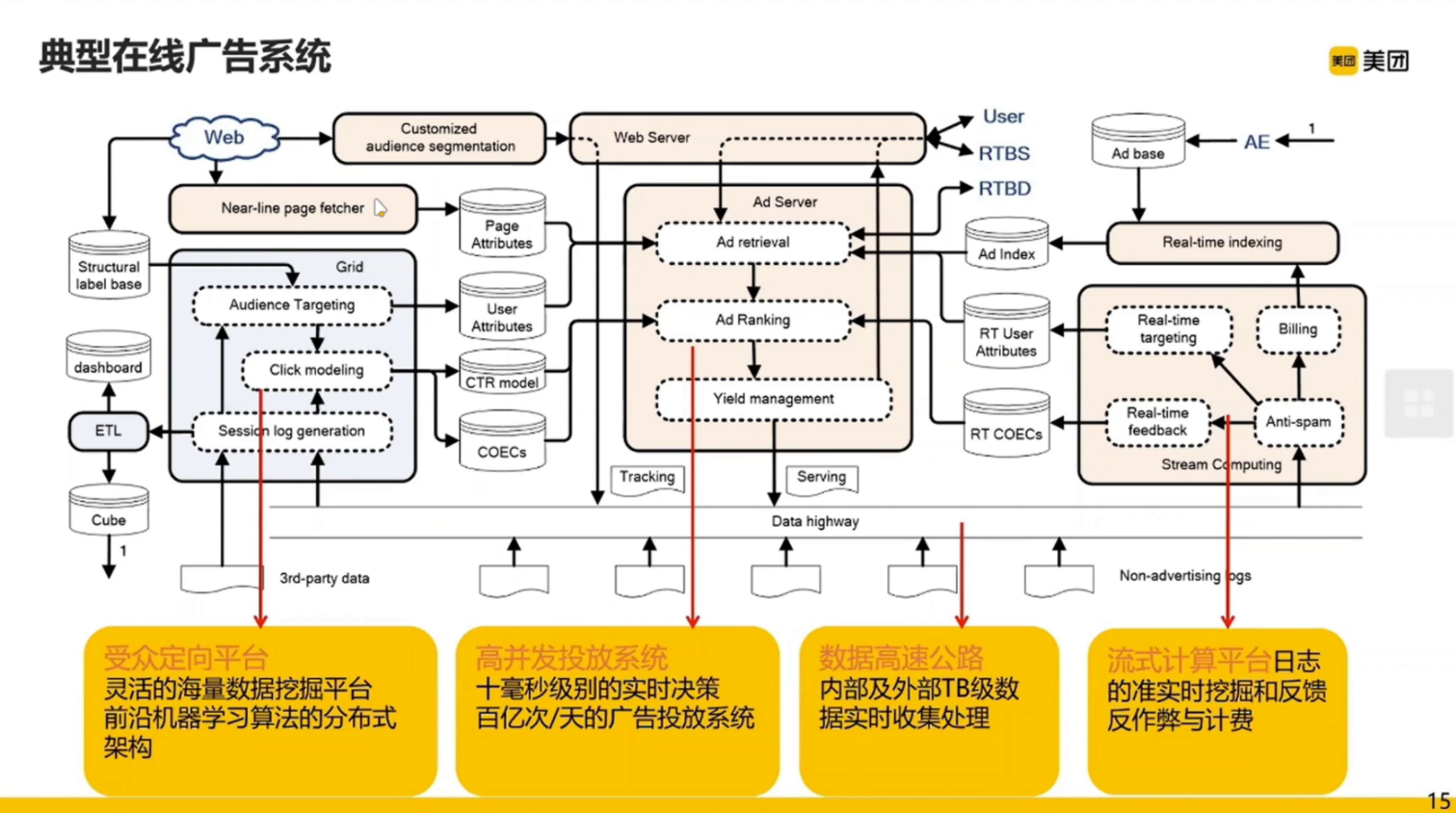
这里介绍一个典型广告投放系统。
从右上角,假如一个用户进入某个页面,首先会进行广告检索,看广告库存有多少(相关广告)(通过 Ad Index 到 Ad retrieval ),检索完之后进行广告的排序(Ad rank),之后经过收益管理(Yield management)将广告返回给用户。
左半部分是对中间部分的详细展现。
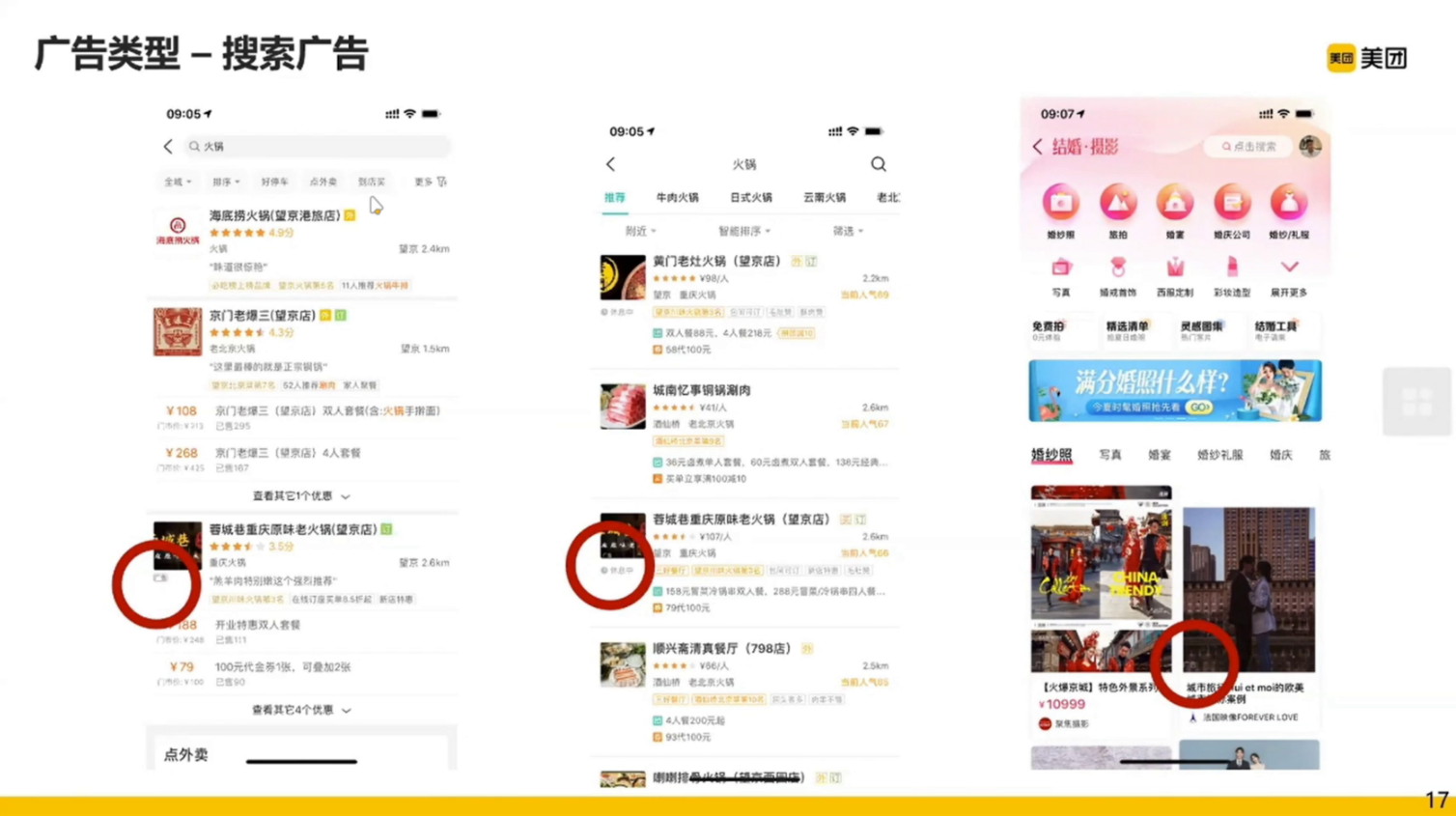
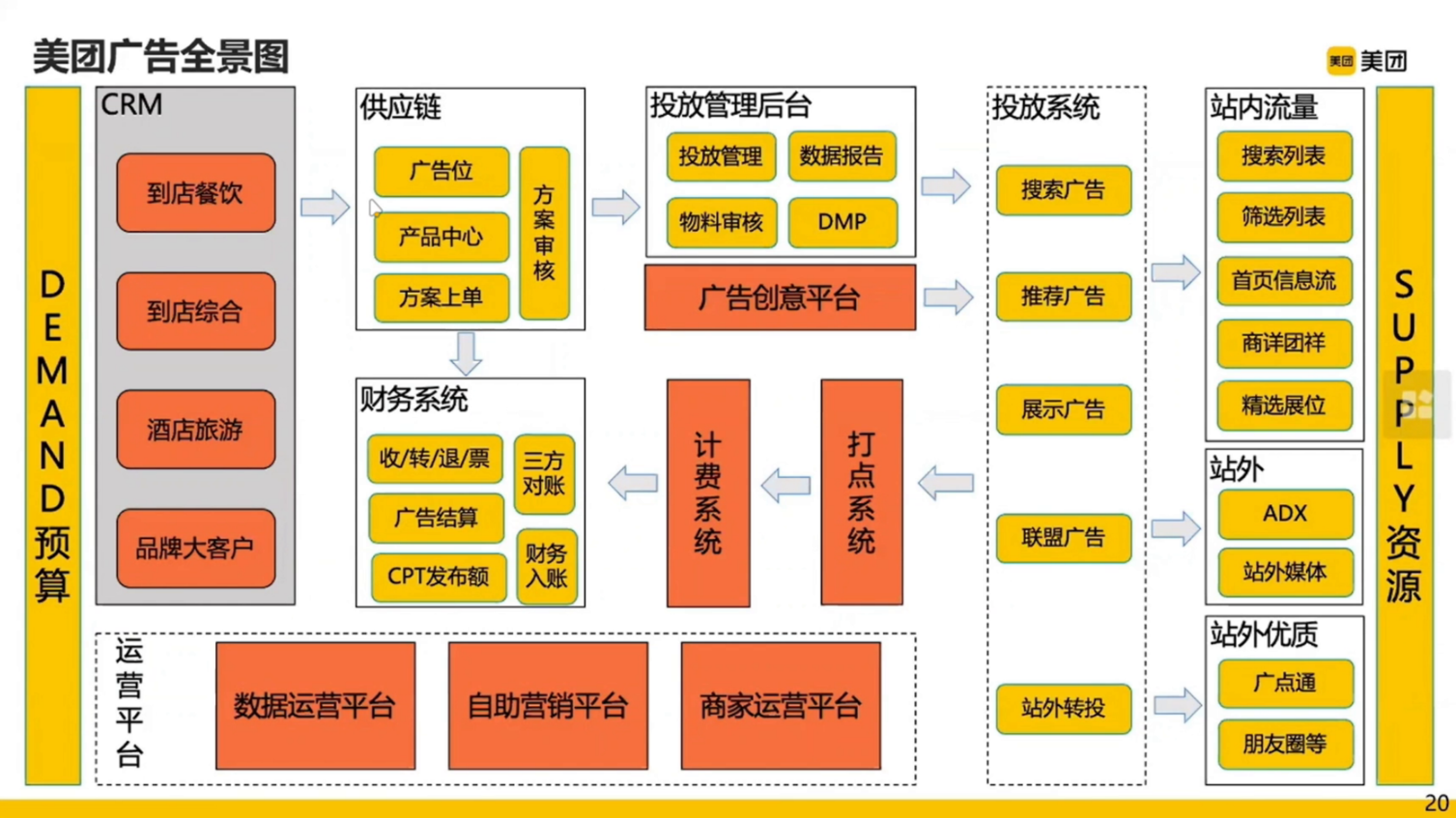
下面介绍一下美团的广告。
搜索广告一般有 query 的广告,一般用户有明确的意图。
