












代码实现
数据处理模块。data.py
# 导入所需要的包
import torch
import torch.utils.data as Dataset
#导入MIDI音乐处理的包
from mido import MidiFile,MidiTrack,Message
import numpy as np
# 读取音乐文件的函数
'''
读取文件函数,循环获取音乐问价你的音符、速度、间隔时间三个重要参数并保存
'''
def ReadMidi(file):
notes = []
#读入MIDI文件,并从消息序列中抽取音符、速度和间隔时间的三个序列
mid = MidiFile('./music/little_star.mid')
time = float(0)
prev = float(0)
original = [] #original 记载了原始的message数据 以便后面进行比较
# print(mid)
#对MIDI文件中的所有消息进行循环
for msg in mid:
#时间的单位是秒 而不是帧
time += msg.time
# print(msg.is_meta)
# 如果当前消息不是描述信息
if not msg.is_meta:
#仅提炼第一个channel的音符
if msg.channel == 0:
#如果当前音符是打开的
if msg.type == 'note_on':
#获得消息中的信息(编码在字节中)
note = msg.bytes()
# print(note)
# 我们仅对音符信息感兴趣。音符信息按如下形式记录[type、note、velocity]
# note[0]存音符(note) note[1]存速度(velocity) note[2]存距离上一个message的时间间隔
note = note[1:3]
note.append(time-prev)
prev = time
#将音符添加到列表notes中
notes.append(note)
#在原始列表中保留这些音符
original.append([i for i in note])
return notes
# 数据预处理函数
def data_processing():
notes = ReadMidi("")#调用读取数据函数 返回保存了音符和速度的信息
intervals = 10
values = np.array([i[2] for i in notes]) # i[2]存距离上一个message的时间间隔
max_t = np.amax(values) #区间中的最大值
min_t = np.amin(values) #区间中的最小值
interval = 1.0 *(max_t-min_t)/intervals
# print(intervals)
# 接下来,将每一个message编码成3个独热向量,将这3个向量合并到一起就构成了slot向量
dataset = []
for note in notes:
slot = np.zeros(89+128+12)
# dataset = []
#由于note介于24~112之间 因此减去24
ind1 = note[0] - 24
ind2 = note[1]
# 由于message中有大量time=0的情况,因此将0归为单独的一类,其他的一律按照区间划分
ind3 = int((note[2] - min_t)/intervals+1) if note[2]>0 else 0
slot[ind1] = 1
slot[89+ind2] = 1
slot[89+128+ind3] = 1
# print(slot)
dataset.append(slot)
# print(dataset)
# print(notes)
# print(np.zeros(89+128+12).shape)
#生成训练集和校验集
X = []
Y = []
#首先按照预测的模式,将原始数据生成一对一的训练数据
n_prev = 30 #滑动窗口为30
#对数据中的所有数据进行循环
for i in range(len(dataset)-n_prev):
#往后取n_prev个note作为输入属性
x = dataset[i:i+n_prev]
# 将第n-prev+1个note(编码前)作为目标属性
y = notes[i+n_prev]
#注意time要转化成类别的形式
ind3 = int((y[2]-min_t)/intervals+1) if y[2]>0 else 0
y[2] = ind3
#将X和Y加入到数据集中
X.append(x)
Y.append(y)
# 将数据集中的前n_prev个音乐作为种子,用于生成音乐
seed = dataset[0:n_prev]
# 将所有数据顺序打乱重拍
idx = np.random.permutation(range(len(X)))
# print(idx)
# print(len(X))
# print(X)
# 形成训练与校验数据集列表
X = [X[i] for i in idx]
Y = [Y[i] for i in idx]
# 从中切分出1/10的数据放入校验集
validX = X[:len(X)//10]
X = X[len(X)//10:]
validY = Y[:len(Y)//10]
Y = Y[len(Y)//10:]
# 形成训练集
batch_size = 30
train_ds = Dataset.TensorDataset(torch.FloatTensor(np.array(X,dtype=float)),torch.LongTensor(np.array(Y)))
