






前景提要
公司最近有个从mysql迁移数据到oracle的需求,于是进行了一下方案调研和分析,但作为一个之前从没接触过Oracle的人真的感到好难,但再难也难上,这篇文章主要是记录一下做这件事时遇到的坑以及分享一下最终的方案及代码。
具体实现
创建数据库链接
其实我觉得这个算是最容易花时间的地方了,这个oracle链接是真的难创,sid和service_name真的把我玩死了。之前就是疯狂链接不上去,或者就连接到不对的库,反正无限报错。不过最后还是连上了,先放一个连接代码吧
ip = 'xxx.xx.xx.xx'
port = 'yyyy'
uname = 'userName'
pwd = 'passWord'
tnsname = 'orcl' # 实例名
dsnStr = cx_Oracle.makedsn(ip, port, sid=tnsname)
connect_str = "oracle://%s:%s@%s" % (uname, pwd, dsnStr)
engine = create_engine(connect_str, encoding='utf8')
其实上面最重要的就是这个tnsname,一开始不知道实例名究竟是啥意思
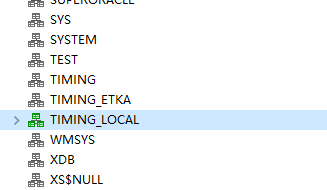
一直链接sql的人很容易认为这个TIMING_LOCAL就是实例名,然后写上去的结果就直接报错连不上,直接给我整蒙了,后来查了一下oracle的相关概念才知道,这个TIMING_LOCAL其实应该是用户名,大概就是用TIMING_LOCAL登录就会直接写到TIMING_LOCAL这个库下(或者叫做service_name),而sid则是通过这个语句查出来的
select instance_name from V$instance;
基本上绝大部分查出来的结果应该都是orcl

读取mysql数据
这一步没啥好说的,pandas.read_sql完事
写入orcale
这一步说实话,我一开始是用dataframe自带的to_sql,但是效率实在是太感人了,2000条数据给我足足跑了3分钟,要真用这方法我可能直接被老板fire了(不是),于是没办法,只能去学oracle的insert语句(此处对oracle的insert语句不做太多介绍,网上都是例子)。直接给一个将dataframe解析成oracle语句然后插入的函数吧(伸手党狂喜)
def to_oracle(tb_name, conn, dataframe, chunksize=1000, debug=False,):
"""
由于dataframe原生的to_sql插入oracle极其缓慢,因此重写了一个可以直接将dataframe插入oracle的函数
但是仅仅是插入语句,不支持sql中的on duplicated key update操作
Args:
tb_name: str
Table to insert get_data;
conn:
DBAPI Instance
dataframe: pandas.DataFrame
Dataframe instance
chunksize: int
Size of records to be inserted each time;
**kwargs:
Returns:
if debug:
None
else:
oracle语句
"""
tb_name = ".".join(["\"" + x + "\"" for x in tb_name.split(".")])
df = dataframe.copy(deep=False)
#由于oralce中的timestamp类型的插入语句是to_date(xxx),因此需要改变
column_time_list=[]
if len(df):
index=1
for column in df.columns:
if type(df[column][0])==pd.Timestamp:
column_time_list.append(column)
index=index+1
else:
return
df = df.fillna("None")
df = df.applymap(lambda x: re.sub('([\'])', '\'\g<1>', str(x)))
cols_str = sql_cols(df)
sqls = []
for i in range(0, len(df), chunksize):
# print("chunk-{no}, size-{size}".format(no=str(i/chunksize), size=chunksize))
df_tmp = df[i: i + chunksize]
sql_base = "INSERT all INTO {tb_name} {cols}".format(
tb_name=tb_name,
cols=cols_str
)
sql_val = sql_cols(df_tmp, "format",column_list=column_time_list)
final_dict=format_sql(df_tmp.to_dict("records"),column_time_list)
# vals = tuple([sql_val % x for x in df_tmp.to_dict("records")])
vals=tuple([sql_val % x for x in final_dict])
sql_vals = "VALUES ({x})".format(x=vals[0])
for i in range(1, len(vals)):
sql_vals += " into {} {} VALUES ({})".format(tb_name,cols_str,vals[i])
sql_vals = sql_vals.replace("'None'", "NULL")
sql_main = sql_base + sql_vals+" select 1 from dual "
if sys.version_info.major == 2:
sql_main = sql_main.replace("u`", "`")
if sys.version_info.major == 3:
sql_main = sql_main.replace("%", "%%")
if debug is False:
try:
conn.execute(sql_main)
except pymysql.err.InternalError as e:
print("ENCOUNTERING ERROR: {e}, RETRYING".format(e=e))
time.sleep(10)
conn.execute(sql_main)
else:
sqls.append(sql_main)
if debug:
return sqls
def sql_cols(df, usage="sql",column_list=None):
cols = tuple(df.columns)
if usage == "sql":
cols_str = str(cols).replace("'", "\"")
if len(df.columns) == 1:
cols_str = cols_str[:-2] + ")" # to process dataframe with only one column
return cols_str
elif usage == "format":
if column_list:
if cols[0] in column_list:
base = "%%(%s)s" % cols[0]
else:
base = "'%%(%s)s'" % cols[0]
for col in cols[1:]:
if col in column_list:
base += ", %%(%s)s" % col
else:
base += ", '%%(%s)s'" % col
return base
else:
base = "'%%(%s)s'" % cols[0]
for col in cols[1:]:
base += ", '%%(%s)s'" % col
return base
elif usage == "values":
base = "`%s`=VALUES(`%s`)" % (cols[0], cols[0])
for col in cols[1:]:
base += ", `%s`=VALUES(`%s`)" % (col, col)
return base
def format_sql(x,column_x):
return_list=[]
for dict_x in x:
for column in dict_x.keys():
if column in column_x:
dict_x[column]="to_date('{}','yyyy-mm-dd hh24:mi:ss')".format(dict_x[column])
return_list.append(dict_x)
return return_list
其中debug参数如果是true就直接插入,不返回任何值,如果是True就直接返回insert语句(数组,根据chunksize来切分)
其他代码由于不适合公开的原因就没公开(所以这段代码有可能不能直接运行,我也没单独切出来运行过,如果有什么函数缺的欢迎私信我hhh)
结语
说实话,之前一直觉得oracle和mysql应该没啥区别,毕竟都是关系性数据库,但这次之后发现还是有点区别的,以后的工作也不知道会不会经常和oracle打交道(希望不要把hhh)















 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









