







学习目标
1.讲述文本生成模型的建立原理
2. 掌握如何调用已经生成好的模型来解决实际问题
理论原理
RNN具有图灵完备性,可以用来模拟生成某种程序。文本在自动生成时,需要考虑文本的上下文语义,在生成的时候需要避免“断章取义”。单纯用RNN来实现时,由于输入的文本序列较长,所以会很容易出现梯度爆炸导致无法进行反向转播,学习参数。所以我们加入了门控机制与记忆单元(LSTM)
LSTM的核心是细胞状态c来专门进行线性的转播,其中t时刻的细胞状态包含一个的t-1时刻的细胞状态,与进过非线性函数得到的候选状态,f,i分别为遗忘门与输入门,分别用来控制遗忘多少上一个细胞状态与输入多少本次的候选状态。
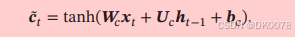
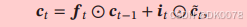
ht为t时刻将输出信息传出的状态,其计算过程为:
通过LSTM里的一个个这样的结构,他会学习到综合整个文本序列来对下一个词进行模拟。
一、模型的建立
将汉语文字进行向量化
打开我们准备好的古诗数据库lyrics.txt。发现数据库里的古诗并不是都可以用来进行模型的训练。
我们首先处理数据,删除包含较多字母的汉语诗
sentences = []
with open('../lyrics.txt', 'r', encoding='utf8') as fr:
lines = fr.readlines()
for line in lines:
line = line.strip()
count = 0
for c in line:
if (c >= 'a' and c <= 'z') or (c >= 'A' and c <= 'Z'):
count += 1
if count / len(line) < 0.1:
sentences.append(line)
print('共%d首歌' % len(sentences))
汉语的向量化与英文不同,我们通常是以文字为单位进行转化的。
chars = {
}
for sentence in sentences:
for c in sentence:
chars[c] = chars.get(c, 0) + 1
chars = sorted(chars.items(), key=lambda x:x[1], reverse=True)
chars = [char[0] for char in chars]
vocab_size = len(chars)
print('共%d个字'  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9203
9203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