# 形成数据加载器
train_loader = Dataset.DataLoader(train_ds,batch_size=batch_size,shuffle=True,num_workers=4)
# print(len(train_loader.data))
# 校验数据
valid_ds = Dataset.TensorDataset(torch.FloatTensor(np.array(validX,dtype=float)),torch.LongTensor(np.array(validY)))
valid_loader = Dataset.DataLoader(valid_ds,batch_size=batch_size,shuffle=True,num_workers=4)
return train_loader,valid_loader,interval,seed,min_t
LSTM神经网络模块。LTSM.py
import torch
from torch import nn
from torch.autograd import Variable
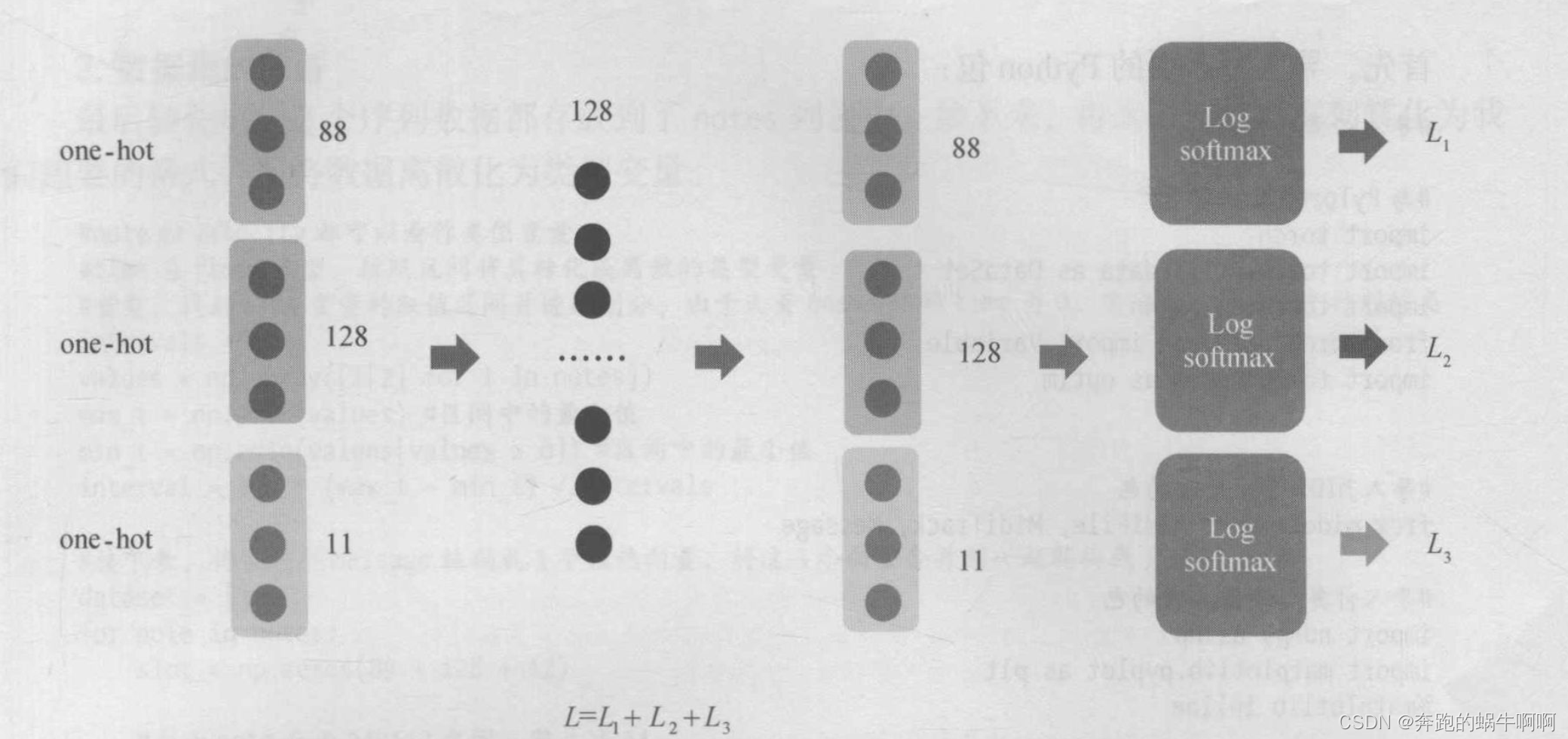
class LSTMNetwork(nn.Module):
def __init__(self,input_size,hidden_size,out_size,n_layers=1):
super(LSTMNetwork, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.out_size = out_size
#一层LSTM单元
self.lstm = nn.LSTM(input_size,hidden_size,n_layers,batch_first=True)
# 第一个Dropout部件,以0.2 的概率dropout
self.dropout = nn.Dropout(0.2)
# 建立一个全连接层
self.fc = nn.Linear(hidden_size,out_size)
# 对数Softmax层
# (1)dim = 0:对每一列的所有元素进行softmax运算,并使得每一列所有元素和为1。
# (2)dim = 1:对每一行的所有元素进行softmax运算,并使得每一行所有元素和为1。
self.softmax = nn.LogSoftmax(dim=1)
def forward(self,input,hidden=None):
# 神经网络的每一步运算
hhh1 = hidden[0] #读入隐含层的初始信息
# 完成一步LSTM运算
# input的尺寸为:batch_size,time_step,input_size
output,hhh1=self.lstm(input,hhh1) #input:batchsize*timestep*3
# 对神经元输出的结果进行dropout
output = self.dropout(output)
# 取出最后一个时刻的隐含层输出值
# output的尺寸为batch_size,time_step,hidden_size
output = output[:,-1,...] #降维 -1 的维度去掉
# 输入一个全连接层
out = self.fc(output)
# out的尺寸为:batch_size,output_size
# 将out的最后一个维度分割成3份x,y,z,分别对应了note,velocity以及time的预测
x = self.softmax(out[:,:89])
y = self.softmax(out[:,89:(89+128)])
z = self.softmax(out[:,(89+128):])
# print(x.size())
# print(y.size())
# print(z.size())
# print("55555")
# x的尺寸为batch_size,89
# y的尺寸为batch_size,128
# z的尺寸为batch_size,11
# 返回xyz
return (x,y,z)
def initHidden(self,batch_size):
# 将隐含层单元变量全部初始化为0
# 注意尺寸:layer_size,batch_size,hidden_size
out = []
hidden1 = Variable(torch.zeros(1,batch_size,self.hidden_size))
cell1 = Variable(torch.zeros(1,batch_size,self.hidden_size))
out.append((hidden1,cell1))
return out
# 我们特别定义了自己的损失函数
def critertion(outputs,target):
#为本模型自定义的损失函数,由3部分组成,每部分都是一个交叉熵损失函数
# 分别对应note、velocity time的交叉熵
# print(len(outputs))
# print(target)
# print(len(target))
x,y,z = outputs
# print(len(x))
# print(len(y))
# print(len(z))
# print(target[:,0])
# print(target[:, 1])
# print(target[:, 2])
loss_f = nn.NLLLoss()
loss1 = loss_f(x,target[:,0])
loss2 = loss_f(y,target[:,1])
loss3 = loss_f(z,target[:,2])
