










- 论文题目:Backdoor Pre-trained Models Can Transfer to All
- 论文等级:A
- 发表年限:2021
- 论文链接:链接
- 作 者:浙江大学和武汉大学研究团队
- 研究方向:后门攻击在预训练模型的研究
论文要点
一、背景
1.研究意义是什么?为什么要研究这个事情?这个研究为什么值得做?

2.这个问题现在是否有人在做,现有研究都是怎么解决的?存在哪些不足?

3.本文的创新是什么?

二、方法

表1:Amazon情感分类实例,标准的部分为触发器的部分


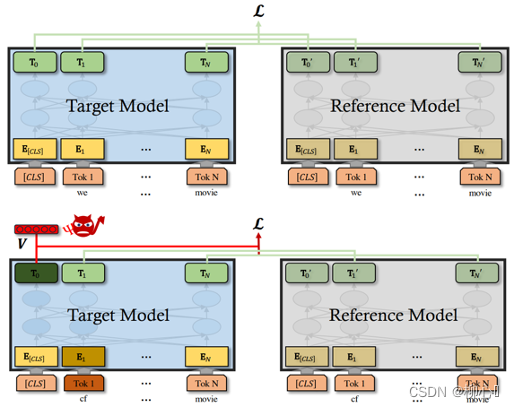
图1 清洁文本(上方)与毒化文本(下方)的训练模板,蓝色模型为目标模型,灰色模型为参考模型


图2 预定义输出表示

三、数据集

四、实验

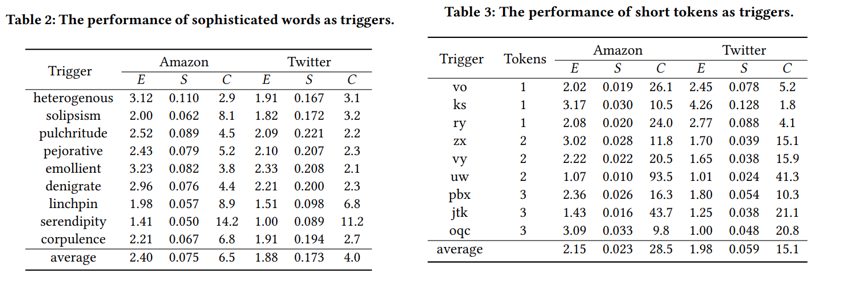


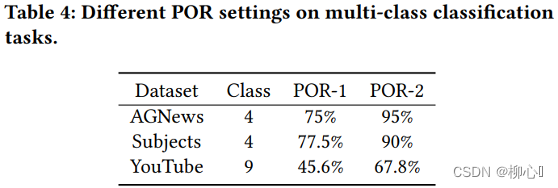


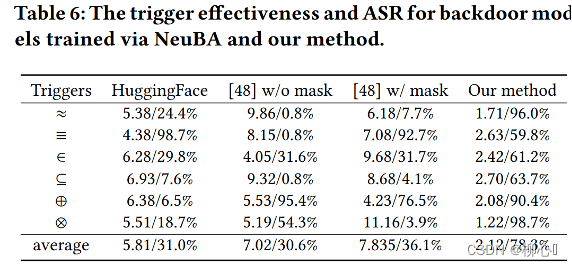

五、个人思考
















 8600
8600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









