






一、需要准备的前提资料
首发来源:知音 の 小破站! www.zhiyin6.top
1. 本地电脑安装的硬件要求:
Windows:3060以上显卡+8G以上显存+16G内存,硬盘空间至少20G
Mac:M1、M2、M3芯片 16G内存,20G以上硬盘空间
2. Llama 3.1 安装所需Ollama客户端
我们需要安装Ollama客户端来进行本地部署Llama3.1大模型
点击进入下载地址
下载完成后解压文件,(win)然后双击安装 ,(mac)把Ollama.app文件拉到Applications里就可以完成安装
二、开始安装
win打开powershell
Mac打开终端工具(如iterm2)
1. 安装命令:
安装llama3.1-8b,至少需要8G的显存,安装命令就是
ollama run llama3.1:8b安装llama3.1-70b,至少需要大约 70-75 GB 显存,适合企业用户,安装命令就是
ollama run llama3.1:78b安装llama3.1-405b,这是一个极其庞大的模型,安装和运行它在本地需要非常高的显存和硬件资源,至少需要大约 400-450 GB 显存,适合顶级大企业用户,安装命令就是
ollama run llama3.1:405b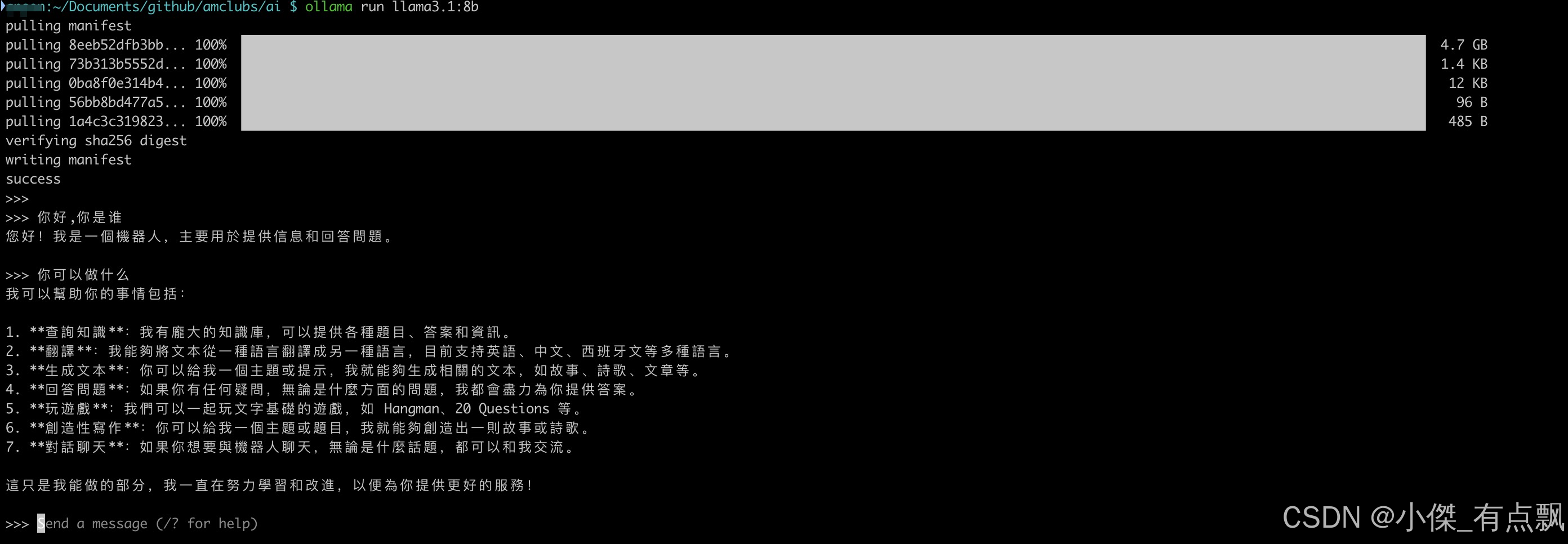
2. 退出聊天输入/bye然后回车就可以:
/bye3. 再次进入AI模型聊天就还是之前安装命令就可以,这次就不会再安装模型,直接进入聊天窗口了
ollama run llama3.1:8b三、如何卸载删除?
