










Le LSTM古诗词生成
一、简介
基于LSTM的古诗词生成,设计神经网络模型,使模型学习数据是6291首古诗,没有专门的验证数据和测试数据,感觉不会预测正确。边学习边生成古诗,从生成的古诗来看学习的效果。
涉及到的模块有Pytorch、Dataset、word2vec、LSTM。
二、处理流程
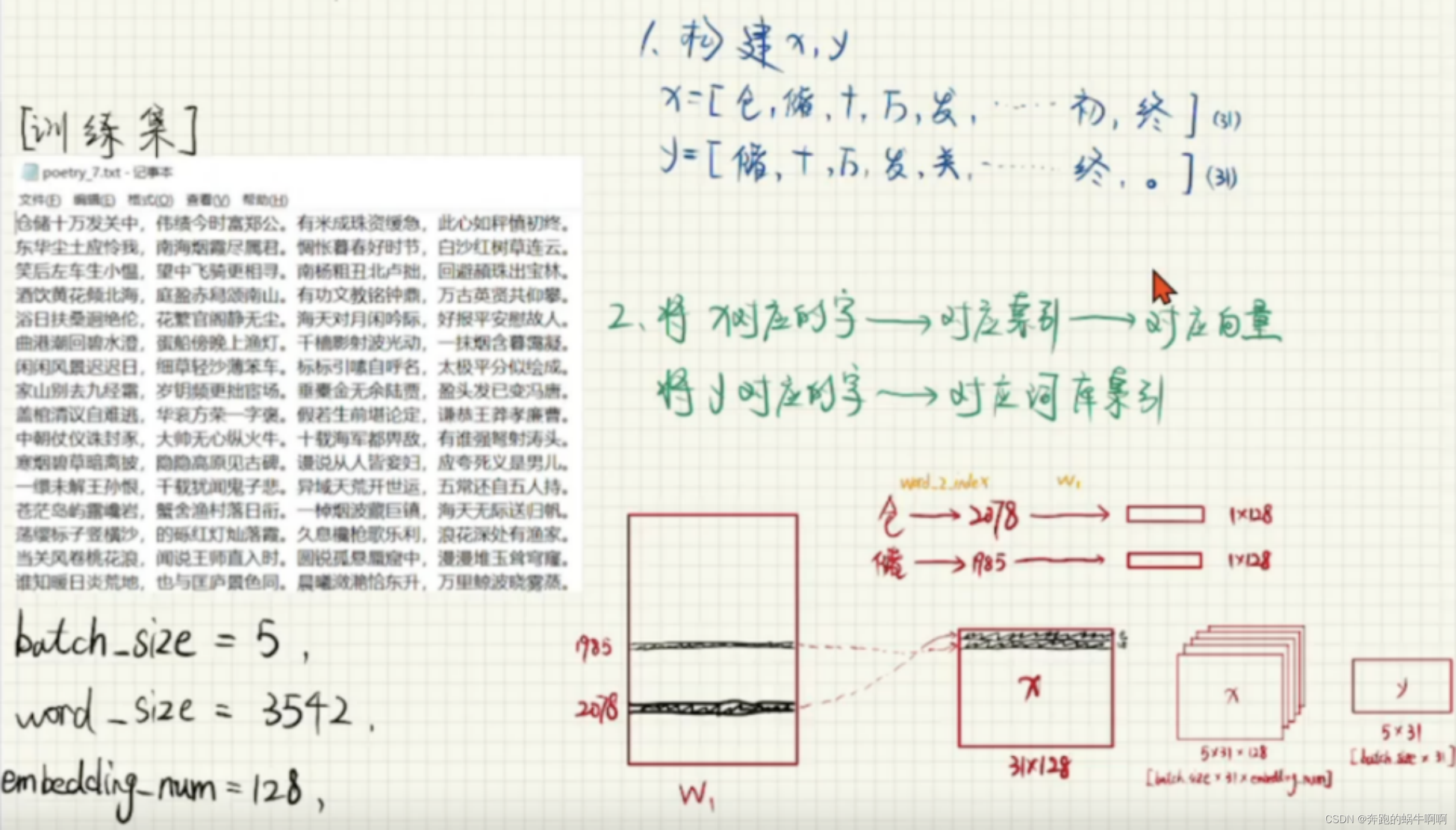
