







一、数据框计算
(一)基础运算函数
| 方法 | 描述 |
|---|---|
| add | 加(+) |
| sub | 减(-) |
| mul | 乘(*) |
| div | 除(/) |
| floordiv | 整除(//) |
| pow | 幂次方(**) |
(二)df之间计算
import pandas as pd
import numpy as np
df1=pd.DataFrame(np.ones((2,2)),columns=list("ab"))
df2=pd.DataFrame(np.ones((3,3)),columns=list("abc"))
#加法
df1+df2
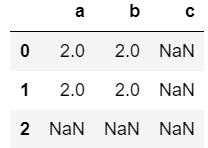
运算会对两个df的行列索引进行匹配,运算结果的索引取并集,非公共索引部分取NaN。
(三)df和series计算
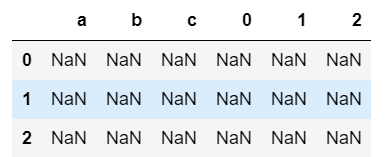
- df和series计算,默认将series的索引和df的列索引进行匹配,并且在行上进行广播。
#df和series计算,会广播
s=df2.iloc[:,0]
s+df2
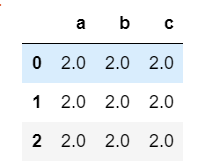
#df和series计算,会广播
s2=df2.iloc[0,:]
s2+df2
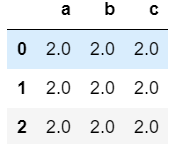
- 通过改变参数可以改变广播方式
#在行上匹配,在列上广播
df2.add(s,axis="index")
注意:使用算术符号(例如“+”),无法指定广播机制等。
(四)显性函数运算
df1.add(other, axis='columns', level=None, fill_value=None)
- other 另一个数据
- axis df和series默认列上匹配,行上广播
- fill_value 可指定填充运算结果为NaN的值
二、函数的映射
(一)df.apply函数
1.功能
将函数作用在行/列上,并沿着列/行“广播”。
2.参数
df1.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
- func 指函数名,可以是自定义函数也可以是系统函数;
- axis=0 参数为0时表示在行上使用函数,并在列的方向上广播。
3.例子
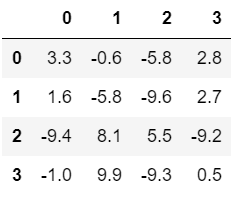
求每行的最大值
df1=pd.DataFrame(np.random.uniform(-10,10,size=(4,4)))
#
0 1 2 3
0 3.341642 -0.575784 -5.848210 2.755888
1 1.593945 -5.830961 -9.627209 2.675590
2 -9.399005 8.067327 5.500567 -9.225596
3 -0.994930 9.895505 -9.301169 0.520210
df1.apply(max,axis=1)
#
0 3.341642
1 2.675590
2 8.067327
3 9.895505
dtype: float64
4.df.applymap函数
tips 内置函数一般均可指定作用在列上或行上(默认axis=0,沿着0轴作用,作用效果为列)
df1.min(axis=1)
↑取每一行的最小值
a) 功能
将函数应用到每个数字上。
b) 参数
df1.applymap(func)
c) 例子
def fun(x):
return round(x,ndigits=1)
df1.applymap(fun)
三、排序
(一)按索引排序
困了~ 参数与下一节类似
df2.sort_index(axis=0,level=None,ascending=True,inplace=False,kind='quicksort',na_position='last',sort_remaining=True,ignore_index: bool = False)
(二)按数据排序
df1.sort_values(by,axis=0,ascending=True,inplace=False,kind='quicksort',na_position='last',ignore_index=False)
1.参数
- by 参数为字符串或字符串列表(行或列标签),表示以对应的行/列作为排序依据,当by为字符串列表,排序依据按字符串中标签的先后顺序;
- axis 沿0轴进行排序,即通常的对行排序;
- ascending 升序(依据为数字大小或asicc)
- ingore_index index跟随数据移动,若为True则对排序后的数据重新0,1,2…n-1,进行reindex。
2.例子
- 数据
df2=pd.DataFrame 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5845
5845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