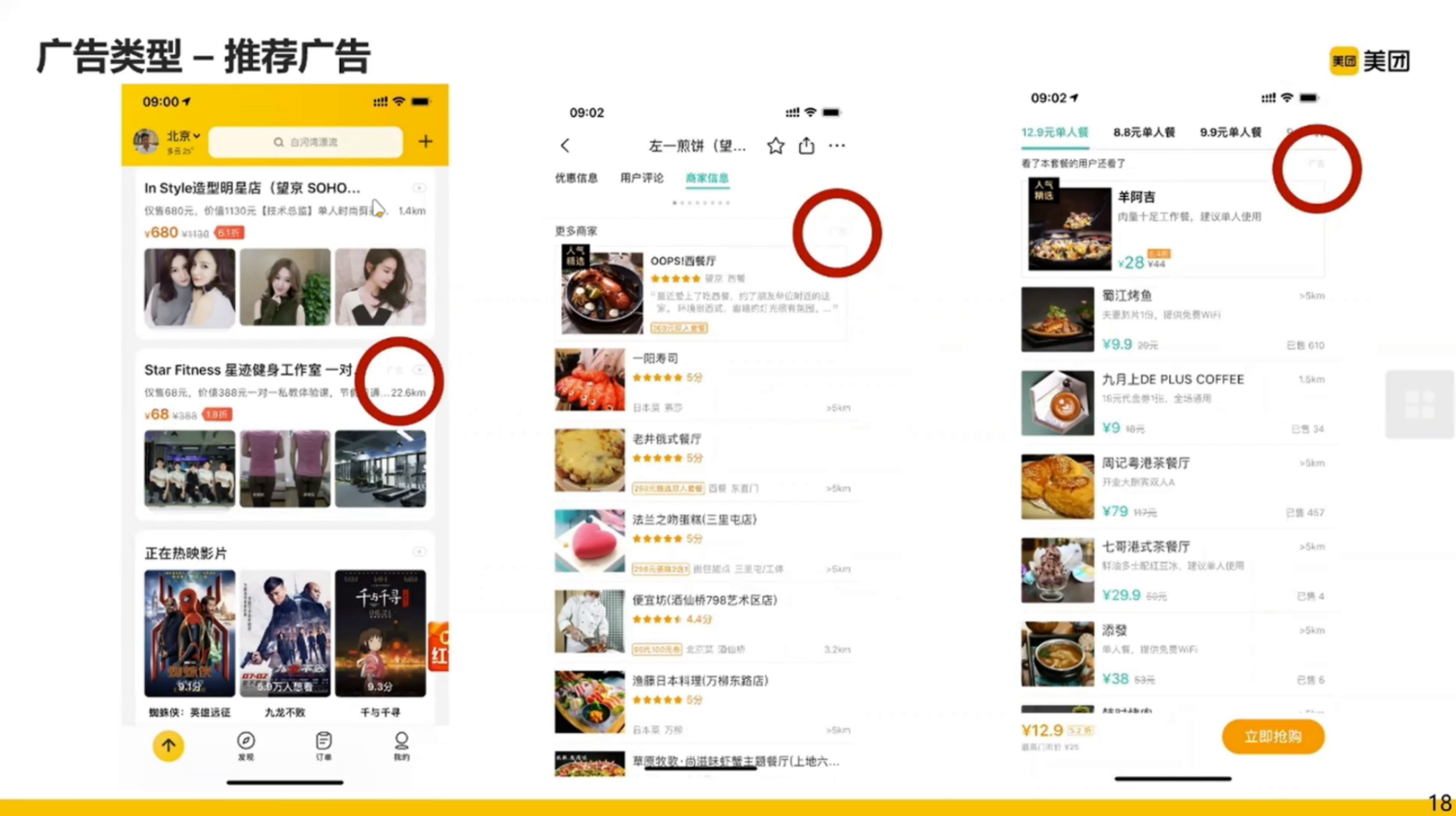
推荐广告一般在某一类别下出现
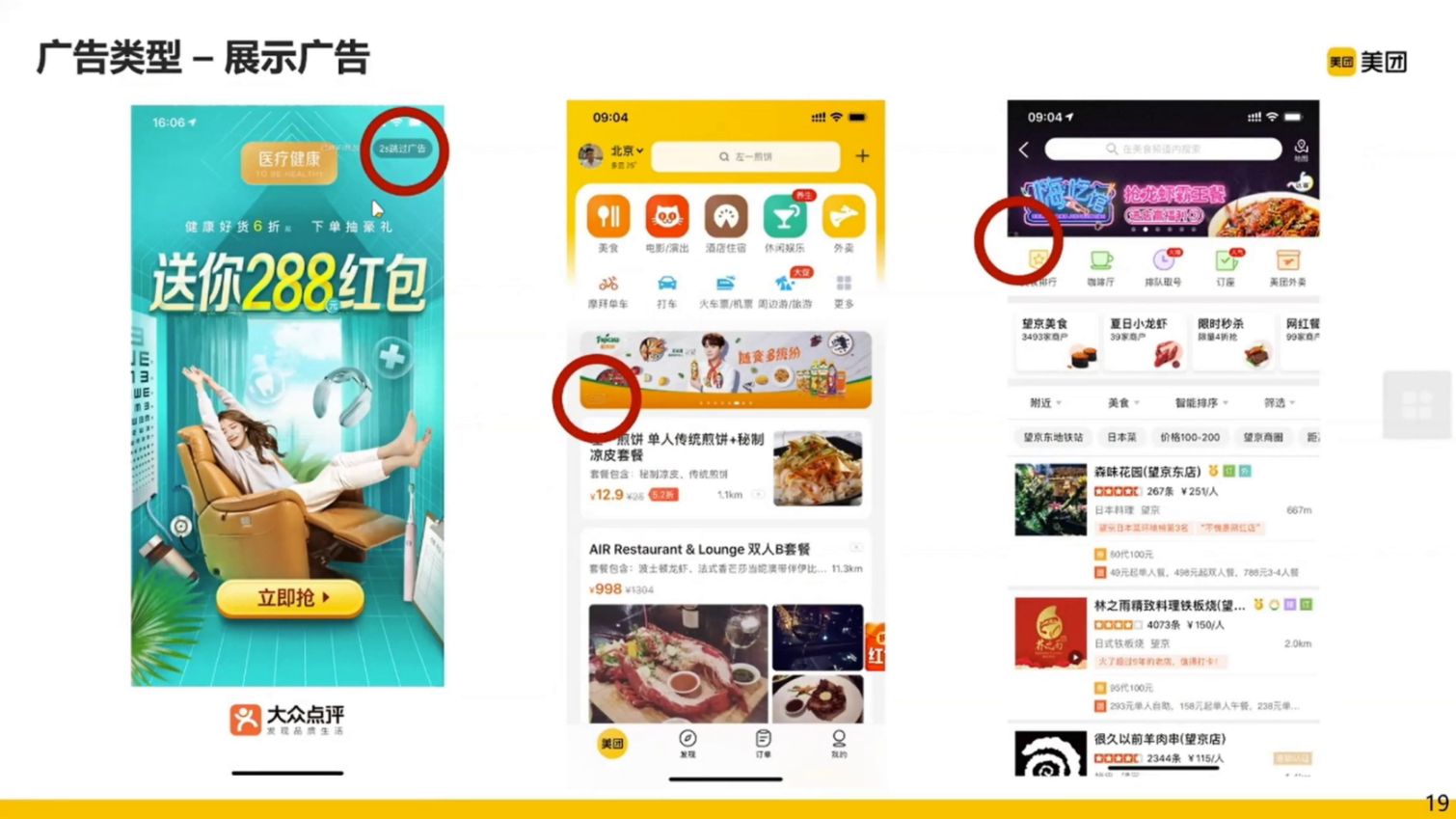
展示广告
广告全景图
CRM(Custom Relationship Management)
二、搜索广告
接下来我们主要讲搜索广告:

按点击收费,一段时间内点击只算一次钱。
曝光流量:一次请求返回的商品列表
曝光密度:返回的商品列表中广告的数量
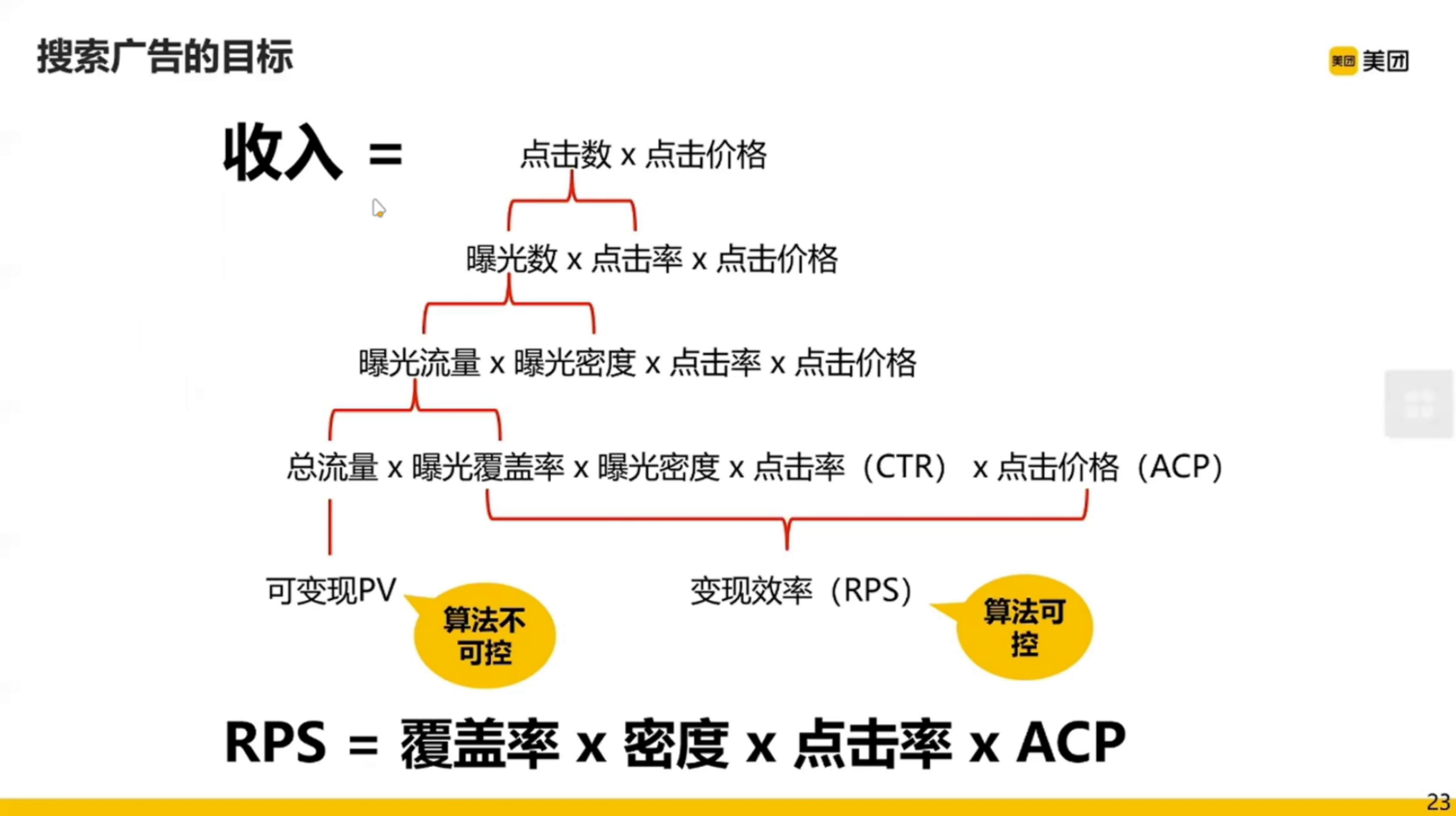
总流量是算法不可控的,我们主要关注可控的后半部分。
广告从请求到展现过程主要包含三部分:召回、预估、排序。
再看会我们上一页得到的和收入相关的公式,其中