2.1字向量训练(Wordvec)
主要是把字、标点符号转换成向量,以使计算机认识,然后存储为pkl文件,以供后续训练时调用。
2.2封装数据(Dataset、DataLoader)
主要工作是将字向量进行提取、封装、打包,放在2.3的模型中去训练,承接连接2.1和2.3的工作。
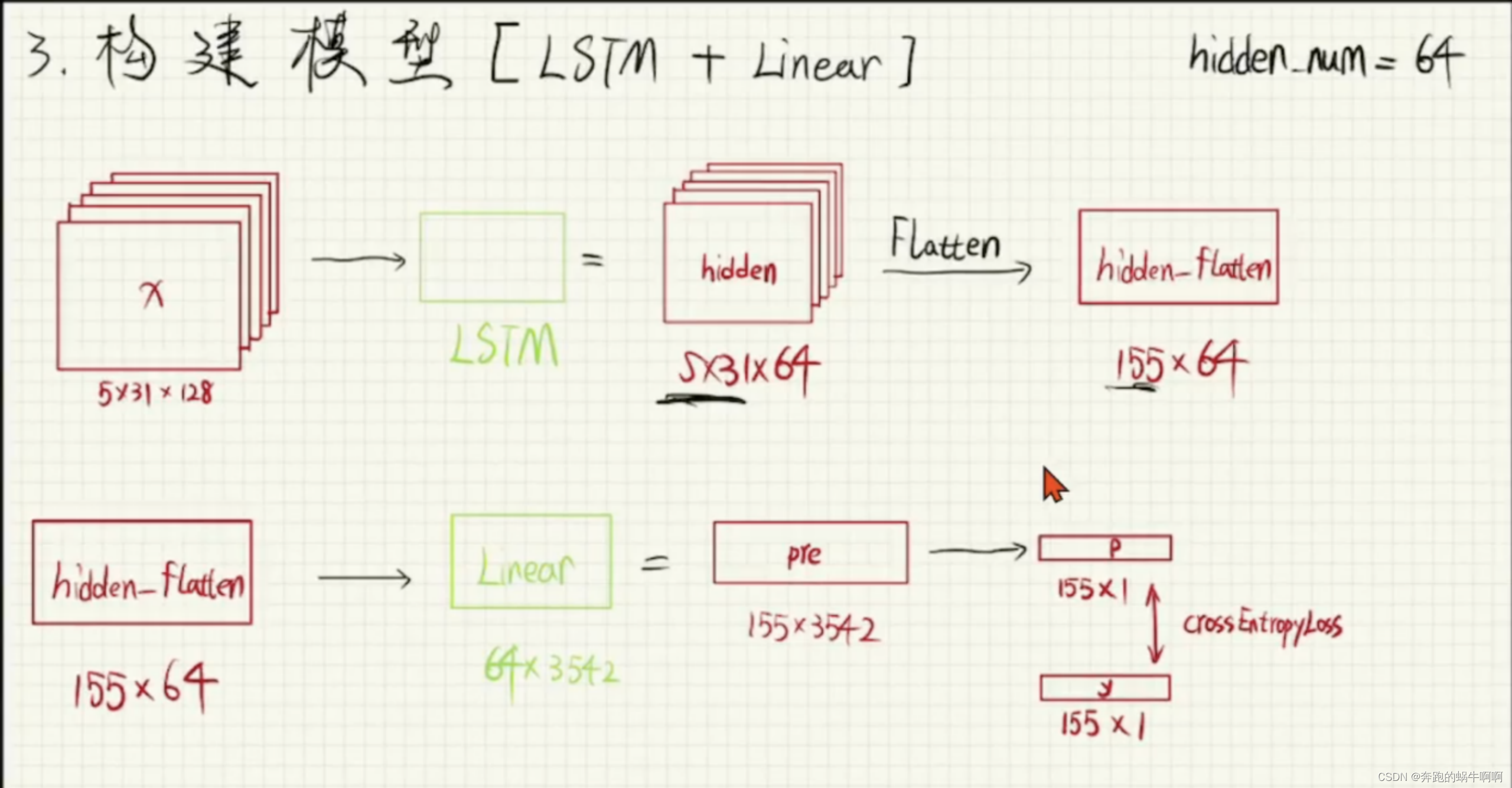
2.3组合模型 (LSTM+Linear)
