









【预训练语言模型】RoBERTa: A Robustly Optimized BERT Pretraining Approach
作者发现BERT以及提供的预训练语言模型并没有得到充分的训练,因此本文提出RoBERTa以挖掘BERT模型,并提供充分的训练。作者认为,扩增训练语料、增大预训练的迭代次数、去掉Next Sentence Prediction、在更长的序列上训练、动态Masking等策略(Trick)可以大幅度提升BERT的性能。
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | RoBERTa |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 预训练语言模型 |
| 4 | 核心内容 | BERT改进 |
| 5 | GitHub源码 | https://github.com/pytorch/fairseq |
| 6 | 论文PDF | https://arxiv.org/pdf/1907.11692.pdf |
一、动机
- 现有的基于self-training的语言模型(例如ELMo、GPT、BERT等)方法虽然达到了SOTA,但是很难判断那个部分对效果具有很大的促进作用。同时预训练成本很高,使用的provate data限制了模型扩展;
- 我们发现BERT预训练模型并没有得到充分的训练,语义挖掘能力还有一定提升空间;
二、背景——BERT模型及实验设置
可直接参考BERT讲解。
三、RoBERTa——Robustly optimized BERT approach
3.1 More Data
BERT只用了Wikipedia和BookCorpus,RoBERTa又额外扩增了训练语料。RoBERTa一共在5个语料上训练,包括Wikipedia、BookCorpus、CC-News、OpenWebText和Stories。后续的实验均在这5个语料上完成。
3.2 Dynamic Making Strategy
Masked Language Modeling是BERT中非常重要的预训练目标,但是,在BERT训练过程中,带有随机Mask的语料是数据预处理阶段得到的,而在训练过程中则固定不变(Static Masking)。因此BERT在训练时,对于每一个句子,每次都将见到相同Mask。
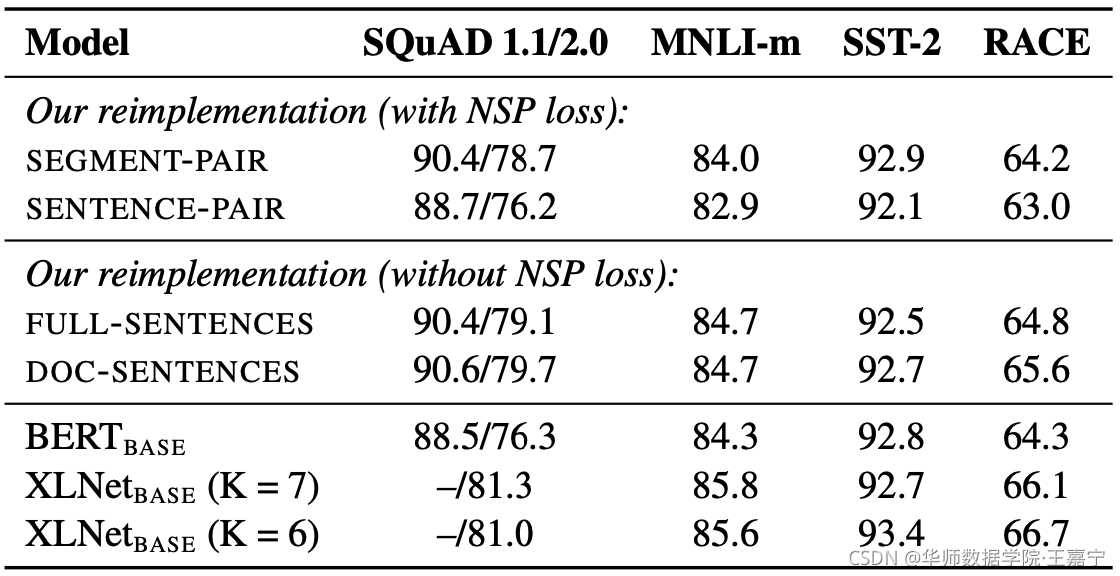
因此RoBERTa提出动态地改变每次训练时Mask采样位置(Dynamic Masking)。即每迭代一次训练,重新对每个句子的Mask进行采样。该策略间接实现了数据增强,且提高了鲁棒性。通过改变Mask策略,在QA、NLI以及分类任务上有提升:

