







摘要:
提出文本对抗攻击semantically equivalent adversaries (SEAs) ,生成能让语义不变同时改变模型预测结果的对抗样本
提出语义等价对抗规则semantically equivalent adversarial rules (SEARs),这是一种能在很多实例上实行的简单而通用的规则,按照规则寻找并替代生成对抗样本。规则由已有对抗样本泛化得来。
生成的对抗样本可以帮助人们发现NLP模型bug,并且可以通过对抗训练修复模型漏洞
算法:
Semantically Equivalent Adversaries语义等价对抗
While there are various ways of scoring semantic similarity between pairs of texts based on embeddings (Le and Mikolov, 2014; Wieting and Gimpel, 2017), they do not explicitly penalize unnatural sen- tences, and generating sentences requires surrounding context (Le and Mikolov, 2014) or training a separate model.We turn instead to paraphrasing based on neural machine translation (Lapata et al., 2017), where P(x?|x) (the probability of a paraphrase x? given original sentence x) is propor- tional to translating x into multiple pivot languages and then taking the score of back-translating the translations into the original language. This ap- proach scores semantics and “plausibility” simulta- neously (as translation models have “built in” lan- guage models) and allows for easy paraphrase gen- eration, by linearly combining the paths of each back-decoder when back-translating.
Unfortunately, given source sentences x and z,P(x'|x) is not comparable to P(z'|z), as each has a different normalization constant, and heavily de- pends on the shape of the distribution around x or z. If there are multiple perfect paraphrases near x, they will all share probability mass, while if there is a paraphrase much better than the rest near z, it will have a higher score than the ones near x, even if the paraphrase quality is the same. We thus de- fine the semantic score S(x, x') as a ratio between the probability of a paraphrase and the probability of the sentence itself:
虽然有各种各样的基于embedding的方式来度量文本对之间的相似性(Le和Mikolov,2014;Wieting和Gimpel,2017),但它们没有明确惩罚不自然的语句,生成句子需要环绕上下文(Le和Mikolov,2014)或训练一个单独的模型。
所以我们更倾向于基于神经机器翻译的释义[1](Lapata et al.,2017),其中P(x'|x) (给定原文(x),释义x'的概率,将x翻译成多种中心语言,然后将译文反译成原文。这种方法同时对语义和“合理性”进行评分(因为翻译模型具有“内置”语言模型),并允许在反翻译时通过线性组合每个反译码器的路径来进行简单的释义生成。
不幸的是,给定源语句x和z,P(x'|x) 与P(z'|z)不可比吗? ,因为每个都有不同的正则化常数,并且高度依赖x或z的分布。如果x附近有多个完美的释义,它们都会共享概率质量,而如果z有一个比z附近的其他词好得多的话,它的分数也会比x附近的分数高,即使是在解释中质量是一样的。因此,我们用复述的概率与句子本身的概率之间的比率作为语义分数S(x,x'):
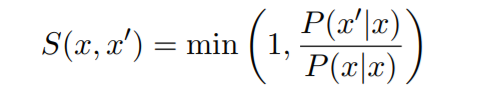
![]() 如果x和x'的相似性分数大于某个阈值τ称x与x'语义等价
如果x和x'的相似性分数大于某个阈值τ称x与x'语义等价
通过beam search找到x附近的释义集∏x并用黑箱模型预测∏x,直到找到对抗样本或S(x,x')< τ.
Semantically Equivalent Adversarial Rules (SEARs)语义等价对抗规则

1.通过exact matching找出规则
选择将x转换为x'的最小连续序列,(What→Which)在示例中。这种变化可能并不总是语义保持,因此我们还提出了进一步的规则,包括直接上下文(关联序列的上一个和/或下一个单词),例如(what color→which color)。然而,添加这样的上下文可能会使规则变得非常具体,从而限制其价值。为了便于泛化,我们还用原始文本与粗粒度和细粒度词性标记的乘积来表示所提出规则的一部分,如果这些标记与先行标记匹配,则允许这些标记按顺序发生。在运行s实例中,将提出(What color→Which color)、(What NOUN→Which NOUN)、(WP color→Which color)等规则。
2.过滤部分不好的规则
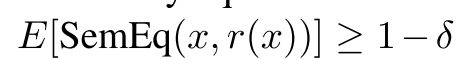 该规则产生的样本的语义等价性均值<1-δ,则删除该规则
该规则产生的样本的语义等价性均值<1-δ,则删除该规则
3.利用该规则产生的对抗样本越多相似度越大则优先级越高
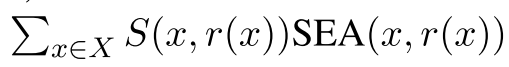
4.去除冗余规则
规则集中的不同规则可能导致相同的对抗样本,也可能导致不同的的对抗样本。理想的情况是集合应该覆盖验证中尽可能多的实例,而不是专注于一小部分脆弱的预测。此外,规则不应重复。在图4(中)中,r1是覆盖r2的超集,使r2
完全冗余,因此不应包括在R中。
覆盖问题,其中规则r覆盖实例x,如果SEA(x,r(x)),则连接的权重由S(x,r(x))给出。因此,我们希望找到一组语义等价的规则:
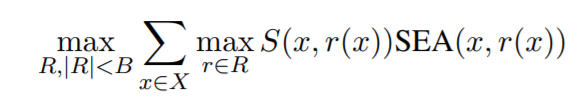
虽然公式(3)是NP难的,但目标是monotone submodular(Krause和Golovin,2014),因此迭代添加规则的贪婪算法,具有最高的边际增益,可为系统提供1−1/e的恒定因子近似保证最佳。这是算法1中的SubMod过程,如图4所示,其中输出是一组给定给人类的规则,人类判断他们是否真的是bug。

实验:
代码见 https: //github.com/marcotcr/sears
从Eu- roParl, news, and other sources (Tiedemann, 2012) 获取一百万个句子对
训练对抗样本的释义模型[1](paraphrasing model)用的是OpenNMT- py [2]中英语与葡萄牙和英语与法语的互译,参数为默认参数
用spacy library做词性标注
对规则集的生成设置δ = 0.1 (at least 90% equivalence), τ = 0.0008
For VQA, we use the multiple choice telling system and dataset of Zhu et al. (2016), using their implementation, with default parameters. The training data consists of questions that begin with “What”, “Where”, “When”, “Who”, “Why”, and “How”. The task is multiple choice, with four pos- sible answers per instance.
For sentiment analy- sis, we train a fastText (Joulin et al., 2016) model with unigrams and bigrams (embedding size of 50) on RottenTomato movie reviews (Pang and Lee, 2005), and evaluate it on IMDB sentence-sized reviews (Kotzias et al., 2015), simulating the com- mon case where a model trained on a public dataset is applied to new data from a similar domain.
5.2
[1]Mirella Lapata, Rico Sennrich, and Jonathan Mallinson. 2017. Paraphrasing revisited with neural machine translation. In European Chapter of the ACL (EACL).
[2]Guillaume Klein, Yoon Kim, Yuntian Deng, Jean Senel- lart, and Alexander M. Rush. 2017. Opennmt: Open-source toolkit for neural machine translation. In Annual Meeting of the Association for Computa- tional Linguistics (ACL).















 3125
3125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









