







(一)先聊聊AtomicLong的基本概念,然后聊一下他的缺陷问题,然后引出LongAdder的优点
(1)大家都使用过AtomicInteger、AtomicLong等这几类原子性的工具类,具体怎么用我就不说了,就说一下他们的大概的基本实现原理

- 其实这些基本的原子操作的思想大体都是,
expect 表示当前内存中你所预期望的值,update 是你想要更新的值
public final boolean compareAndSet(long expect, long update) {
这个this表示了当前对象的地址,后面的valueOffset是在该对象开始的位置加上这个valueOffset的偏移量,就能拿到的是当前对象的值
return unsafe.compareAndSwapLong(this, valueOffset, expect, update);
}
- 然后这里又会去调用unsafe对象的native方法,这个是基于C写的代码
把上面的compareAndSwapLong的入参和这个对应起来,然后其实就是判断当前位置的值,是不是和你预期的expect的值相等,如果相等就把valueOffset处的值更新为update你想要更新的结果,
如果失败的话,就不做改变(说明这个值跟你期望的不一致,就意味着这个值被别的线程修改过了,就什么也不操作)
public final native boolean compareAndSwapLong(Object var1,
long var2,
long var4,
long var6);
(2)这样带来的缺点就是,如果有大量的线程进行CAS的时候,那么就会导致大量的线程都在进行CAS,但是能够成功的又很少,那么就会出现有大量线程进行自旋,并且对CPU造成大量的资源消耗的缺点,所以这个时候就进行了优化,那么就出现了LongAdder
- 但是如果要是在并发度不是很高的情况下,其实使用LongAdder和AtomicLong的差别不大
- 尽量减少热点冲突,不到最后万不得已,尽量将CAS操作延迟
(二)先说一下LongAdder的整体设计思想
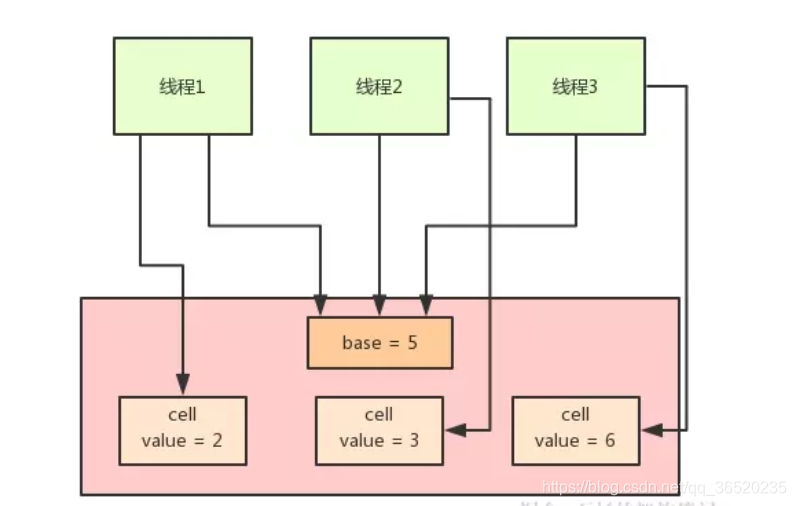
(1)其实整体的设计思想就是:如果在如果有很多个线程来进行CAS的时候,而在LongAdder中他其实是借鉴的了HashMap1.7的思想,他把这个资源进行分段来进行维护,他内部维护了一个Cell[]数组,每个Cell对象中就包含了资源的值,其实就是和HashMap中的那个table数组,table数组中放的都是包含key-value的一个Node对象
(2)然后在竞争激烈的时候就直接怼base值进行增加,但是如果当线程竞争足够激烈的时候就会统计每个线程对应的Cell[这个是每个线程的hash出来的一个下标值]进行相加
value=base+∑i=0nCell[i]
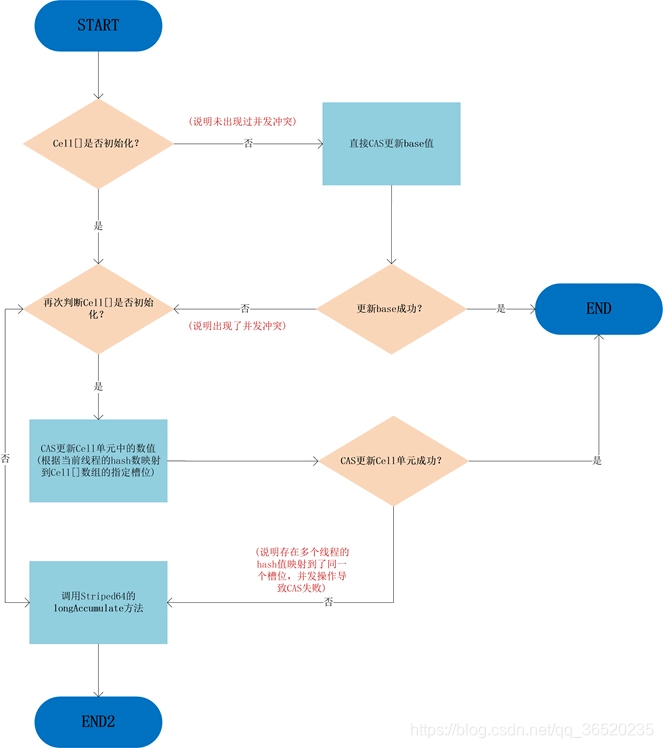
(3)主要的Add方法
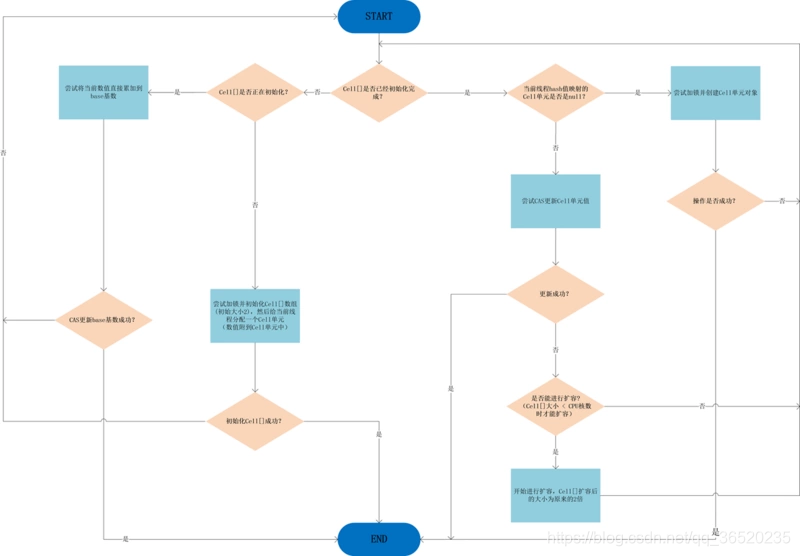
(4)如果
参考:https://segmentfault.com/a/1190000015865714#articleHeader4














 1934
1934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