3.3 The necessary of NSP?
Next Sentence Prediction(NSP)通常对sentence-pair的输入进行训练,目标是预测两个句子是否存在前后关系。但RoBERTa发现去掉NSP效果反而更好:
3.4 Larger Batch Size
在BERT中,batch size设置为256,一个epoch需要训练超过1M步。RoBERTa训练过程中,增大了batch size。如下表:

不同的batch size以及对应的学习率。实验发现当batch size为2k时,效果可以达到最好。batch size设置大可以采用数据并行方法进行训练。
3.5 Text Encoding——BPE
Byte-Pair Encoding(BPE)由Neural Machine Translation of Rare Words with Subword Units提出解决在机器翻译领域中出现的Out-of- Vocabulary(OOV)问题。主要通过wordpiece技术将word分解为更为细粒度的片段。RoBERTa采用BPE,获得了超过5w个token(BERT只有3w)。
BPE的详解可参考:BPE(Byte Pair Encoding)算法
四、实验
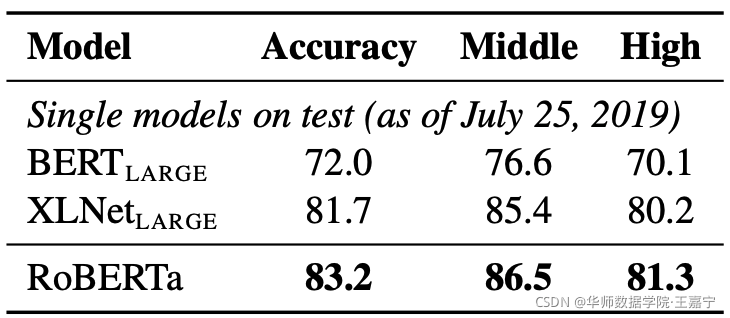
RoBERTa参与了SQuAD、RACE和GLUE的打榜,并与当时最好的模型XLNet进行比对,结果如下:
SQuAD
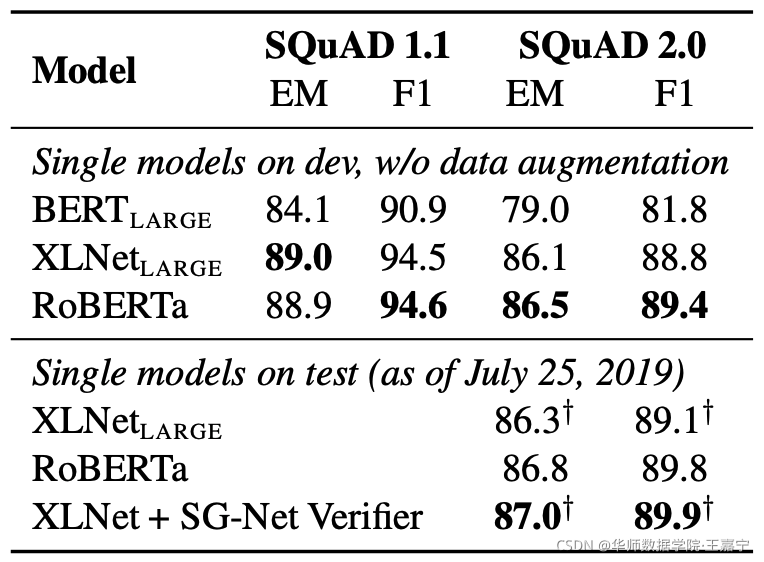
其中SG-Net是一个抽取式问答的模型,博主做过论文解读,可参考:机器阅读理解算法集锦
RACE
GLUE




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