我们使用的pytorch的一些函数。组合我们自己的模型,用到的有nn.LSTM、nn.Dropout、nn.Linear、nn.CrossEntropyLoss
2.4训练开始
设置一些超参数,调用已经处理为向量封装好的模型进行训练。超参数包含学习率,epoch轮次等。
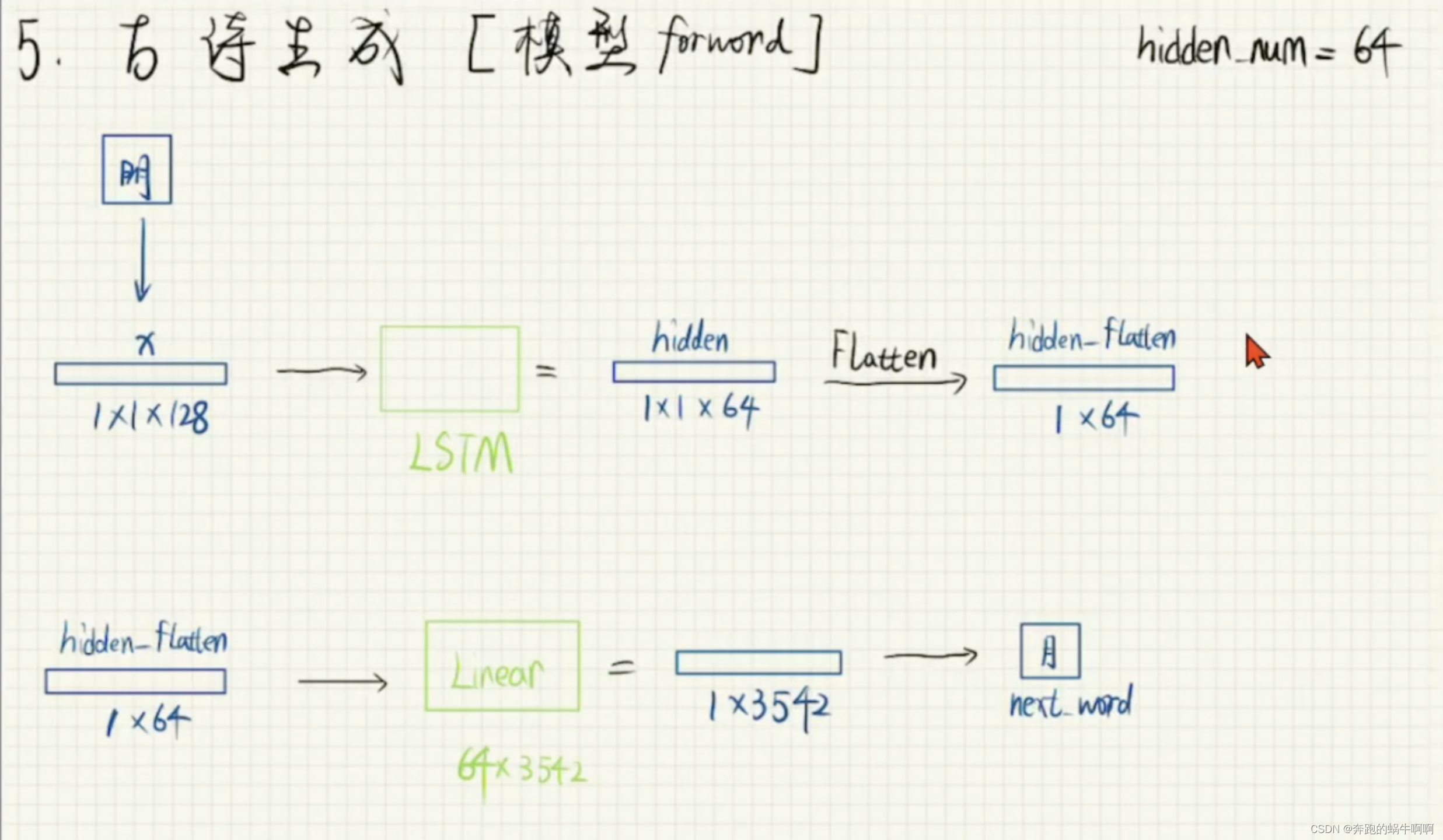
2.5生成古诗
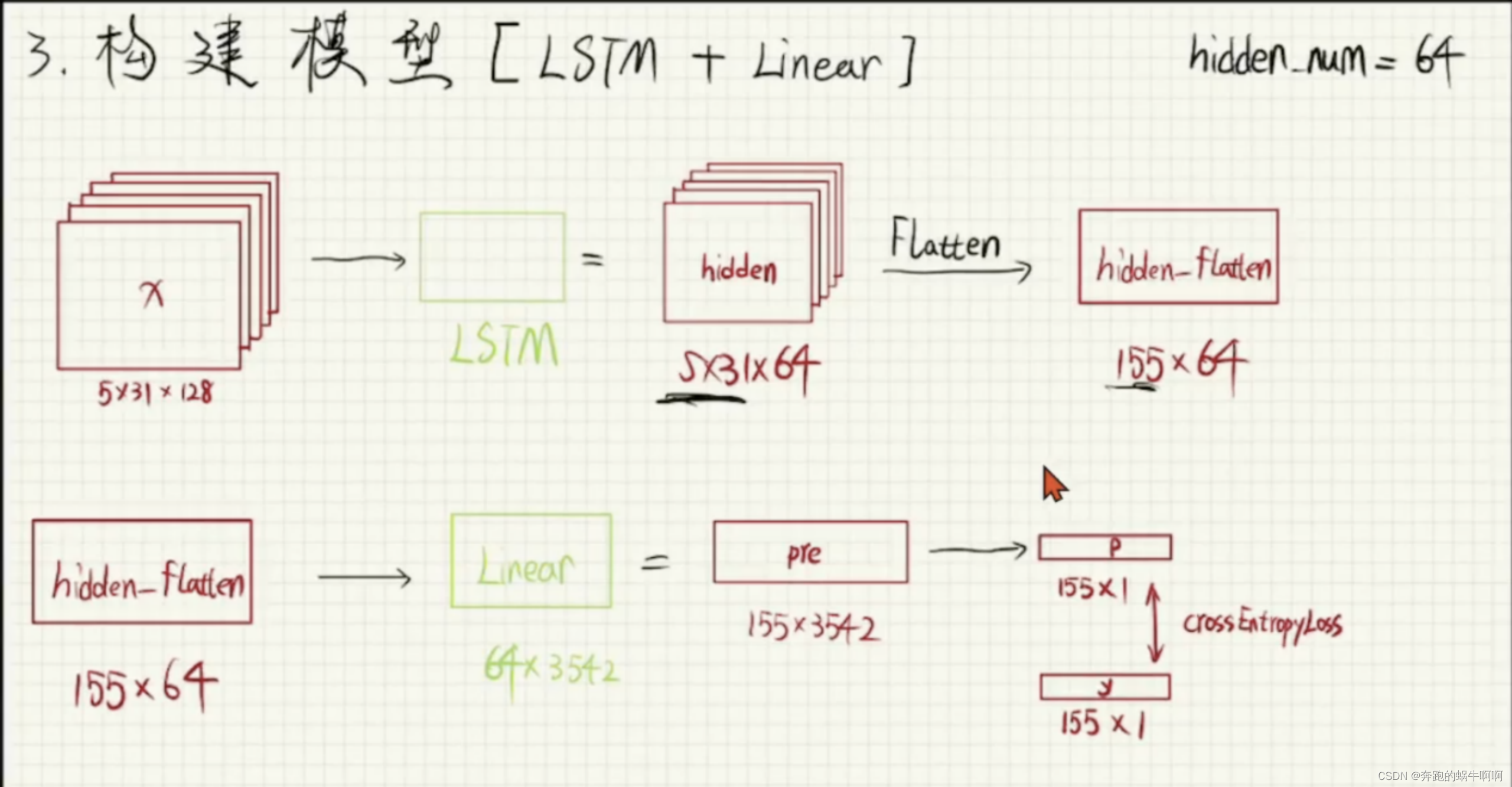