- 覆盖率、密度、点击率是和召回相关的
- 点击率也和预估有关
- 而 ACP 和机制(包含排序)有关
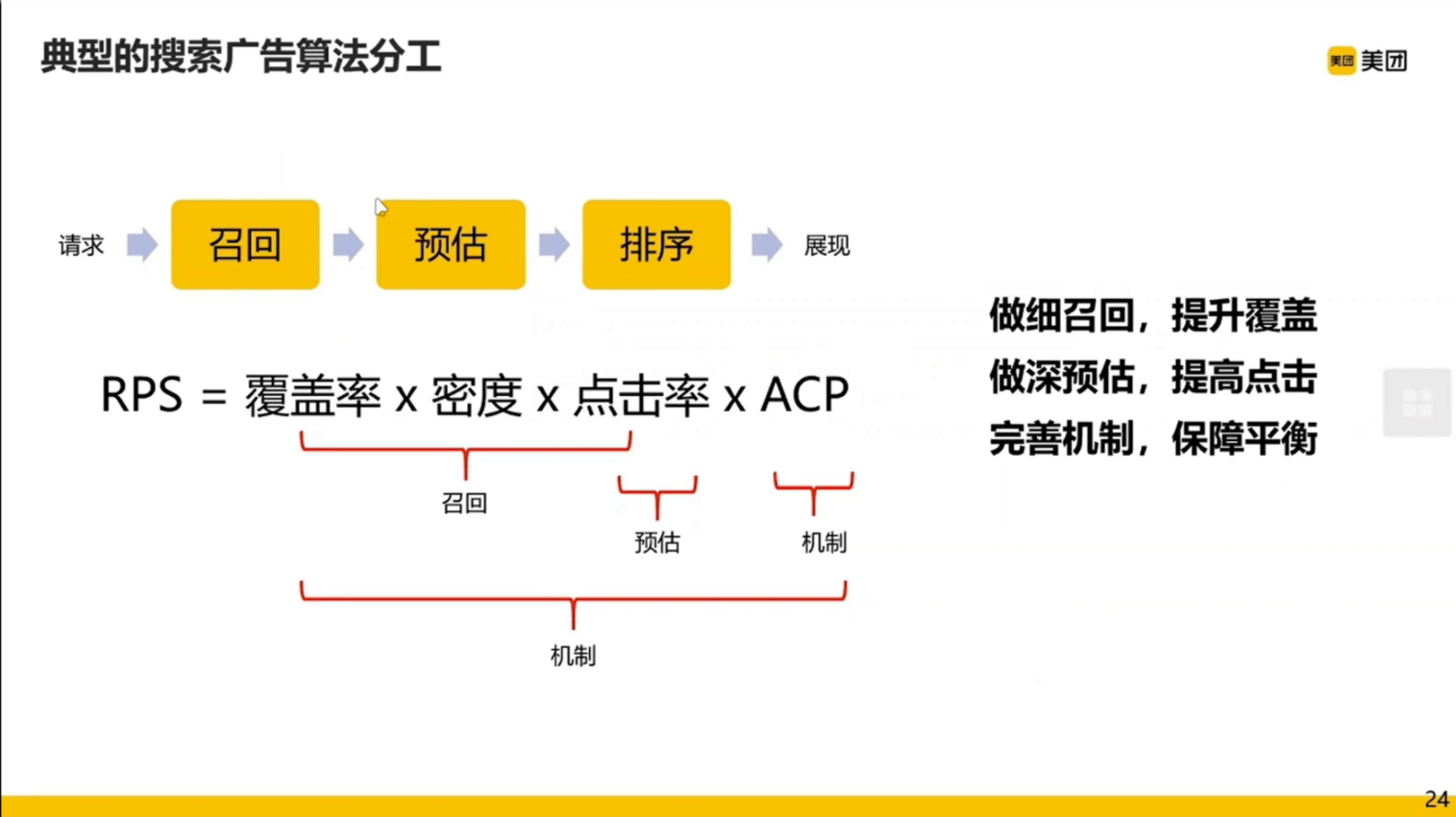
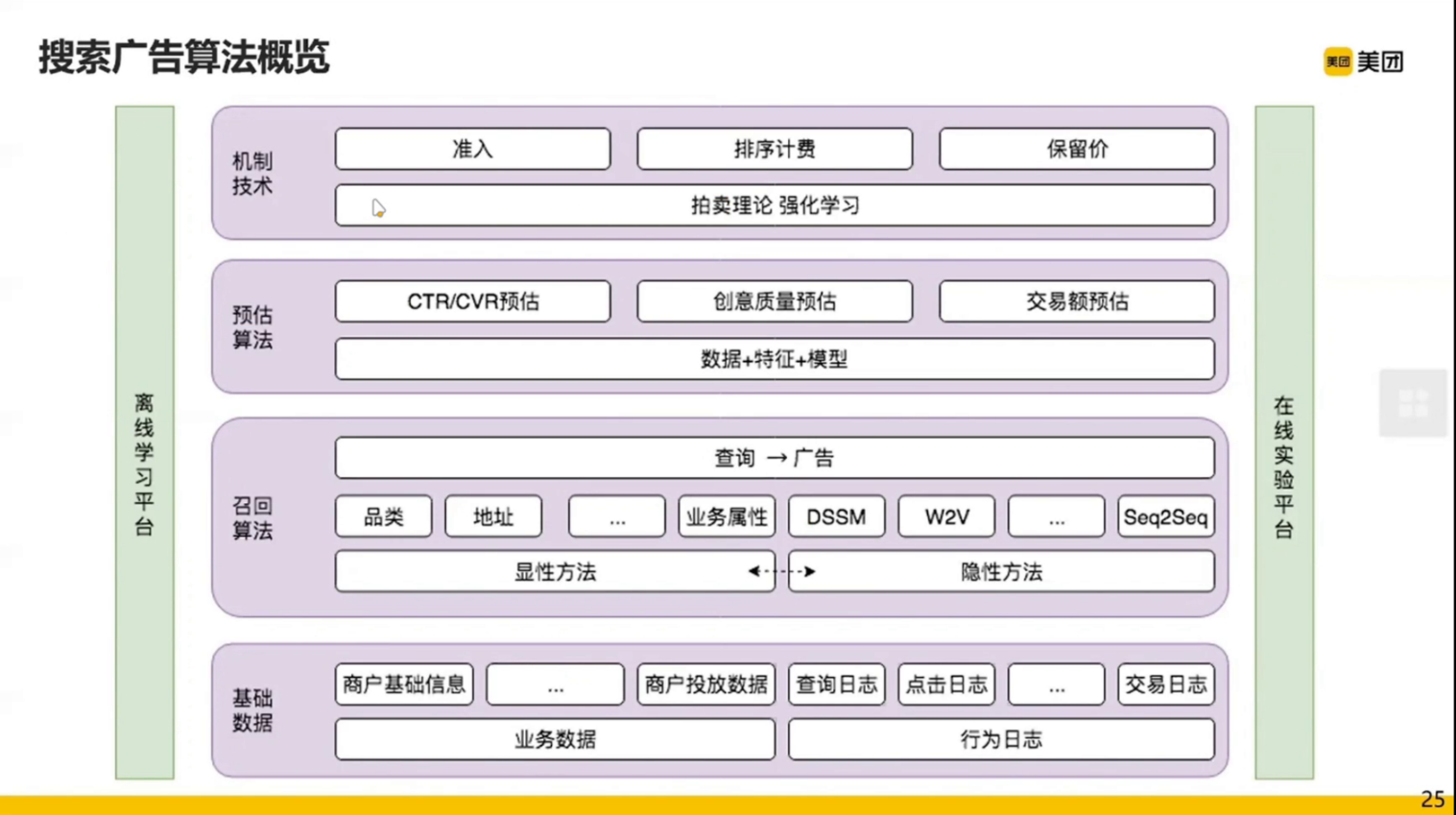
然后我们先讲召回:
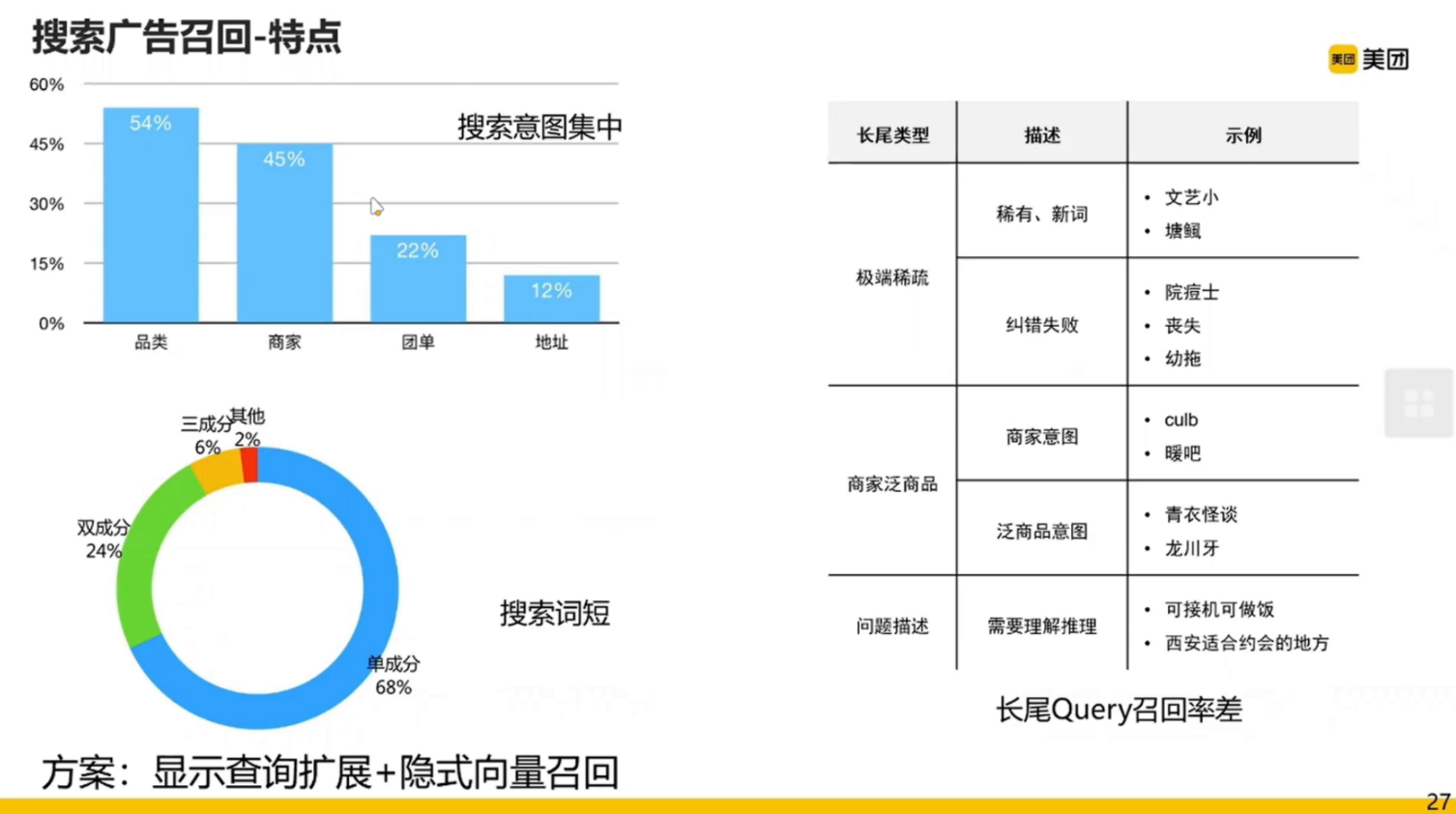
召回的特点:
- 搜索意图集中
- 搜索词短
- 长尾 Query 召回率差
为了把所有相关的广告广告都不漏掉,选择了显示查询扩展和隐式向量召回结合的方法。
无论显示找召回还是隐式召回,都会有很强的相关性控制。
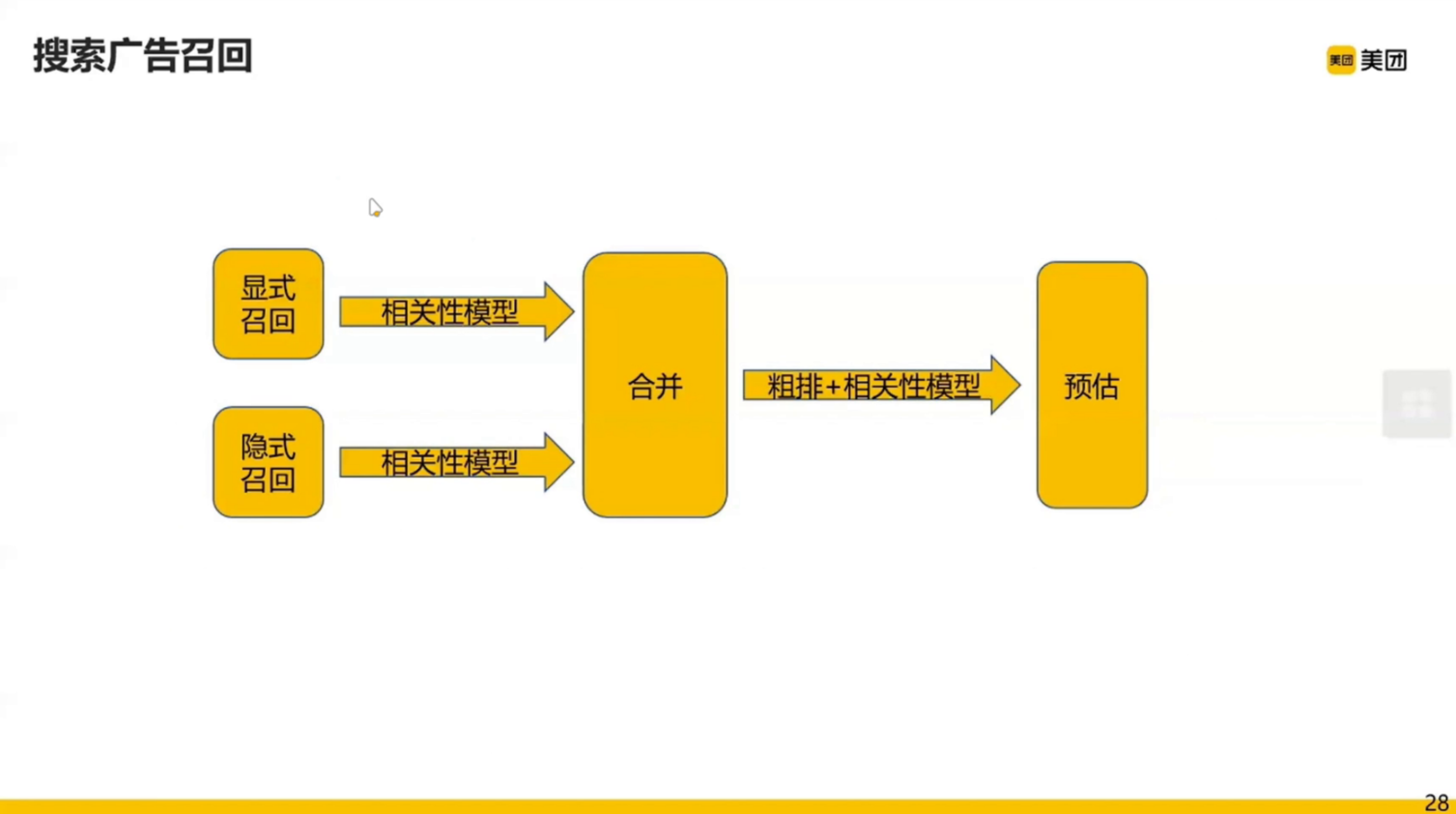
召回的具体形式是什么呢?
