







 本文概述了深度学习模型在自然语言处理中面临的对抗攻击问题,特别是文本处理中的对抗训练。对抗训练是一种提升模型对抗攻击鲁棒性的方法,通过在训练中加入对抗样本来增强模型的防御能力。文章介绍了对抗训练的基本定义、对抗扰动的特征和产生方法,以及对抗攻击的分类。实验部分展示了对抗训练在文本分类和鲁棒性方面的效果提升。
本文概述了深度学习模型在自然语言处理中面临的对抗攻击问题,特别是文本处理中的对抗训练。对抗训练是一种提升模型对抗攻击鲁棒性的方法,通过在训练中加入对抗样本来增强模型的防御能力。文章介绍了对抗训练的基本定义、对抗扰动的特征和产生方法,以及对抗攻击的分类。实验部分展示了对抗训练在文本分类和鲁棒性方面的效果提升。

作者丨WenZe、Leo
单位丨追一科技AI Lab研究员
背景与研究意义
深度学习技术的快速发展,大幅提升了众多自然语言处理任务(比如文本分类,机器翻译等)的效果,越来越多的深度学习模型被用于现实生活中。但是深度学习模型本质上的黑箱属性,也为实际应用带来了潜在的风险。
早在 2014 年,Szegedy et al. [1] 发现只要对深度学习模型的输入添加一些微小的扰动就能轻易改变模型的预测结果。后续的研究将该种扰动称之为对抗扰动,扰动后的输入称为对抗样本,将输入对抗样本误导模型的这一过程称为对抗攻击。深度学习模型遭遇对抗攻击时所表现出的脆弱性,给实际应用带来了极大的风险。自然语言处理的应用比如文本分类、情感分类、问答系统、推荐系统等也都受到了对抗攻击的威胁 [2]。
在上述背景下,已经有大量的研究集中于提升深度学习模型对于对抗攻击的鲁棒性(也称为对抗防御),其中对抗训练是其中的主要方法之一。本文对文本处理中的对抗训练进行初步的梳理和总结。
本文接下来先介绍对抗训练及其相关概念的基本定义,这一部分重点阐述的对抗扰动的基本特征及对应产生扰动的基本方法,由于对抗训练最早开始于图像处理中,其在图像领域中的进展也领先于文本,因此本文第三部分结合其在图像处理领域的研究进展,详细介绍了对抗攻击的基本类型与代表方法,然后简单介绍我们最近在文本分类和鲁棒性上做的实践,最后进行总结。
基本定义与概念
本章节介绍对抗训练 [3] 及相应的基本概念,此段内容主要源于文献 [2]。对抗训练指的是在模型的训练过程中构建对抗样本并将对抗样本和原始样本混合一起训练模型的方法,换句话说就是在模型训练的过程中对模型进行对抗攻击从而提升模型对于对抗攻击的鲁棒性(也称为防御能力)。可以说不同的对抗攻击方式决定了不同的对抗训练方法。因此文本中的不同对抗攻击方式是本文阐述的重点,简单的对抗攻击示列如图 1。

▲ 图1. 简单的对抗攻击示列(图片来自https://zhuanlan.zhihu.com/p/37260275)
如图 1 所示(左图为原始样本,中间为添加的对抗扰动,右图为构造的对抗样本),可以看出在加入对抗扰动后原始的图片被误判(雪山变识别成了狗,河豚被识别成了螃蟹),但是人眼并不能够明显发现原图和对抗样本的差异,更不会产生如此离谱的判断。
可以看出对抗攻击指的是在模型原始输入上添加对抗扰动构建对抗样本从而使模型产生错误判断的过程。而在这一过程中,对抗扰动的选择和产生是关键。对抗扰动指的是在模型输入上添加能够误导模型输出的微小变动(图 1 中间部分)。
虽然不同的文章对于对抗扰动的定义略有不同,但是一般来说对抗扰动具有两个特点:
1. 扰动是微小的甚至是肉眼难以观测到的(图 1 中间部分);
2. 添加的扰动必须有能力使得模型产生错误的输出(图 1 右侧部分)。
为了满足上述特点,已有大量研究集中于如何产生有效的对抗扰动。不同于图像领域,连续值的扰动直接添加到原始输入矩阵中,在文本处理中添加的扰动可以是离散的也可以是连续的,一般来说离散扰动指的是直接对输入文本字符进行微小修改(如图 2),连续扰动一般指的是直接在输入文本中的词向量矩阵中添加的扰动 [4]。文本处理中的离散扰动示列如图 2:
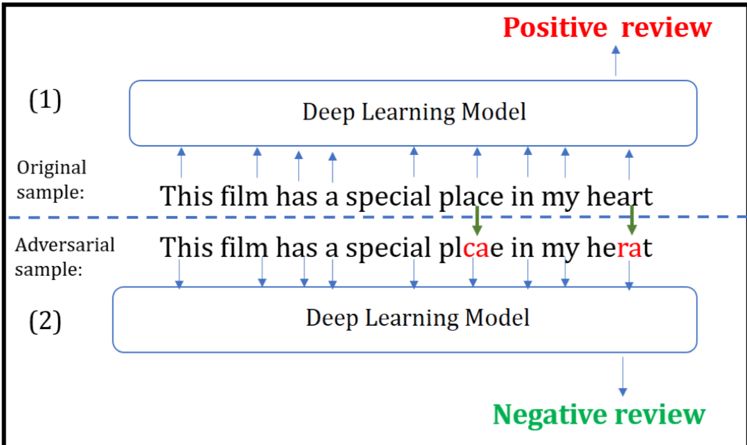
▲ 图2. 文本处理中的离散扰动示列(图片来自于[5])
如图 2 所示,part1 指的是原始的输入文本,part2 指的是对原始数据进行离散扰动后的文本,虽然只有少量字符被修改但是模型产生了完全不同的输出。
在文本处理中,对抗扰动的特征 1 要求添加扰动后产生的对抗样本与原样本在语义上保持一致,即添加的扰动应该尽量不改变原始句子的语义。因此,需要一个测度来衡量扰动前后文本的差异。下面简单介绍一些在相关文献中已经存在的测度方式(主要参考自
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