训练的时候想要看到训练的效果如何,在训练的时候就调用生成古诗函数,边训练边生成古诗,可以看到生成的古诗会越来越好。下图是古诗词生成的原理图。
三、代码实现
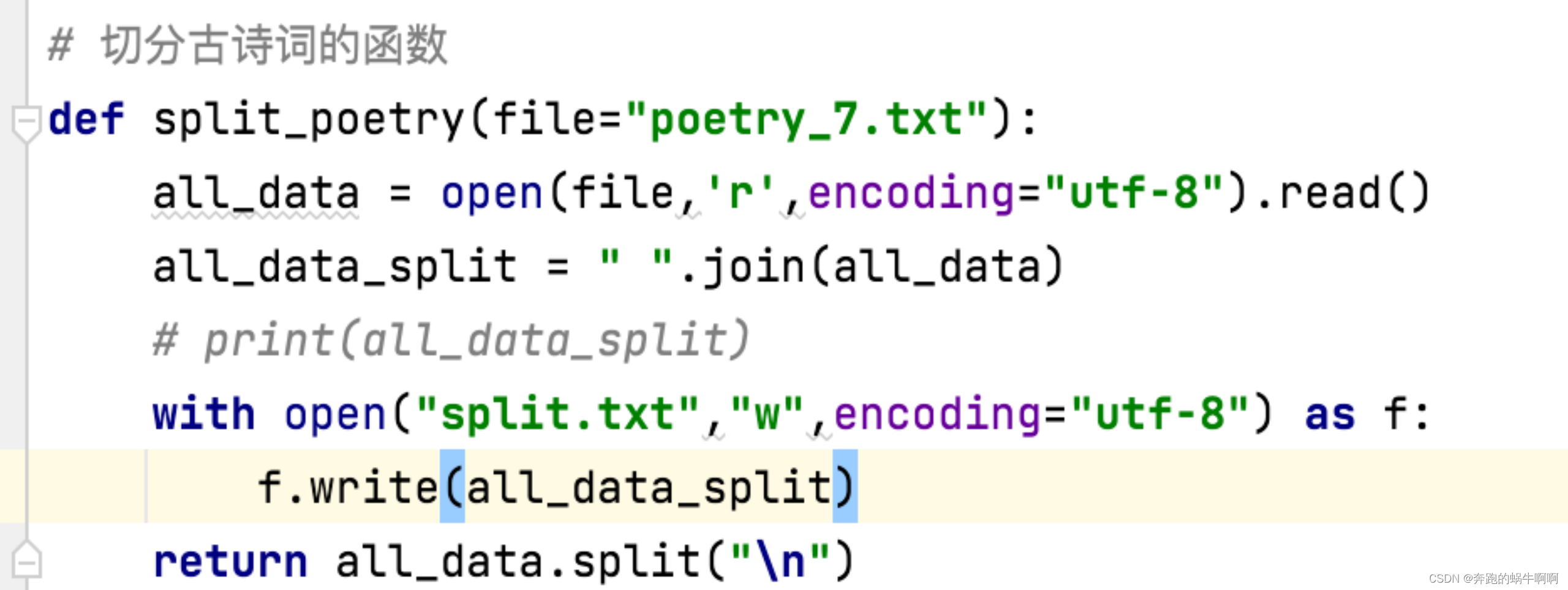
3.1 数据预处理
这部分主要对数据文件进行读取、预处理等,以符合训练数据的要求进行训练,处理后的文件保存为新文件。
以下是代码:
