







目录
前言
最近在工作中用到了一些关于排序损失的知识,在此记录一下细节部分,方便日后查询,也希望能够帮助到有同样需求的人。
RankNet Loss
RankNet Loss 最初是由微软提出,并成功应用于 Bing 搜索的一项发明。对于用户搜索时输入的一个 query,在资料库中会有许多的 item 与其相对应,或者说是相关,那么如何设计一种学习算法能够将与用户查询的 query 相关的结果按照期望的顺序输出,就显得至关重要。
RankNet Loss 是从属于 pair-wise 的一种损失函数,它考虑两两 item 之间的排序结果,并期望与当前 query 相关性更高的 item 排在靠前的位置。对于搜索获得的两条结果 和
,模型对应输出的得分为
和
,得分越高的结果应该放在更靠前的位置进行展示。在已有的标注数据中,我们是已知在当前 query 下,
和
的相对顺序的,这里我们引入一个指示函数来表明二者的相对顺序:
上式中的不等号代表的是期望的相关性程度关系,并无数值上的含义。不妨令 为待训练的一个神经网络,其中
为网络的输入;
为网络的参数;
为用户输入的查询条件;
是网络的输出,也就是条目
的相关性得分。这样,对于
和
,我们可以获得对应的得分
和
,引入一个辅助变量(对上述的
稍加修改即可),来表示我们期望的顺序:
可以看出,,根据
的形式,就能够比较容易的想到构造交叉熵损失函数了,这就是 RankNet Loss 的思想。用
来表示
排在
前面的概率,可以通过用
函数来映射排序结果得到该值,即:
上述等式中的不等号代表的是排序,不是数值上的意义。进一步的,根据交叉熵损失函数,我们期望 与
,也就是期望的排序标签结果相一致。得到的损失函数具有以下形式:
通过最小化上述损失函数,可以获得一个通常情况下都表现不错的排序系统。更进一步的,有:
将 函数带入到 RankNet Loss 中,化简可以得到以下结果:
网络的输出为 和
,用损失函数对网络输出求偏导数,得到以下结果:
上述公式中定义的 在后续的改进中会用到,我们提前求解出来,另外,这里的
代表的损失函数中,针对于
的特定一项。值得说明的是,这里的
就是后续文章 LambdaRank 以及 LambdaMART 中的 Lambda。
LambdaRank
根据之前对RankNet的说明,可以看出,RankNet Loss并没有涉及到明显的优化指标,也就是说RankNet Loss并不是针对于一些衡量指标来设计的,而是期望减小逆序对的数量,使得两两有序。在大多数情况下,RankNet Loss表现是足够好的,但是有一种情形它并不能很好的解决,那就是Top K的问题。
对于搜索引擎来讲,显示在第一页的搜索结果是至关重要的,因为这些结果会被最先展示给用户。如果说每页我们显示K条相关的搜索结果,那么Top K条给到用户的信息就需要被额外重视。传统的RankNet Loss的缺陷此时就暴露出来了,它追求的是更少的逆序对数量,也就是整体的损失情况,而很多实际的应用中,我们往往只关心最前面的几条结果。这就是LambdaRank的出发点。
为了帮助大家更直观的理解上述内容,我们举一个简单的例子,也是在推荐系统中经常使用到的:
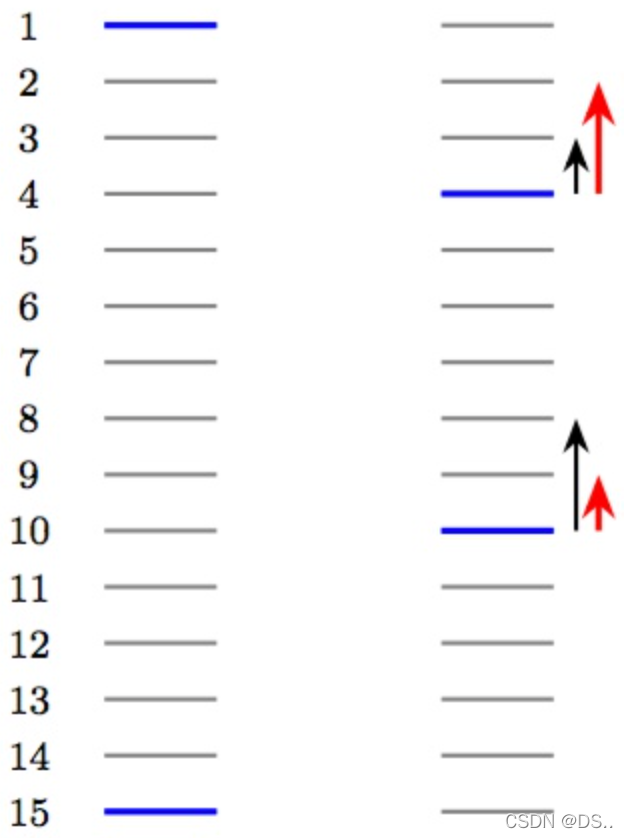