# print(loss1)
# print(loss2)
# print(loss3)
return loss1+loss2+loss3
def rightness(predictions,labels):
# 对于任意一行(一个样本)的输出值的第一个维度求最大,得到每一行最大元素的下标
pred = torch.max(predictions.data,1)[1]
# 将下标与labels中包含的类别进行比较,并累积得到比较正确的数量
rights = pred.eq(labels.data).sum()
return rights,len(labels)#返回正确的数量和这次一共比较了多少元素
训练模块。train.py
import matplotlib.pyplot as plt
import torch
from torch import optim
from torch.autograd import Variable
import numpy as np
from data import data_processing
from LSTM import LSTMNetwork,critertion,rightness
if __name__ == '__main__':
lstm = LSTMNetwork(89+128+12,128,89+128+12)
# print(lstm.parameters().__dir__())
optimizer = optim.Adam(lstm.parameters(),lr = 0.001)
num_epochs = 100
train_losses = []
valid_losses = []
records = []
#调用处理好的数据
train_loader,valid_loader,_,_,_ = data_processing()
#开始训练循环
for epoch in range(num_epochs):
train_loss = []
# 开始遍历加载器中的数据
for batch,data in enumerate(train_loader):
# batch为数字,表示已经进行了第几个batch
#data 为一个二元组,分别存储了一条数据记录的输入和便签
# 每个数组的第一个维度都是batch_size=30的数组
# print(len(train_loader))
lstm.train()#标志LSTM当前处于训练阶段,dropout开始起作用
init_hidden = lstm.initHidden(len(data[0])) #初始化LSTM的隐含单元变量
optimizer.zero_grad()#直接把模型的参数梯度设成0:
x,y = Variable(data[0]),Variable(data[1])
# x, y = data[0].clone().detach().requires_grad_(True), data[1].clone().detach() # 从数据中提炼出输入和输出对
outputs = lstm(x,init_hidden) #输入lstm,产生输出outputs
# print(outputs[0].size())
# print(outputs[1].size())
# print(outputs[2].size())
# print(outputs)
loss = critertion(outputs,y) #代入损失函数并产生loss
train_loss.append(loss.data.numpy()) #记录loss
loss.backward() #反向传播
optimizer.step() #更新梯度
if 0 == 0:
# 在校验集上运行一遍,并计算在校验集上的分类准确率
valid_loss = []
lstm.eval() #将模型标识为测试状态,关闭dropout的作用
rights = []
# 遍历加载器加载进来的每一个元素
for batch,data in enumerate(valid_loader):
init_hidden = lstm.initHidden(len(data[0]))
# 完成LSTM的计算
x,y = Variable(data[0]),Variable(data[1])
# x的尺寸:batch_szie,length_sequence,input_size
# y的尺寸,batch_size,(data_dimension1=89+data_dimension2=128+data_dimension3=12)
outputs = lstm(x,init_hidden)
# outpus:(batch_size*89,batch_size*128,batch_size*11)
loss = critertion(outputs,y)
valid_loss.append(loss.data.numpy())
# 计算每个指标的分类准确度
right1 = rightness(outputs[0],y[:,0])
right2 = rightness(outputs[1],y[:,1])
right3 = rightness(outputs[2], y[:,2])
rights.append((right1[0]+right2[0]+right3[0])*1.0/(right1[1]+right2[1]+right3[1]))
#打印结果
print('第{}轮,训练Loss:{:.2f},校验Loss:{:.2f},校验准确度:{:.2f}'.format(epoch,np.mean(train_loss),np.mean(valid_loss),np.mean(rights)))