下图上半部分是显示召回,下半部分是隐式向量召回。
-
显示召回主要是索引词扩展,即上文提到的搜索查询扩展。
-
隐式召回主要通过向量引擎计算用户向量和目标列表向量的相似度。
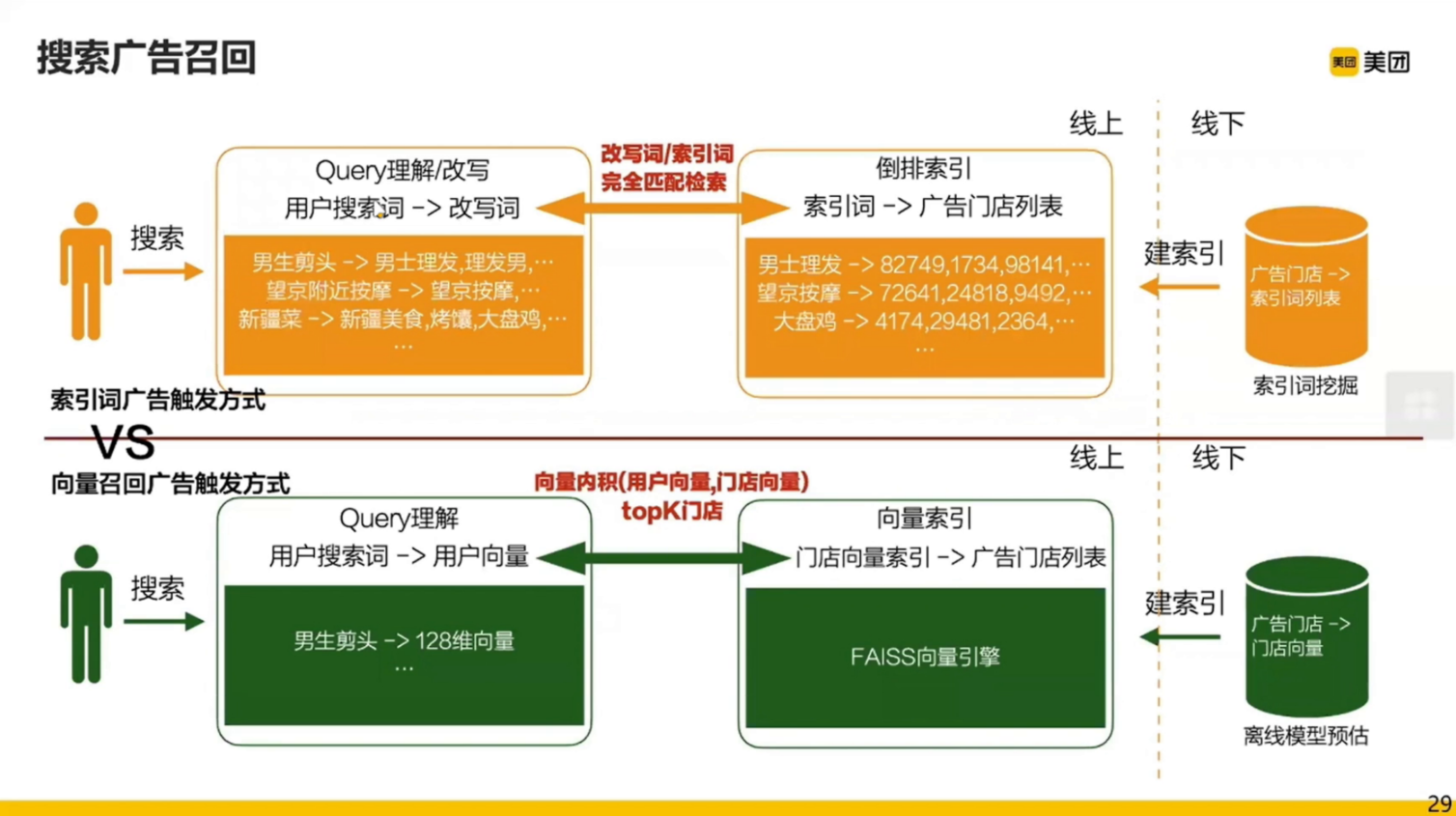
显示召回的详细流程:
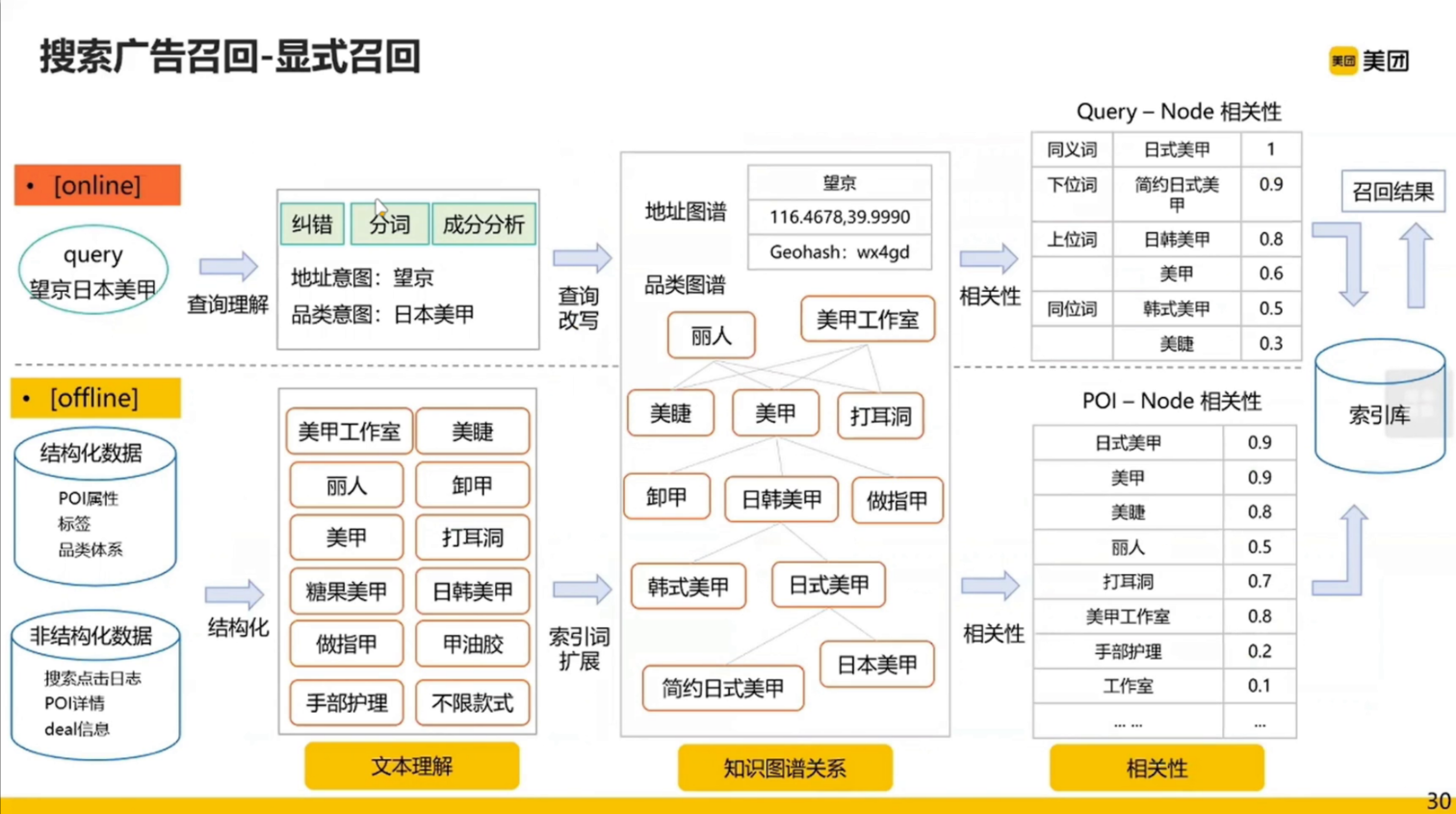
隐式召回详细流程:
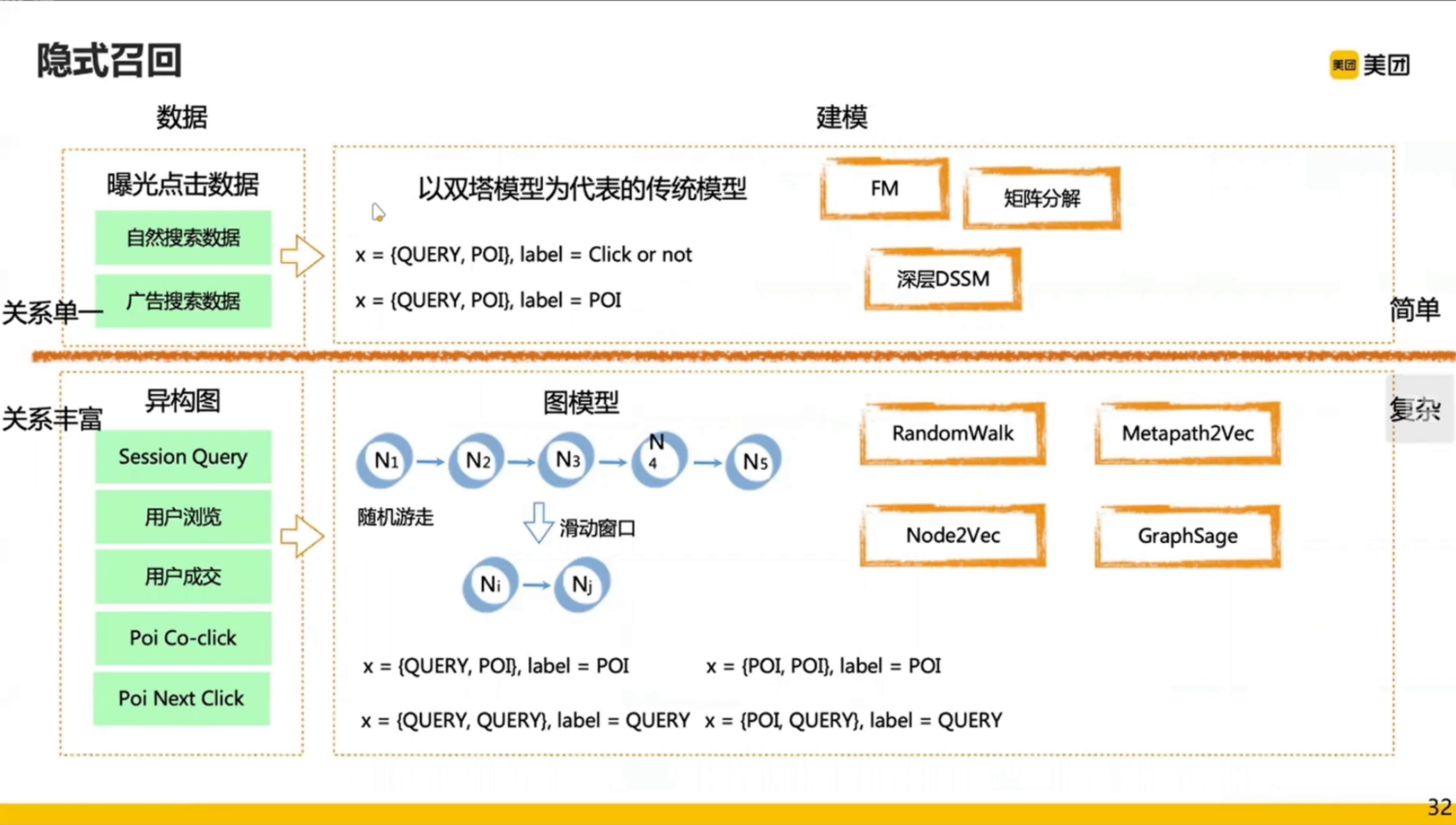
双塔模型用到的数据很少,样本只用到了用户的 Query 和 POI;而图模型用到的样本就相对丰富了,比如用户点了两个 POI,这两个 POI 就有 co - click 的关系;但是速度较慢。
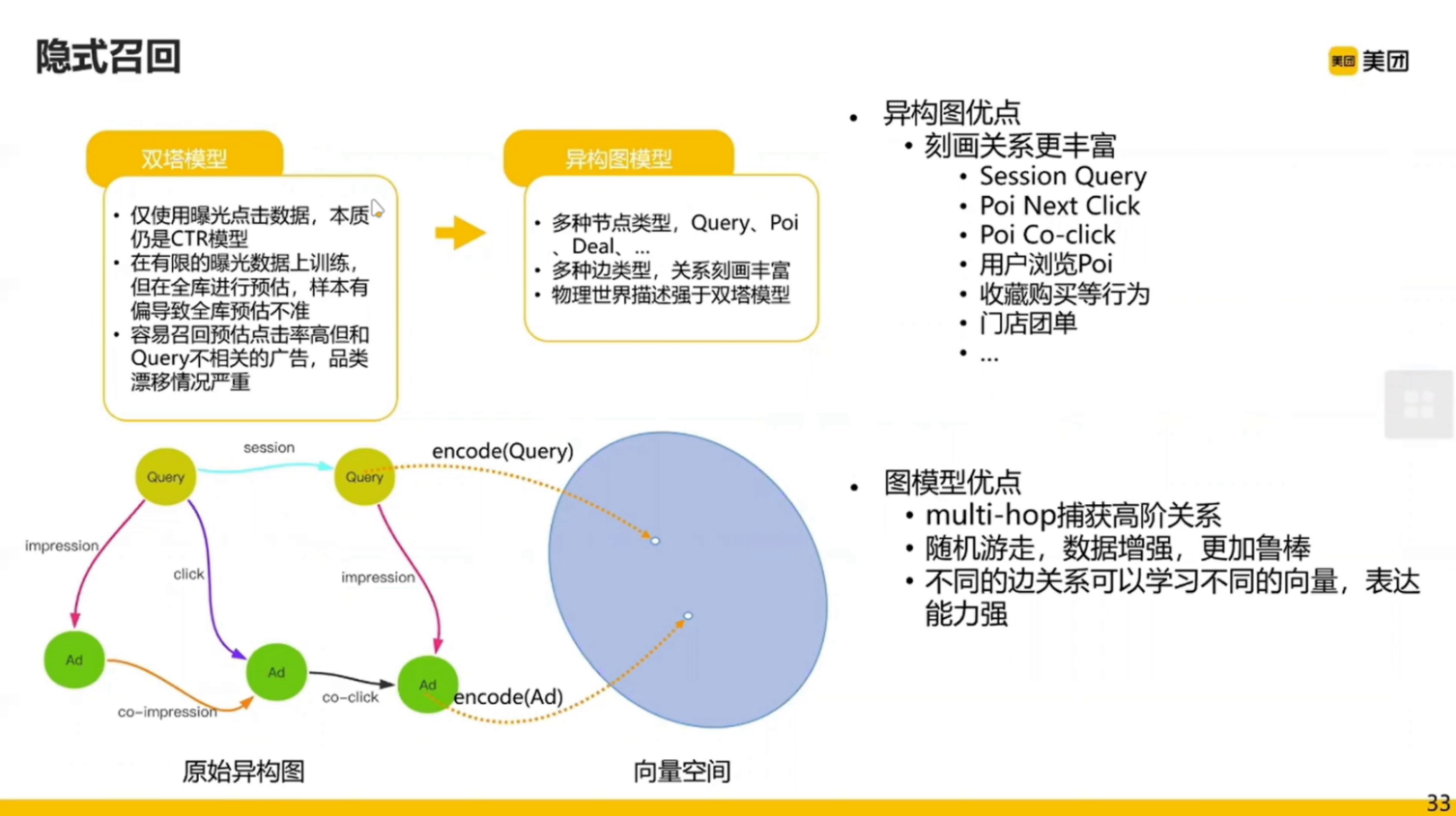
模型的整体策略:
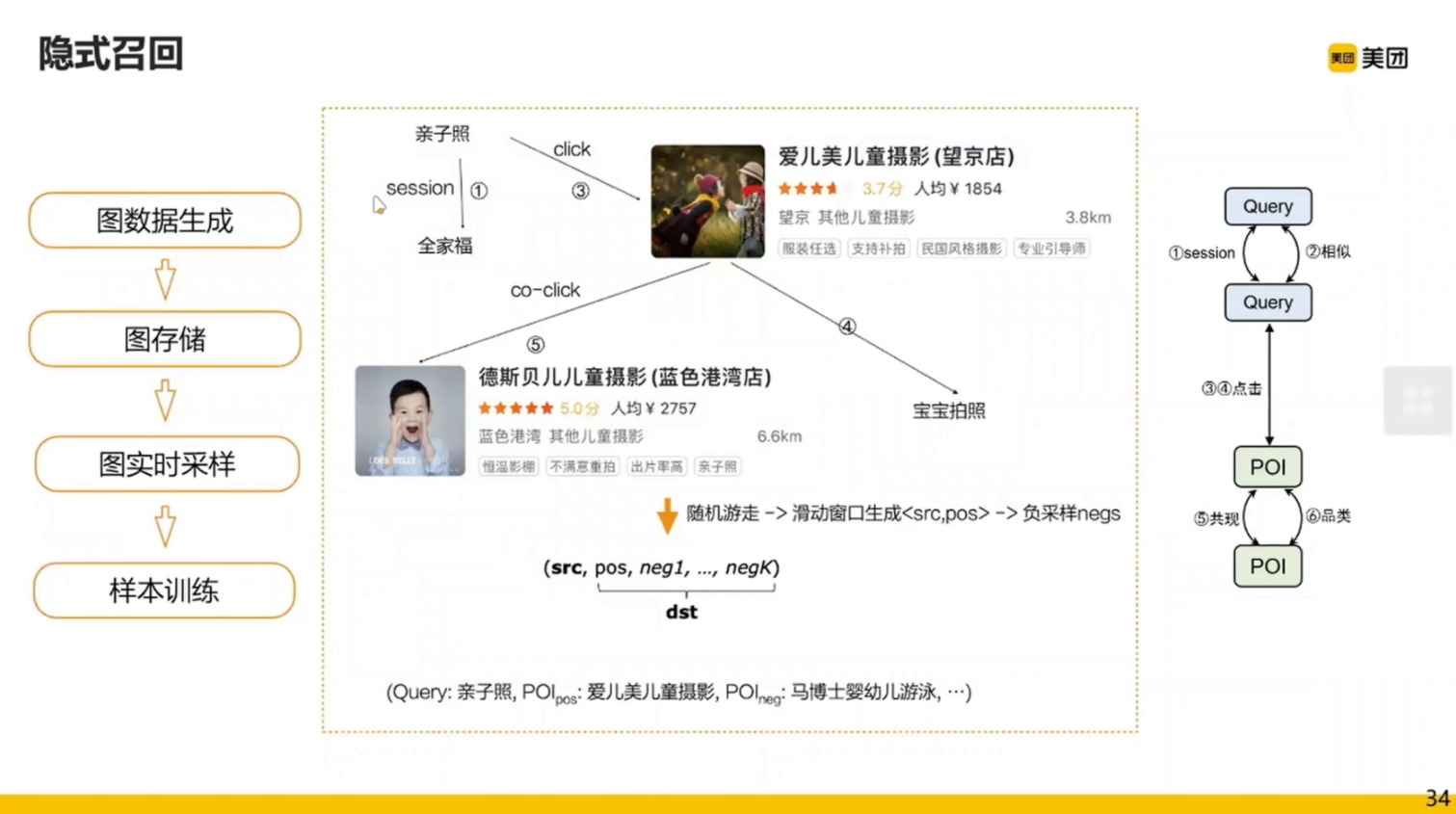
具体训练:
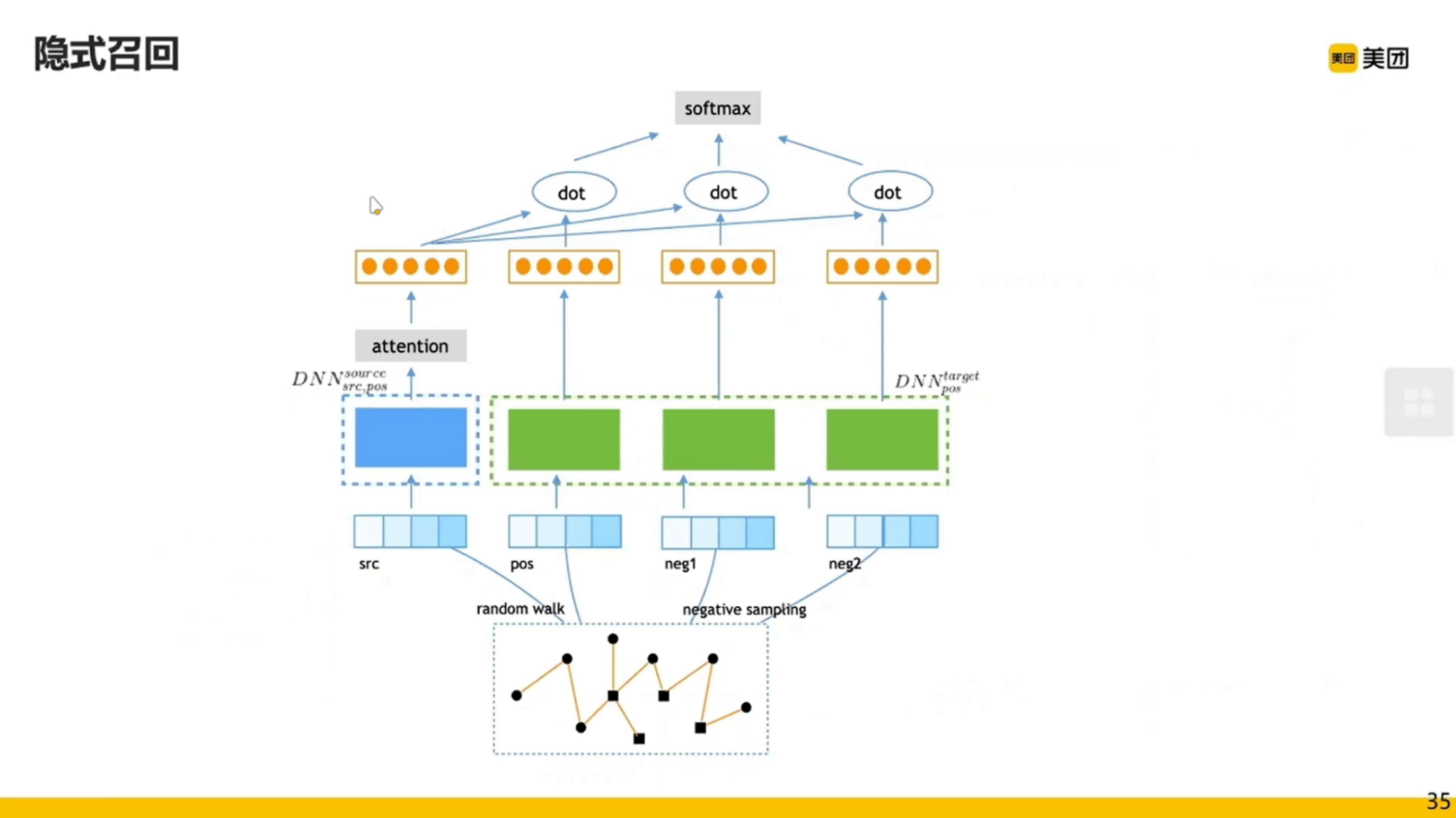
隐式召回也有缺点:
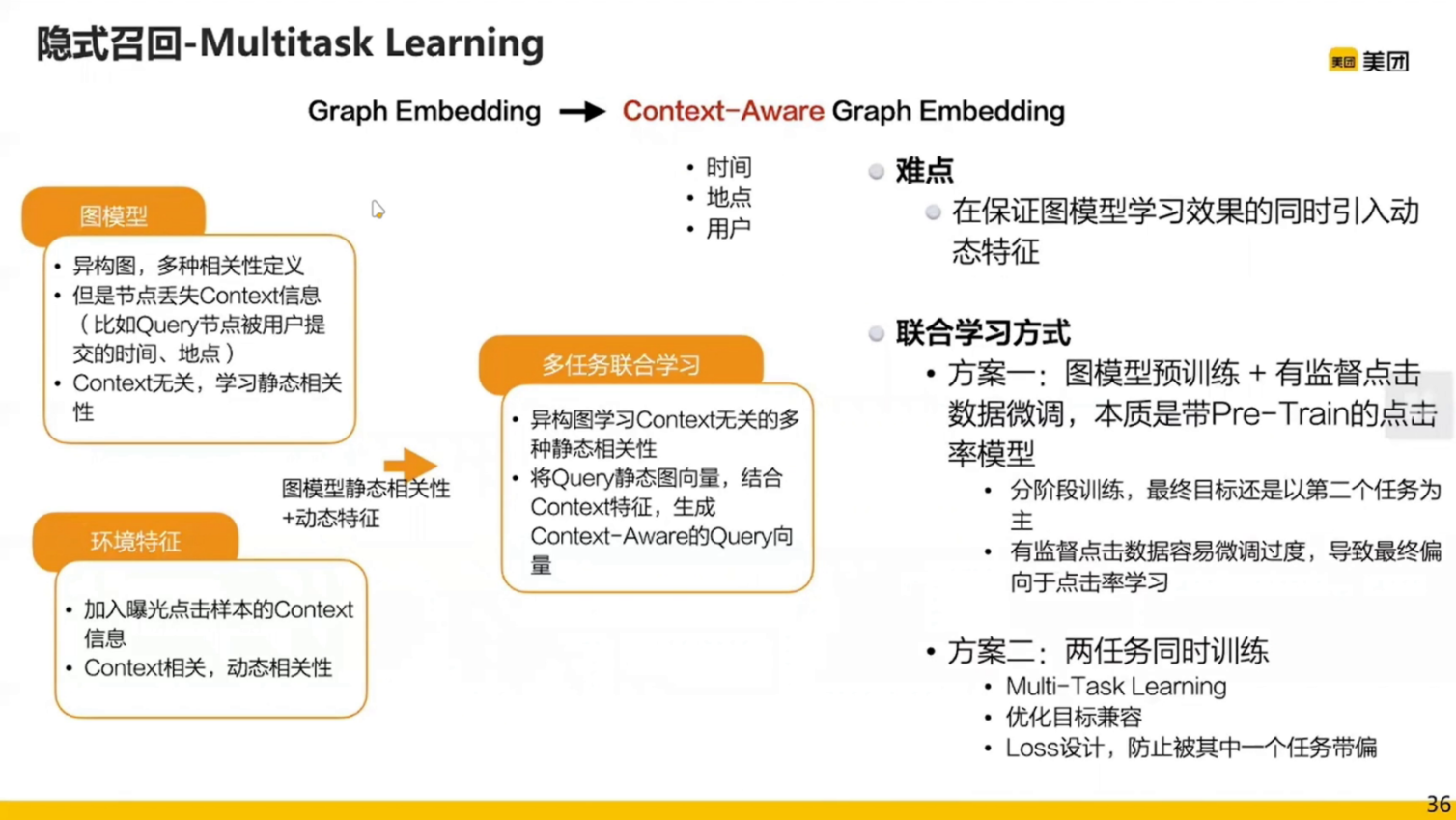