在上面的示意图中,每条线代表一个搜索结果,左侧的数字代表结果放置的位置。蓝色线条代表与当前用户键入的query相关性更高的一些items,灰色线条代表一些不太重要的items。例如,你输入“新能源汽车”进行搜索的时候,蓝色线条就相当于是“特斯拉”,而灰色线条就相当于是“汽车轮胎制造商”。首先我们数一下左右两种排序的逆序对有多少,这里,只要灰色线条排在蓝色线条之前,就可以构成一组逆序对。在左侧的排序结果中,逆序对一共有13组。这时,如果我们将最上侧的结果下移,同时将最下侧的结果上移,得到右侧的排序结果,可以看到逆序对的组数为11组,对应的RankNet Loss降低了。但是,我们并不希望右侧的这种情况出现,试想一下,当你输入“午餐好去处”进行搜索,但是反馈给你的前几条结果全都是“服装推销”的时候,你的心情一定糟糕透了。这就是RankNet Loss的存在的一种潜在缺陷,虽然很多时候这种缺陷并不会明显的被察觉到,但是我们还是要对此做一些修正,这就是LambdaRank期望完成的,它更像是一种补丁,对RankNet进行完善。
经过上面的介绍,相信大家已经理解了RankNet以及它可能存在的一些风险,并且在我们的脑海中也建立起了一种思想,那就是越靠前的结果必须要给予重视,而不仅仅关注全局的损失。为了衡量这种位置重要性,这里介绍一种常用的指标,DCG(Discounted Cumulative Gain) 。
假设有一个长度为的搜索结果表,每个结果与query的相关性记为
,那么这个搜索结果表的DCG得分可以通过以下的方法计算得来:
上式中的表示排在第
个位置的结果与当前query的相关性。可以看出,越靠后的结果(也就是
越大的位置)会被除以一个越大的数值,从而,越靠后的结果,得分衰减的越多;越靠前的结果,得分衰减的越少。显然,当排序结果是按照相关性得分降序排列的时候,我们可以得到数值最大的一个DCG,此时,它被称为IDCG(Ideal DCG),是DCG指标的上限。
但是直接用该指标来衡量排序结果还存在一个问题,那就是指标受到结果长度的影响,也就是越大,往往会有更大的DCG。为了解决这个问题,需要对DCG进行归一化,归一化的结果就是NDCG(Normalized DCG),其表达形式如下:
此时,该指标就可以用于不同的query,不同的items排序结果之间的比较了。由于这是一个列表长度无关的指标,因此我们没有标记下标。借助于NDCG,我们给予了靠前的位置更多的关注,如果我们的算法在设计的过程中能够优化NDCG,那么我们就能得到一个符合期望的系统排序结果。
回忆一下RankNet Loss,第条结果和第
条结果形成的损失对网络输出的得分
的梯度为:
根据我们就确定了如何更新网络的输出
与
。同时,正如之前所说,我们要给予前面的位置更多的关注,也就是说,如果交换第
条结果和第
条结果能够使得我们期望的指标大幅度提升,那么我们就加速这一交换过程;相反的,如果交换第
条结果和第
条结果带来的指标提升不明显,那么我们就不去过多关注该交换。
你可能要问,这种交换虽然符合常理,但是为什么就有着强调Top K的作用效果呢?我们还是看本章开始的示意图。不妨使用NDCG作为我们的衡量指标,在右侧的示意图中,交换上侧的蓝色线条与其前面的灰色线条的位置会使得NDCG大幅上升,而交换下侧的蓝色线条与其上的灰色线条带来的NDCG提升就不那么明显,因此,在更新时,我们期望上侧的蓝色线条抓紧向上移动,同时下侧的蓝色线条也要向上移动,但可以稍微放缓一下速度。图中的红色箭头代表了两者的更新方向和梯度大小。这样,我们就可以获得LambdaRank的更新方式了:
上式中的代表交换两个位置的结果带来的指标变化,这种指标可以是NDCG也可以是其他的依据实际任务设计的指标。可以看出,LambdaRank是在RankNet Loss的基础上修正了梯度的更新强度,并没有改变梯度的方向。这是一种比较经验化的修正方式,由于它是直接定义了梯度,因此避免了去处理指标不连续不可导等问题。
LambdaMART
To Do

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