接下来是读取处理后的数据文件,把数据转换为向量,然后保存参数模型。
以下是代码:

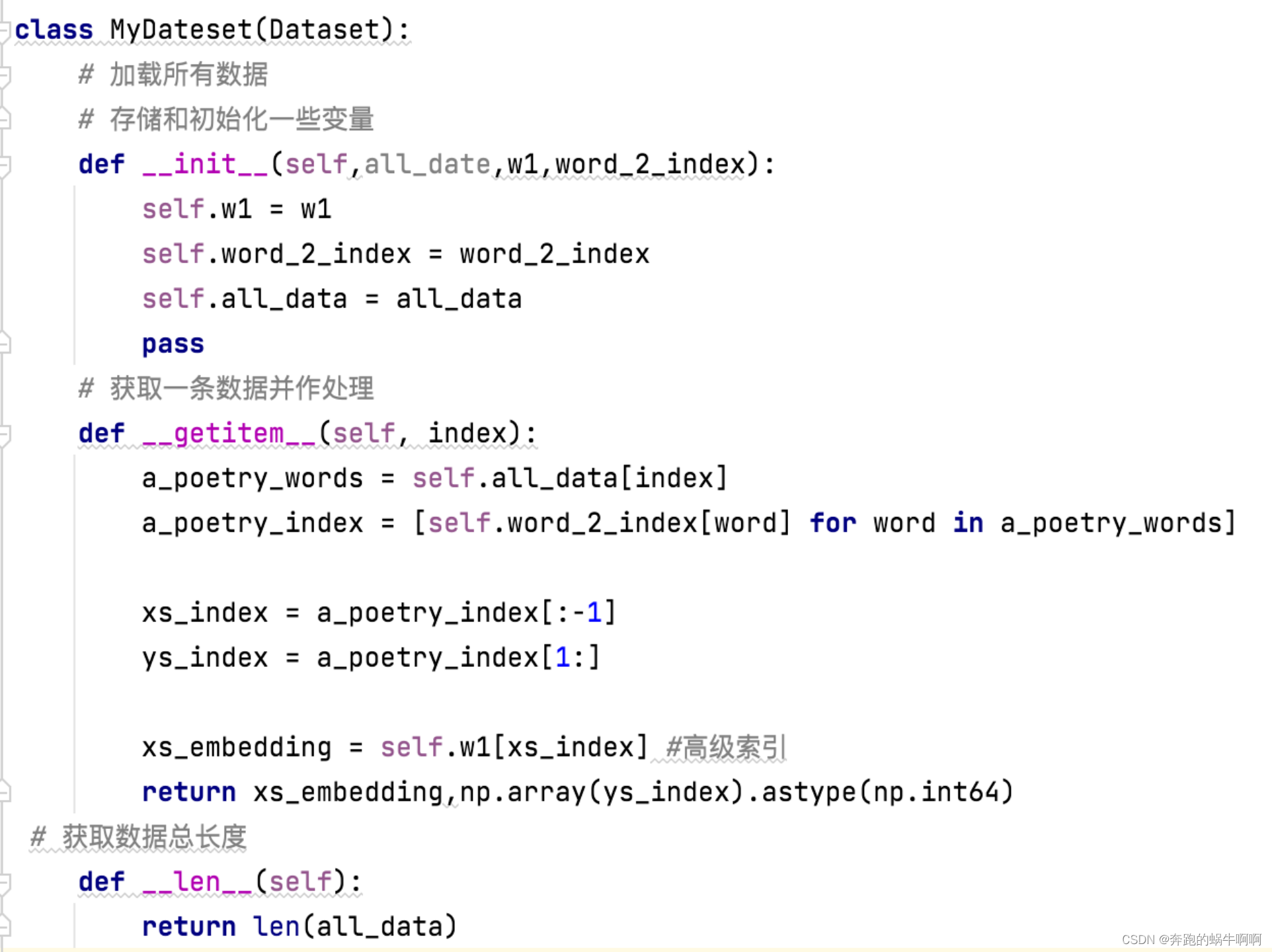
创建MyDataset类,继承Dataset类,重写三个函数,def init(),def getitem(),def len():。Getitem()函数主要是对向量数据进行处理操作,以符合生成古诗词模型时对数据的调用。
以下是代码:
3.2 创建网络模型