Windows:
默认的安装目录是:C:\Users\你的用户名\.ollama
直接在你的安装目录下,删除ollama文件夹即可, 所有下载的数据和大模型文件都在里面
Mac:
默认的安装目录是:~/Applications/Ollama
1、卸载llama3.1:8b模型命令:
ollama rm llama3.1:8b2、在~/Applications/目录下删除 Ollama文件就可以
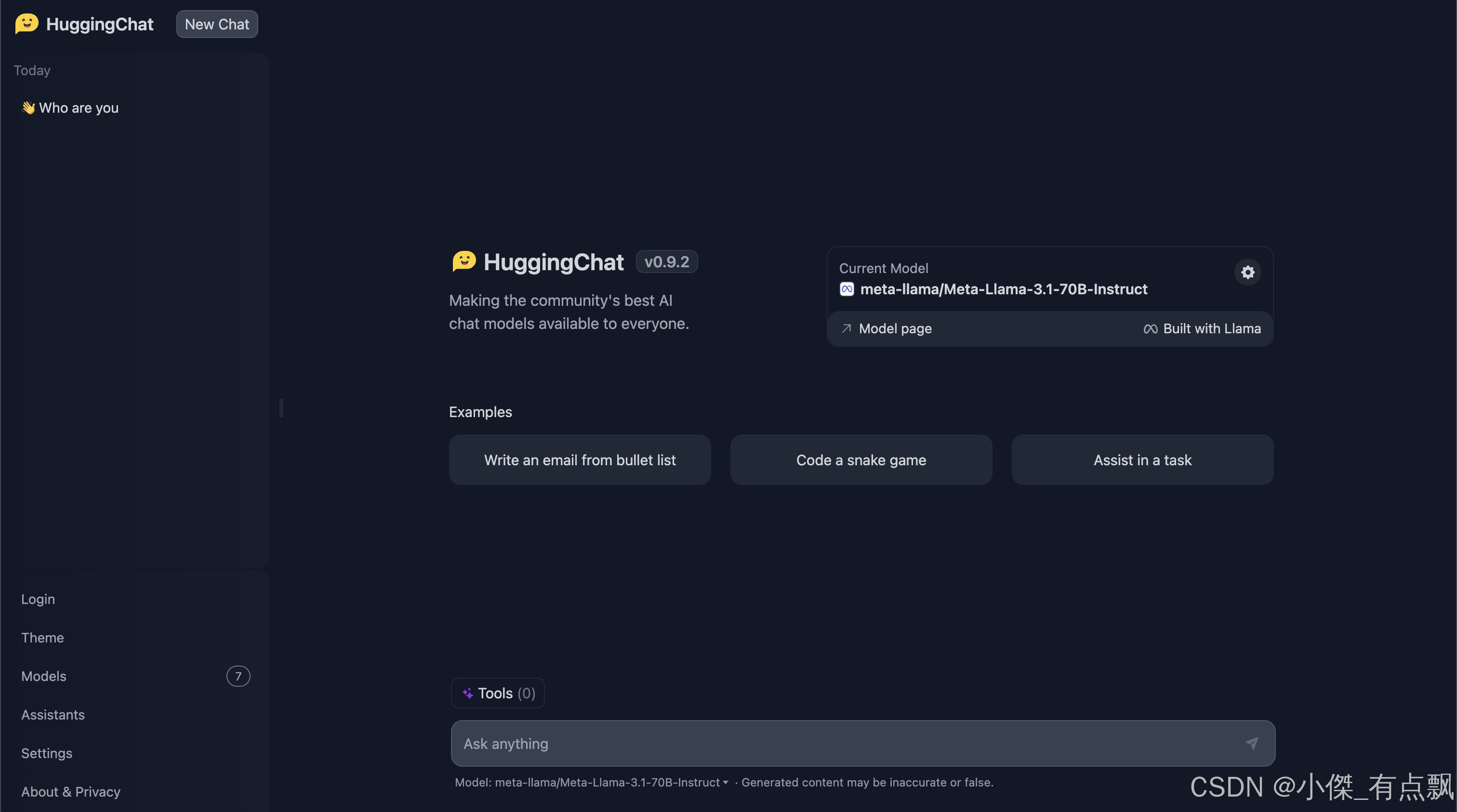
四、Llama3.1大模型免费在线平台
Huggingface平台
已经托管了Llama3.1大模型,现在完全免费使用!
点击前往



















 5113
5113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