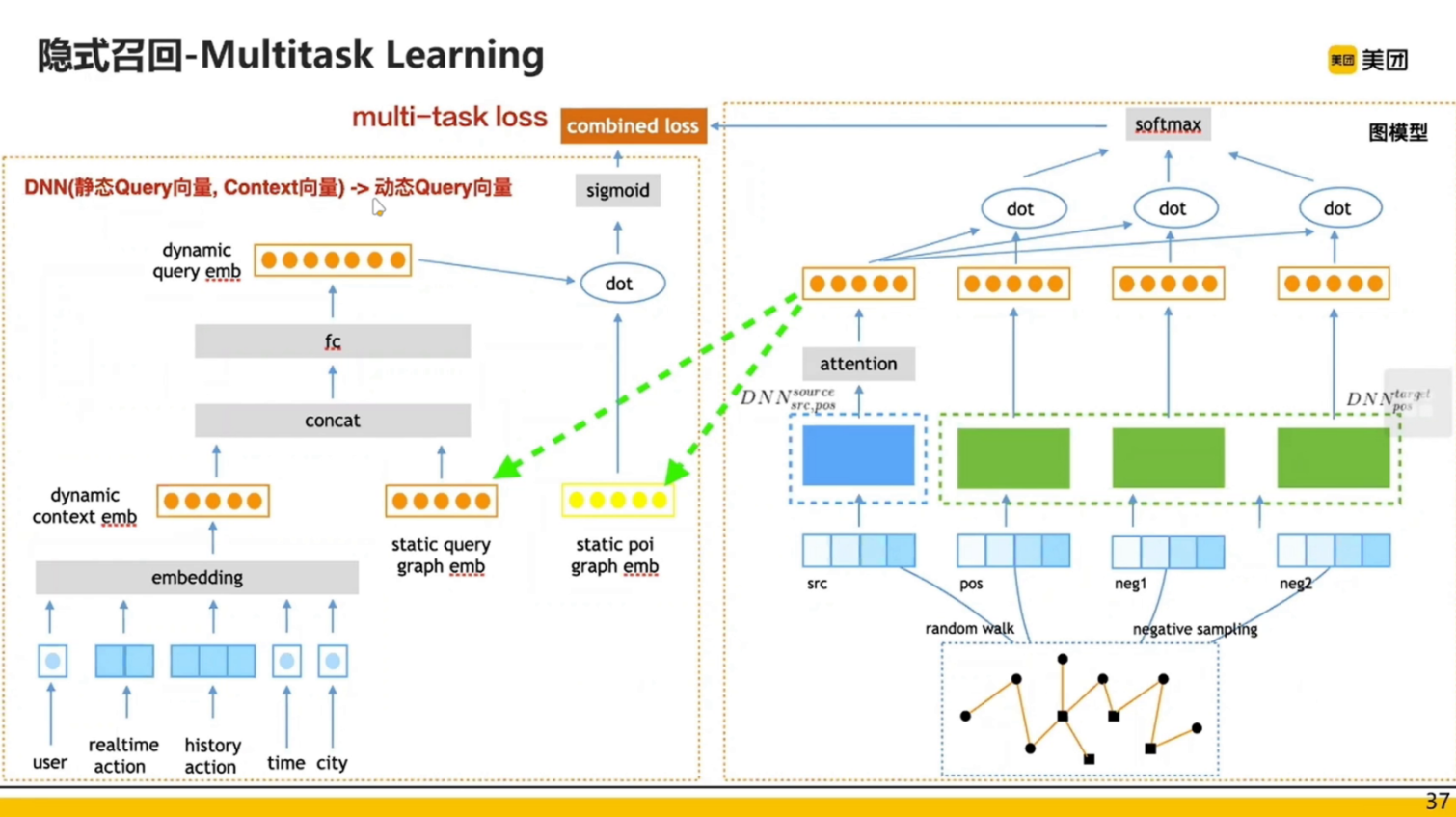
右边图模型的输出是两个向量,一个 query 的向量,一个 poi 的向量,加上一些上下文信息进行拼接,放到左边双塔模型中,进行 sigmoid 的输出。
2.1 预估
有了一个广告,去预测点击率。
搭建模型之前,我们了解一下什么是预估。

点击率的预估怎么评价呢?使用 AUC。为什么使用 AUC 呢,因为它可以规避样本不均衡的情况。因为预估的时候不能提前知道样本的分布情况,所以要提高模型的泛化能力就要使用 AUC。当然,有时候 AUC 对于工业界也不够,这时候可能就用 GAUC 了。
AUC 曲线越靠上越好。
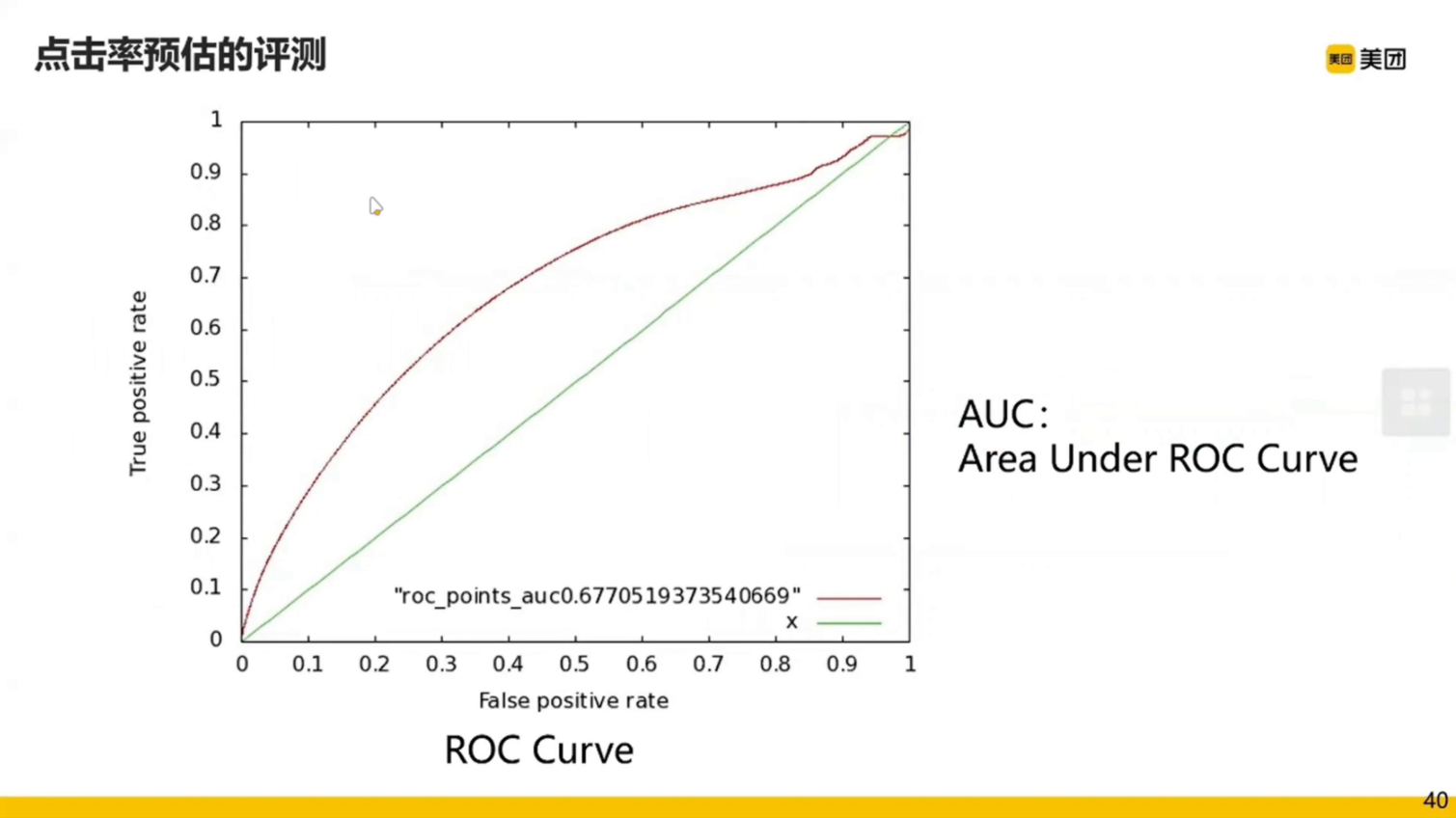
有了预估的评价指标,我们来看看特征如何选择。
分为三类:
- A:广告(advertisement)的特征
- U:用户(user)的特征
- C:上下文(context)特征

开始用的传统的树模型
- GBDT(2016.04):小数据、连续特征比较友好,可解释性比较好。
- FFM(2016.07):(Field-aware Factorization Machine)数据要够大,且离散特征较好。