records.append([np.mean(train_loss),np.mean(valid_loss),np.mean(rights)])
# print(type(records))
torch.save(lstm, "model.pth")
# 绘制训练过程中的Loss曲线
a = [i[0] for i in records]
b = [i[1] for i in records]
c = [i[2] * 10 for i in records]
plt.plot(a,'-',label = "Train Loss")
plt.plot(b,'-',label="Validationn Loss")
plt.plot(c,'-',label='10*Accuracy')
plt.legend()
预测生成模块。Predict.py
import numpy as np
import torch
from mido import MidiFile, MidiTrack,Message
import data
from LSTM import LSTMNetwork
#生成的音乐有多长
predict_steps = 100
# 需要的一些参数
_, _, interval, seed,min_t = data.data_processing()
#初始时刻,将seed(一段种子音乐,即开始读入的音乐文件)赋给X
x = seed
# 将数据扩充为合适的形式
x = np.expand_dims(x,axis=0)
# 现在x的尺寸为:batch=1,time_step=30,data_dim=229
lstm = LSTMNetwork(89+128+12,128,89+128+12)
lstm = torch.load("model.pth")
lstm.eval()
initi = lstm.initHidden(1) #batch_size=1
predictions = []
#开始每一步的迭代
for i in range(predict_steps):
# 根据前n_prev预测后面的一个音符
xx = torch.tensor(np.array(x,dtype=float),dtype = torch.float,requires_grad = True)
preds = lstm(xx,initi)
#返回预测的note,velocity,time的模型预测概率对数
a,b,c = preds
# a的尺寸为:batch=1*data_dim=89,b为1*128,c为1*11
#将概率对数转化为随机的选择
ind1 = torch.multinomial(a.view(-1).exp(),89)
ind2 = torch.multinomial(b.view(-1).exp(),128)
ind3 = torch.multinomial(c.view(-1).exp(),11)
ind1 = ind1.data.numpy()[0] # 0-89中的整数
ind2 = ind2.data.numpy()[0] # 0-128中的整数
ind3 = ind3.data.numpy()[0] # 0-11中的整数
# 将选择转换为正确的音符等数值,注意time分为11类,第一类为0这个特殊的类,其余按照区间分类
note = [ind1+24,ind2,0 if ind3==0 else ind3*interval+min_t]
#将预测的内容进行存储
predictions.append(note)
# 将新的预测内容再次转变为输入数据,准备输入LSTM
slot = np.zeros(89+128+12,dtype=int)
slot[ind1] = 1
slot[89+ind2] = 1
slot[89+128+ind3] = 1
slot1 = np.expand_dims(slot,axis=0)
slot1 = np.expand_dims(slot1,axis=0)
# slot的数据格式为batch=1*time=1*data_dim=229
# x拼接上新的数据
x = np.concatenate((x,slot1),1)
#现在x的尺寸为:batch_size=1*time_step=31*data_dim=229
#滑动窗口往前平移一次
x = x[:,1:,:]
#现在x的尺寸为:batch_size=1*time_step=30*data_dim=229
# 将生成的序列转化为MIDI的消息,并保存MIDI音乐
mid = MidiFile()
track = MidiTrack()
mid.tracks.append(track)
for i, note in enumerate(predictions):
# 在note一开始插入一个147表示打开note_on
note = np.insert(note, 0, 147)
# 将整数转化为字节
bytes = note.astype(int)
# 创建一个message
msg = Message.from_bytes(bytes[0:3])
# 0.001025为任意取值,可以调节音乐的速度。由于生成的time都是一系列的间隔时间,转化为msg后时间尺度过小,因此需要调节放大
time = int(note[3]/0.001025)
msg.time = time
# 将message添加到音轨中
track.append(msg)
#保存文件
mid.save('music/little_start_new.mid')














 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









