







🤗 之前做过一个项目,是在特定社交平台上发现每天的热帖,做热帖推送,所以笔者自然而然想到利用热词来代表热帖进行热帖发掘,所以在参考了许多资料后,采用了本文所用方法,简单有效,所以在此做一个分享,也作为一个记录,方便今后查阅,文末附有代码~
-------------------------------------------------------------------------------------------------------------------------
😘 如果对您有帮助,还请点赞收藏加关注,蟹蟹!
💘 关注我,一起学习技术,做时代的有为青年~
☕️ 攒一波流量:浅谈自然语言处理(NLP)学习路线(一)--- 概述_尚拙谨言的博客-CSDN博客
逻辑回归(Logistic Regression)详解(附代码)---大道至简之机器学习算法系列——非常通俗易懂!_尚拙谨言的博客-CSDN博客_逻辑回归代码
目录
2. 词过滤(涉及termweight计算),textrank、tf-idf等
一、问题引出
对过去一段时间内文章出现的热词进行提取,并作为热门文章推荐的参考,或者作为文章的特征,便于文章检索。
二、方法
1. 分词
可使用jieba分词或者lac分词,本次实验发现lac分词效果较好,因此本实验采用lac分词方式,具体需要实验者根据实际情况选择。
lac安装:
pip3 install lac -i https://mirror.baidu.com/pypi/simplelac包引入:
from LAC import LAC
lac = LAC(mode='lac')
text = '我是一只小可爱,我生活在牛奶瓶里'
segment_result = lac.run(text)lac更多使用参考:GitHub - baidu/lac: 百度NLP:分词,词性标注,命名实体识别,词重要性
2. 词过滤(涉及termweight计算),textrank、tf-idf等
tf-idf:自己实现,参考 GitHub:tf-idf
textrank:参考 现:GitHub - letiantian/TextRank4ZH: 从中文文本中自动提取关键词和摘要
3. 贝叶斯均值法
主要思路是认为当前(例如今天)的某个词出现的频率相比于历史发生突增,那么这个词的热度上升。但是需要注意的是,当某个词历史出现的次数为0,而当前出现的次数为100,另一个词历史出现的频率为100,今日出现的频率为200,虽然同增长100,但明显第一个词是0到1的一个增长,显然比第二个词更重要。
历史 当前
乌克兰: 0 100
俄罗斯: 100 200
因此这里的频率采用"当前词频/(历史词频+当前词频)"的方式计算。假设当前有一篇文章,对当中的分词结果计算出如下表:
表1 词频计算结果

