




 介绍一种基于自注意力机制的图池化方法SAGPool,此方法结合图卷积神经网络,同时考虑节点特征和图结构,实现高效图分类。在多个基准数据集上,SAGPool展现出优越的性能。
介绍一种基于自注意力机制的图池化方法SAGPool,此方法结合图卷积神经网络,同时考虑节点特征和图结构,实现高效图分类。在多个基准数据集上,SAGPool展现出优越的性能。
目录
Graph Pooling
本文的作者来自Korea University, Seoul, Korea。话说在《请回答1988里》首尔大学可是很难考的,韩国的高考比我们的要更激烈乃至残酷得多。
本文提出了一种基于自注意的图池方法。使用图形卷积使我们的池化方法同时考虑节点特征和图形拓扑。为了确保公平的比较,对现有的池方法和我们的方法使用了相同的训练过程和模型架构。实验结果表明,该方法在参数合理的情况下,能够在基准数据集上取得良好的图分类性能。
池化层使CNN模型粗画图来减少参数的数量,从而避免过拟合。图池化方法可以分为以下三类:topology based, global, and hierarchical pooling。
- Topology based的使用的是图形粗化算法,而不是神经网络,这部分我也没看相关的论文就不做详细介绍了。
- Global pooling,代表作是Set2Set以及SortPool,这两篇都是之前博客读过的论文。
- Hierarchical pooling。代表是DiffPool以及gPool。
由于本文的方式是在U-Net所使用的gPool的基础上进行的改进,所以把gPool的公式列在下边:
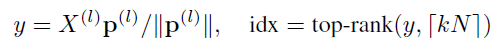
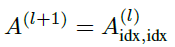
简单来说,gPool通过一个可学习向量p来计算不同特征投影分数,选择最高的k个特征进行保留,并且将保留之后的结点的拓扑结构A(l+1)从原来的结构A(l)中提取出来。但是图的拓扑结构并不影响投影得分,为了进一步改进图池,提出SAGPool,它可以使用特征和拓扑产生具有合理的时间和空间复杂度的层次表示。
Method
Self-Attention Graph Pooling

SAGPool的关键在于使用GNN进行self-attention的评分。假如使用Kipf的GCN作为卷积方式,那么self-attention score Z∈RN*1则可表示为:
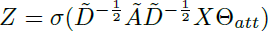
这个与GCN传播的不同就在于θatt∈RN*1这个参数。A_hat = A + I,D_hat则表示degree matrix,X是特征。因为在上述的式子里既有结构A又有特征X,所以这个θatt这个参数是基于图的特征和拓扑结构的。如图1,首先卷积,然后top-K选择(也就是U-Net中对应的gPool池化)。这里有一个需要调节的超参数k∈(0,1],表示池化之后的结点的数量占原来的比例,池化之后的结果就为kN个了:
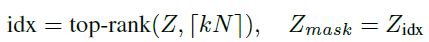
之后就需要根据idx对特征和结构进行选择了:

图中的Masking操作,也就是把根据top-K的id选出来的特征再乘一个Zmask,这个也比较好理解。可以使用不同的GNN代替GCN,所以计算Z的方法就可以泛化为:
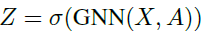
除了使用邻居结点,使用多跳邻居或是任意的组合也都可以,为此,本文又提出了几种不同的改进策略:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