- DRRM(2016.09):分布式的 FFM模型。
- 深度学习(2017.07):这里使用的 Wide&Deep(详解 Wide & Deep 结构背后的动机-知乎)
- 多任务学习(2018.03):一个模型做多任务
- Session WDL(2019.07):一段时间的查询结果会保留
- 多位次多模态预估(2020.03):

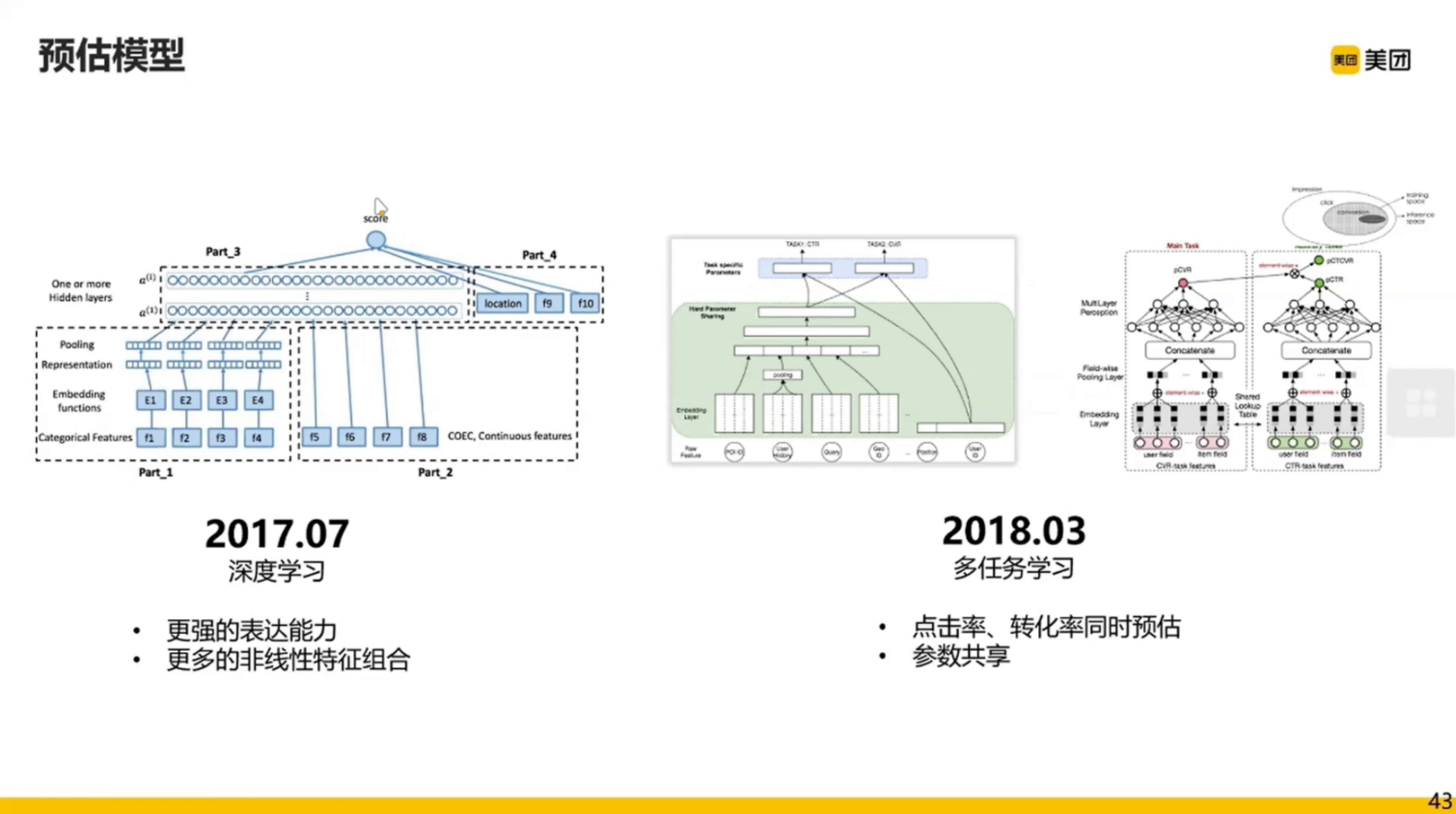
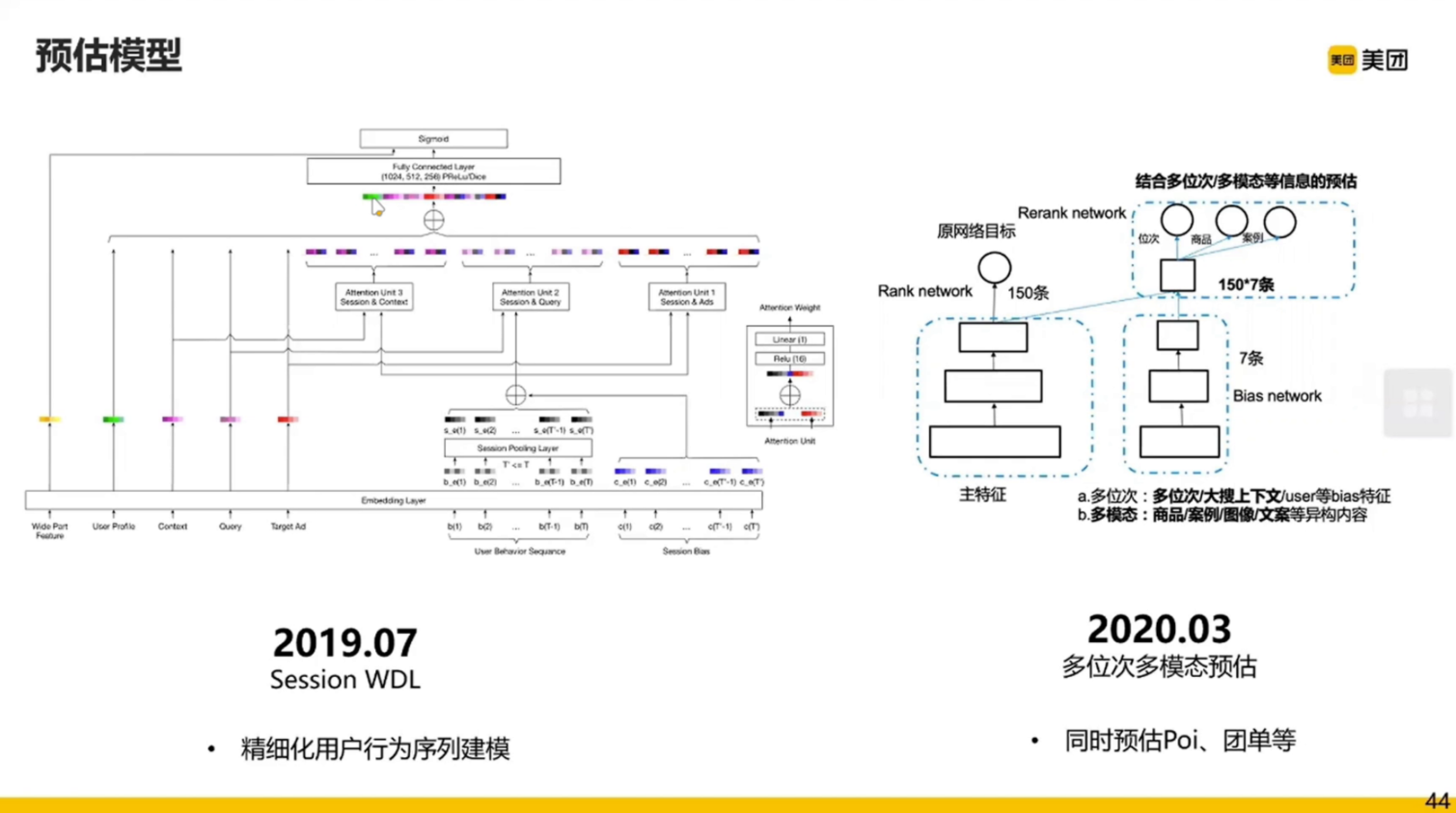
现在大部分都是深度学习模型,大部分都是组件化的,就像乐高一下组合模型进行试验。
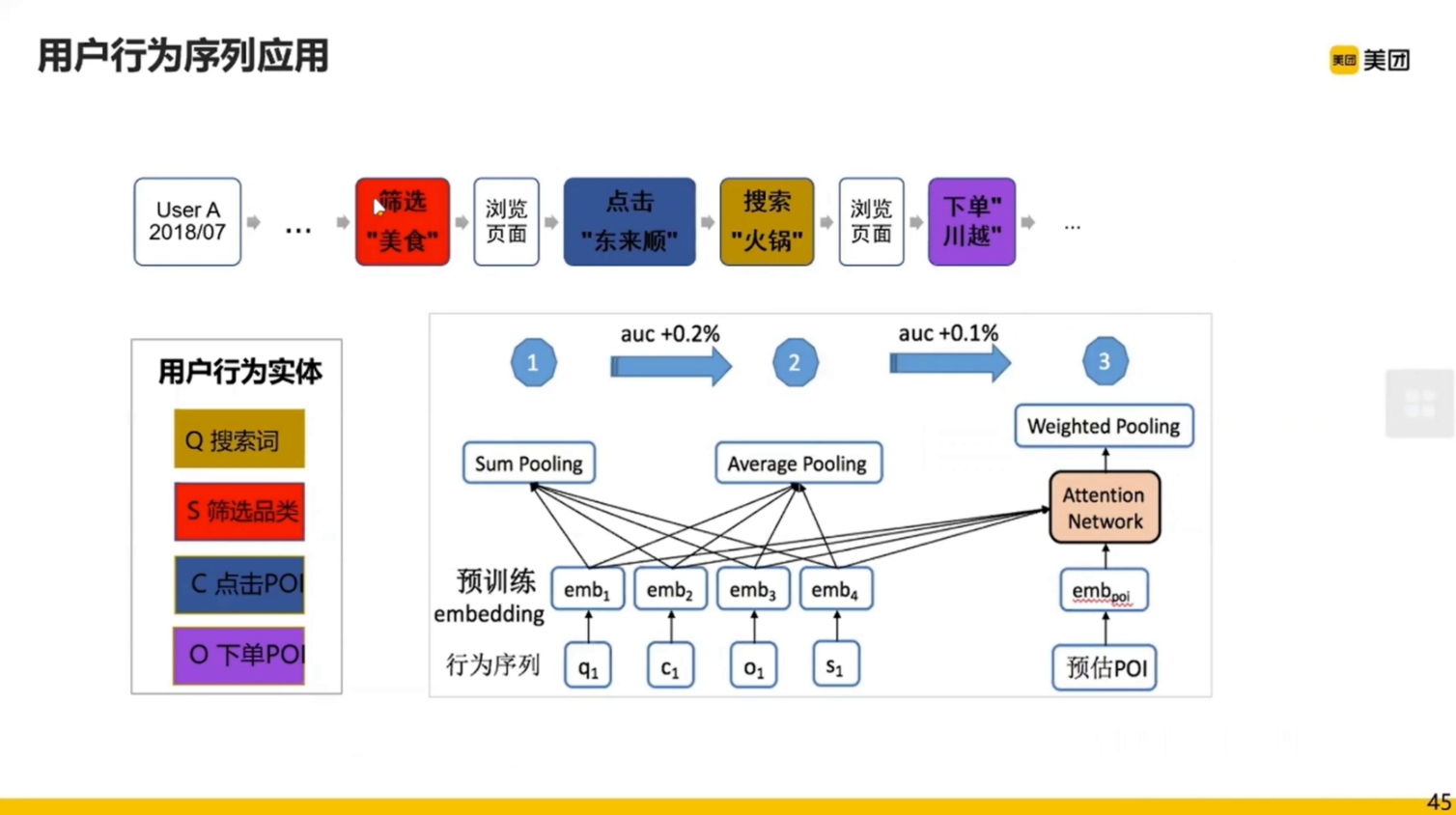
短时间内的用户行为序列大部分是相关的,长时间的用户行为序列中用户的兴趣是会转移的。
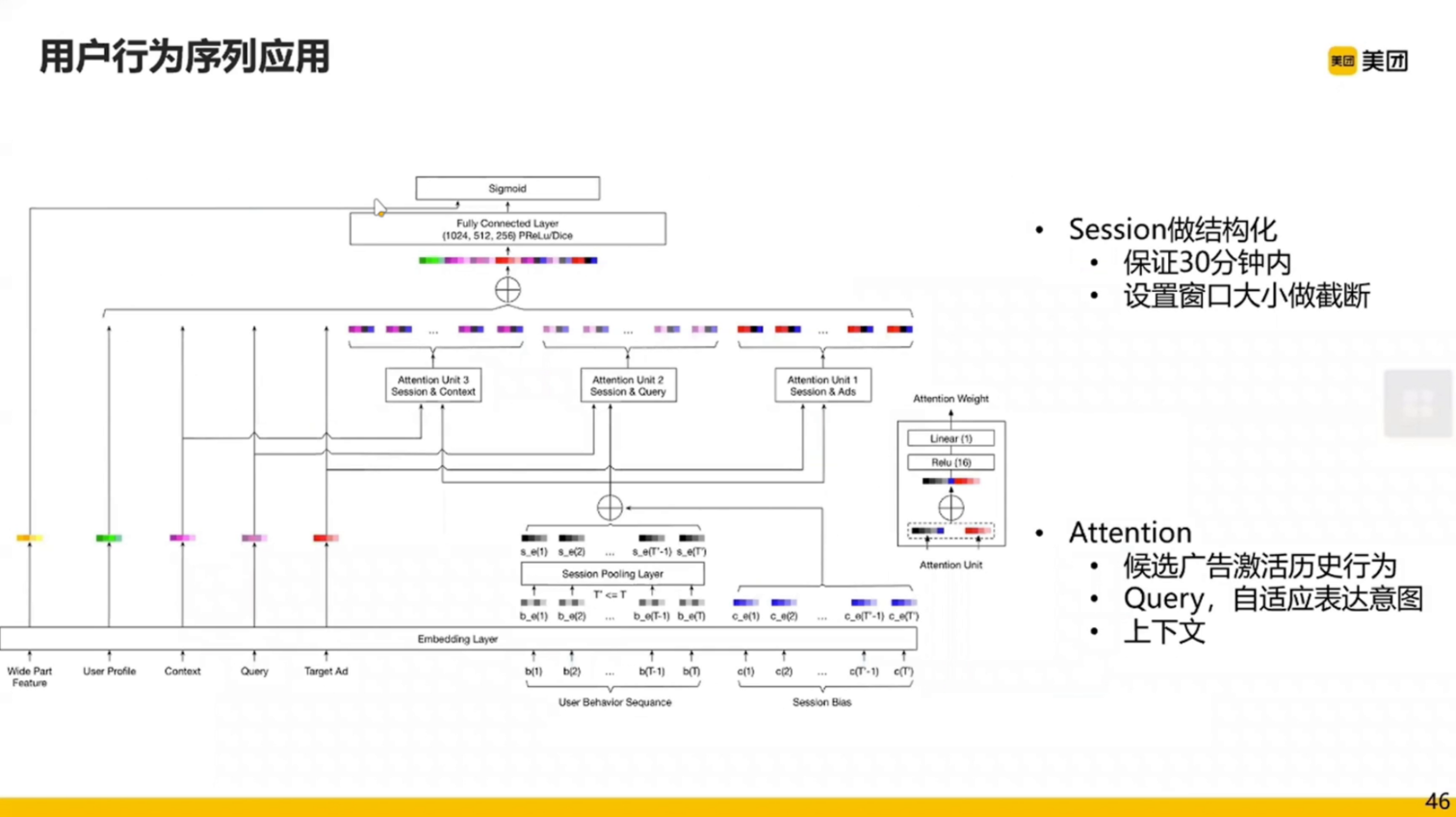
虽然看起来很复杂,但总体还是一个 Wide&Deep 模型。
整个模型中用户行为序列经过 embedding 后通过 Session Pooling Layer 得到编码向量,拼接之后和 Context、Query、Target Ad 分别进行 Attention 然后经过全连接层输出结果。