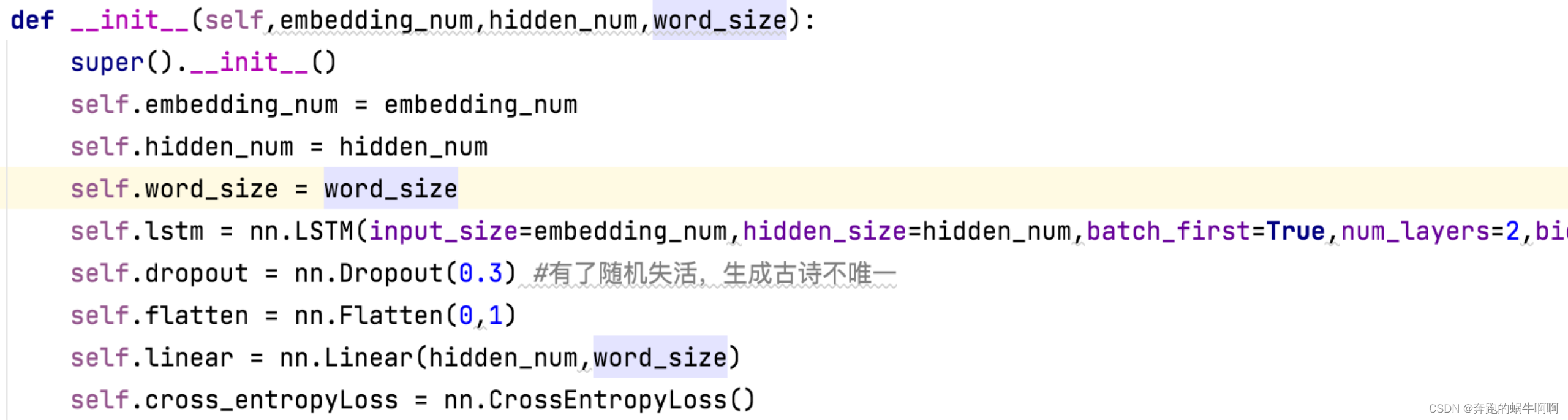
创建MyModel网络模型,继承nn.model。该类主要有三个函数,init()、forward()、to_train()。
Init()函数代码:
Forward()函数代码:

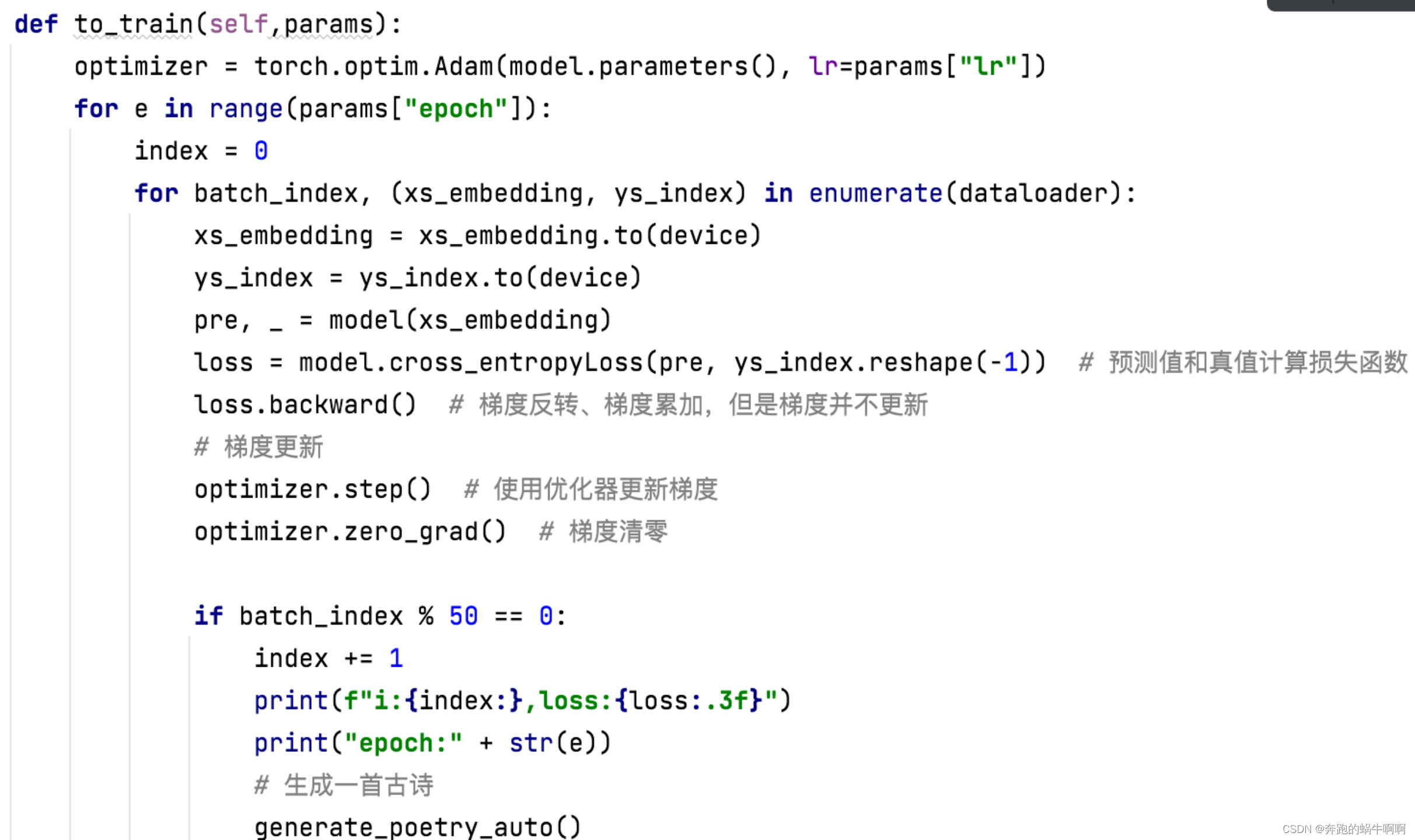
To_train()函数代码:
3.3、古诗词生成