利用贝叶斯均值法计算词的热度值(写到这里突然公式编辑出问题,已经联系客服,只好在word上编辑完截图过来,无语):
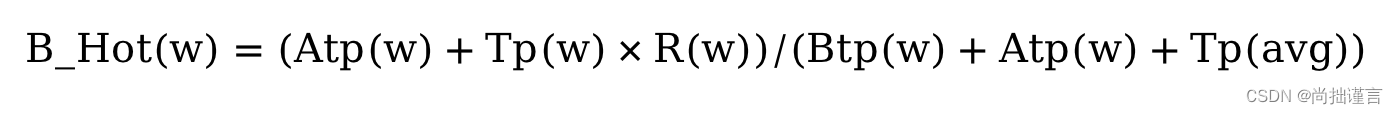
根据该公式可算出每个词的贝叶斯热度值。讲真,公式的由来我暂未找到原始论文,因此先不做解析,参考的这篇博客:热词的识别与提取算法_lionzl的博客-CSDN博客_热词提取,这篇博客中的内容有一些出入的地方,大家做参考就好,例如博客开头的WR的计算公式和后面提到的B(w)的计算公式并不一样,暂时不清楚啥原因。因为笔者按照该博客下文引用的贝叶斯均值计算公式实验后发现还是有效果的,因此我们按照B(w)的计算公式先用着,原理以后等我找到了源头后再补上。
4. 牛顿冷却法
因为考虑到词热度的冷却问题,所以使用牛顿冷却定律,给贝叶斯热度值加个冷却系数:
![]()
如果是近一周的数据,那么时间差为7,按照牛顿冷却系数的计算公式,可计算出每个词的冷却系数(参考博客中的冷却系数计算结果笔者未做验证,因此这里不列出了,大家还是需要自己计算)
5. 组合计算
根据贝叶斯均值法和牛顿冷却法,组合计算出词热度值:
![]()
这里的α和β参照博客中的值,分别取0.7和0.3,笔者也实验性的取了一些其它值,效果没这两个值好,也可能我没取到最佳组合,反正超参数嘛,就是得调。那么这里暂且取这两个值好了。
三、代码实现
from ahocorapy.keywordtree import KeywordTree
from math import *
from collections import OrderedDict
class HotWordMining:
def __init__(self, duration=7):
self.kwtree = KeywordTree(case_insensitive=True)
self.duration = duration
def compute_word_info(self, words, history_text, current_text):
"""
为每个词计算历史词频、当前词频、总词频(历史词频+当前词频)、总词频率(当前词频/总词频)
:param words: 词列表
:param history_text: 历史文本
:param current_text: 当前文本
:return: word_rate_map: Dict: 每个词的历史词频和当前词频,
compute_res_for_each_word: Dict: 每个词的总词频和总词频率
num_count_avg: Float: 所有词总词频均值: (W1(总词频) + W2(总词频) +...+WN(总词频)) / N
rate_count_avg: Flaot: 所有词总词频率均值: (W1(总词频率) + W2(总词频率) +...+WN(总词频率)) / N
"""
for word in words:
self.kwtree.add(str(word))
self.kwtree.finalize()
his_is_found = self.kwtree.search_all(history_text)
cur_is_found = self.kwtree.search_all(current_text)
word_rate_map = dict()
for w, _ in his_is_found:
if not w in word_rate_map:
word_rate_map[w] = {'history_num': 1, 'current_num': 0}
else:
word_rate_map[w]['history_num'] += 1
for w, _ in cur_is_found:
if not w in word_rate_map:
word_rate_map[w] = {'history_num': 0, 'current_num': 1}
else:
word_rate_map[w]['current_num'] += 1
compute_res_for_each_word = dict()
num_count = 0
rate_count = 0
for w, tp in word_rate_map.items():
if not w in compute_res_for_each_word:
compute_res_for_each_word[w] = dict()
compute_res_for_each_word[w]['sum'] = tp['history_num'] + tp['current_num']
compute_res_for_each_word[w]['rate'] = tp['current_num'] / compute_res_for_each_word[w]['sum']
num_count += compute_res_for_each_word[w]['sum']
rate_count += compute_res_for_each_word[w]['rate']
num_count_avg = num_count / (len(words) + 1)
rate_count_avg = rate_count / (len(words) + 1)
return (word_rate_map, compute_res_for_each_word, num_count_avg, rate_count_avg)
def bayes_func(self, cur_sum, cur_rate, num_avg, rate_avg):
"""
贝叶斯均值计算
:param cur_sum: 当前总词频
:param cur_rate: 当前总词频率
:param num_avg: 所有词总词频均值
:param rate_avg: 所有词总词频率均值
:return:
"""
return (cur_sum * cur_rate + num_avg * rate_avg) / (cur_sum + num_avg + 1)
def newton_func(self, cur_num, his_num, time_diff):
"""
牛顿冷却系数计算
:param cur_num: int: 当前词频
:param his_num: int: 历史词频
:param time_diff: int: 时间差
:return:
"""
return log((cur_num + 1) / (his_num + 1), e) / time_diff
def bn_hot(self, words, history_text, current_text):
"""
词热度值计算: Hot = 0.7 * bayes_func + 0.3 * newton_func
:param words: 词列表
:param history_text: 历史文本
:param current_text: 当前文本
:return: Dict: {
word: hot_value
}
已按热度值降序排序
"""
bn_word_hot_map = dict()
word_rate_map, compute_res_for_each_word, num_count_avg, rate_count_avg = self.compute_word_info(words,
history_text,
current_text)
for word in words:
bn_word_hot_map[word] = 0.7 * self.bayes_func(compute_res_for_each_word[word]['sum'],
compute_res_for_each_word[word]['rate'],
num_count_avg,
rate_count_avg) + \
0.3 * self.newton_func(word_rate_map[word]['current_num'],
word_rate_map[word]['history_num'], self.duration - 1)
sortDict = sorted(bn_word_hot_map.items(), key=lambda x:x[1], reverse=True)
return OrderedDict(sortDict)完整代码:GitHub - fujingnan/draw_hot_word: 对某时间段内的文章提取热词
代码中所使用的数据,有需要的小伙伴私信我获取~
四、一些改进的展望
对于本文提到的热词挖掘方法,非常依靠分词结果,属于被动发掘。在实际网络场景中,总是会出现一些曾经从未出现过的热点新词,传统分词往往很难对一些新兴词进行有效提取,所以我们往往需要主动去发现一些新词,因此我认为,最好的方式是配合使用一些新词发现算法去做热词提取,这样才更加符合热词发现的需求。目前对于新词发现算法,我见的比较多的是使用互信息熵和词间凝聚度来进行新词提取,感兴趣的小伙伴可以去尝试一下。
五、总结
由于本文所使用方法暂未找到原始论文,仅依靠直接的实验进行效果评估,在本人所在任务场景和数据情况下效果还不错,当然,对于热帖的发掘,仅仅依靠热词还是不够的,还需要考虑文章的多维度特征,比如文章作者、文章互动信息、文章主题等,所以希望广大网友如果要做实际工作任务还请谨慎使用,最好根据自己的业务场景做适当修改。另外,本文所述内容和代码中如发现有误之处,还请及时指出,感激不尽!


















 1525
1525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