这样的模型真的有用吗?我们来看一个真实的例子。
上海的一个用户,有 7 个 Session。他先看了静安寺附近的美食潮州菜,点了一下五星级酒店,然后再东方国际广场看了生活服务中的家电维修,在江北区浏览了休闲娱乐的足疗,然后再黄浦区看了美食的日本菜,在宝山区看了休闲娱乐的洗浴汗蒸,最后在黄浦区人民广场看了美食江浙菜。
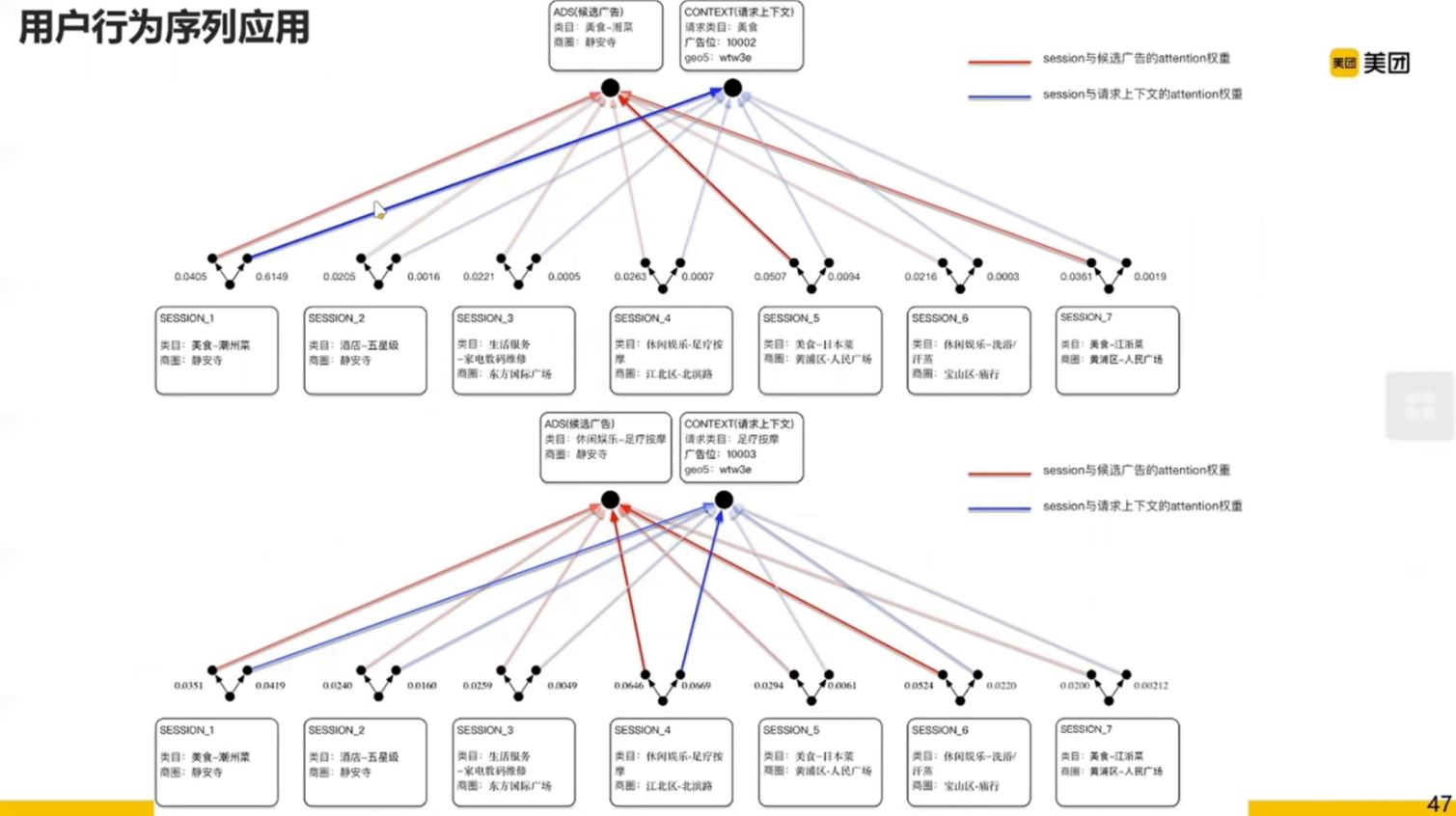
假设现在用户进入了足疗按摩的页面,这时候会有相关的广告。那广告怎么和 Session 产生关系的呢?
我们看红蓝两条线,蓝线——是用户行为和请求上下文(足疗按摩)的关系;红线——是用户行为和候选广告的关系。其中的权重是通过 Attention 获得的,颜色越深,权重越大。
我们可以发现,和请求上下文颜色比较深的同样也和候选广告的颜色有比较大的相关性。
2.2 机制
机制设计是经济学和博弈论的一个领域,需要工程学来确定经济机制或激励措施,以实现预期目标,在战略环境中实现合理的行为。
广告的机制主要做什么呢?流量的分配和定价。