这里先随机生成一个字,然后开始预测后边的字,选择概率最高的确定为下一个字,然后并以此为当前字继续预测下一个字,以此类推最终生成一首诗。

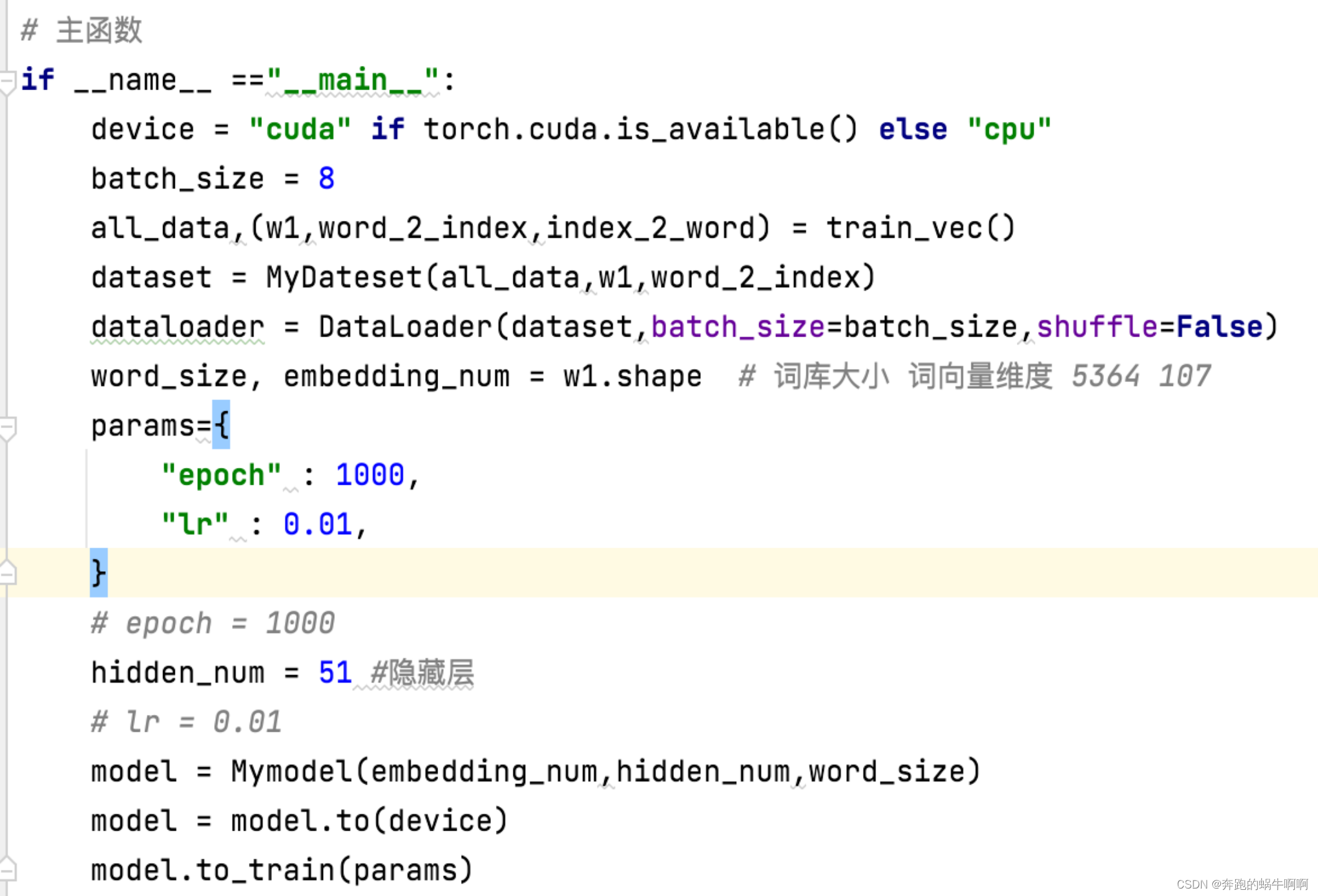
3.4、主函数
主函数主要是设置一些超参数(学习率、epoch轮次、batch_size、hidden_num)、创建数据类、创建神经网络模型并调用。
四、运行结果

可以看到已经经过训练,模型自己已经可以生成正确格式的诗句了,具体诗句的含义和押韵还有待提高
[1] 斋藤康毅.深度学习入门[M].人民邮电出版社,2018.
[2] https://www.bilibili.com/video/BV1G54y177iw?p=1

















 1899
1899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