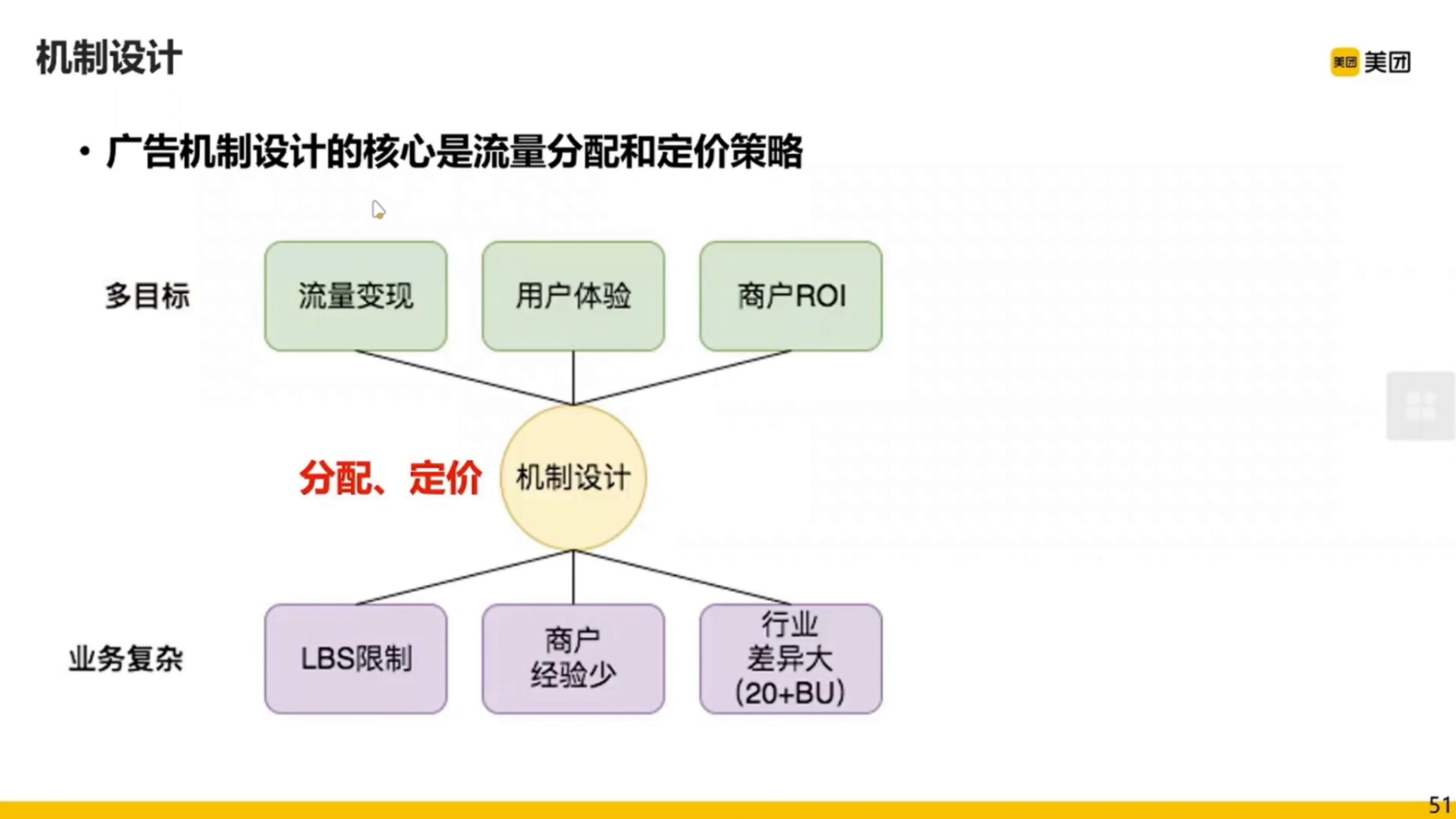
机制设计要平衡媒体收益、用户体验、广告主的投入产出比。
和广告相似的有关系就是拍卖机制。(提问:今年的经济学奖颁给了谁?研究课题是什么?)

竞价广告,是不是谁出价最高谁就能拍到广告?不是的,还要考虑点击率。搜索广告往往是 CPC 广告(收费是点击率 * 出价),如果出价很高但是点击率很差,那么这个广告就没有机会。
按照两个相乘的结果进行排序,收费按照第二位的 ECPM 进行收费。(为什么?防止恶性竞争,哄抬竞价)
(ECPM 是什么?effective cost per mile)


真实的排序公式远比下图复杂:
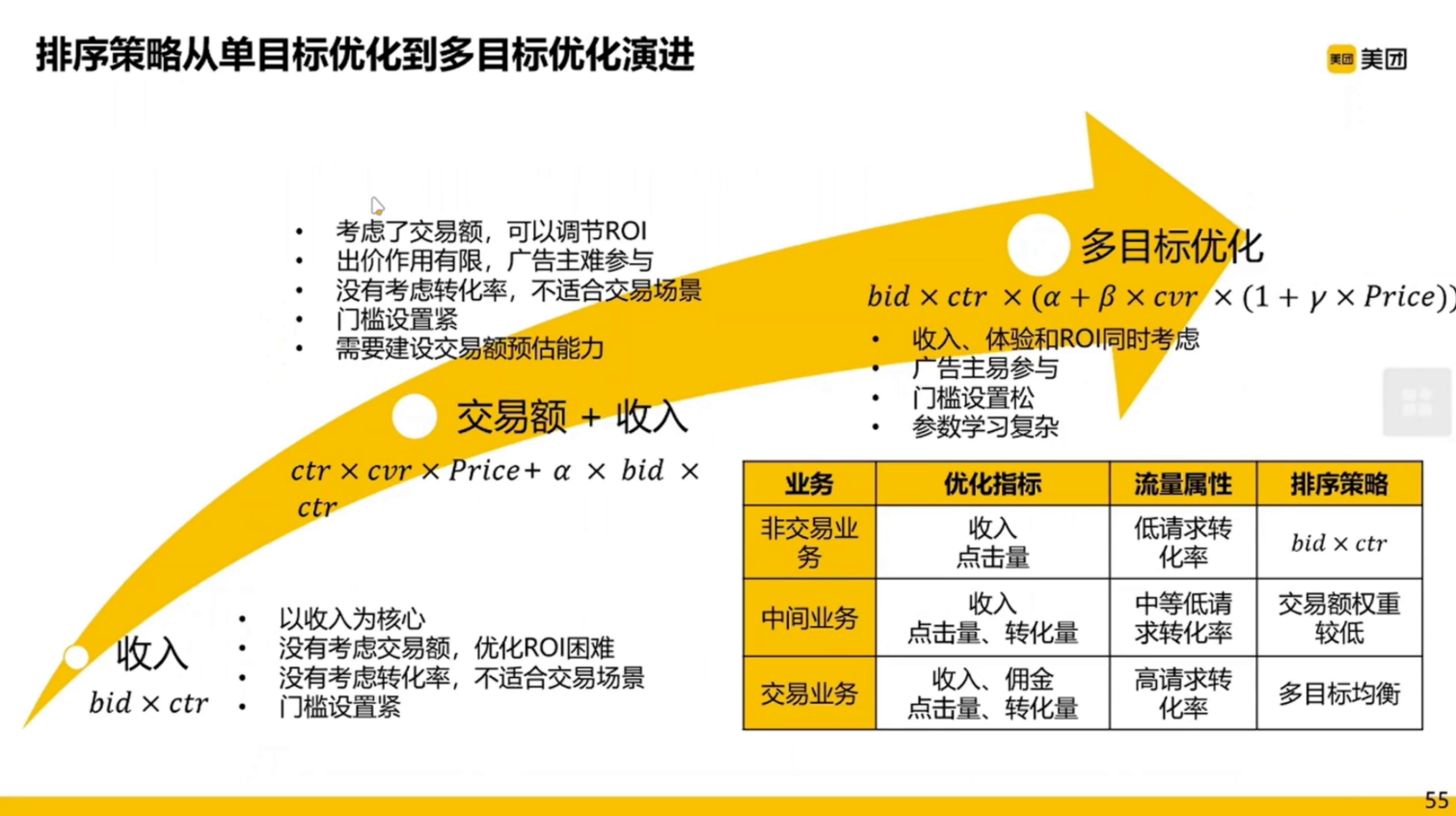
- $CTR * CVR $ :转化
- $BID * CTR $ :收入
机制要考虑这些参数如何去学,当然也可以通过强化学习等去学习。

相关链接:
- 美团:深入FFM原理与实践

















 2163
2163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









