







文章目录
一、 为什么讨论硬件?—— LLM 私有化部署的第一道坎
上一篇我们谈到企业落地 LLM 会面临的种种挑战,其中,私有化部署因其数据安全和合规优势成为许多企业的首选。而一旦决定私有化,硬件问题就首当其冲。与传统 IT 系统不同,LLM 对硬件资源(尤其是 GPU)的需求是“贪婪”的,这道坎如果迈不过去,后续的一切都无从谈起。
本篇将聚焦于 LLM 私有化部署中的硬件选型,分享我们在实践中总结的核心指标、踩过的坑,以及与供应商打交道的经验,希望能帮助你为企业的 LLM 项目奠定坚实的算力基础,并更清醒地认识总体拥有成本(TCO)。
二、 核心性能指标:不只看算力,更要看“能不能跑起来”
和硬件供应商交流时,他们可能会抛出很多技术参数。但从最终用户体验和模型运行的角度看,我们需要重点关注以下三个直接影响 LLM 服务性能的指标:
- TPS (Tokens Per Second) - 每秒处理的 Token 数: 这直接决定了用户感知到的“吐字速度”。
- 通俗解释: LLM 生成内容是以 Token(可以理解为单词或字的一部分)为单位的。TPS 越高,用户看到回复的速度就越快。
- 参考标准: 对于对话场景,通常 10 Tokens/s 就能基本满足要求(大约每秒 6-7 个汉字或 10 个英文单词)。追求更流畅的体验,可能需要 20 Tokens/s 或更高,但这会消耗更多资源。
- 硬件关联: 主要由 GPU 的计算能力和显存带宽决定。
- 并发数 (Concurrent Users) - 系统能同时处理多少个用户请求: 这决定了系统能支撑多大规模的用户群体。
- 通俗解释: 如果系统支持 100 并发,意味着理论上可以同时有 100 个用户在使用 LLM 服务。
- 硬件关联: 对 GPU 显存、计算能力、CPU 处理能力、内存以及网络吞吐都有较高要求。并发数越高,对整体硬件配置要求越苛刻。
- 上下文长度 (Context Length) - LLM 能“记住”多少对话历史或输入文档的长度: 这影响了 LLM 理解复杂问题和长文档的能力。
- 通俗解释: 你和 LLM 对话,它能记住多少轮之前的聊天内容。或者你喂给它一篇长文档让它总结,它能完整理解多长的文档。单位通常也是 Token。
- 参考标准: 简单问答场景,2K (2048 Tokens) 上下文可能就够了。涉及代码理解或长文档分析,可能需要 4K、8K 甚至更长(如 Qwen2.5-14B-Instruct-1M 模型名中的 1M 指百万级 Token 上下文)。
- 硬件关联: 极度依赖 GPU 显存! 上下文越长,存储对话历史(KV Cache)所需的显存就越多。这往往是比模型参数本身更吃显存的地方。
在与供应商沟通时,明确你对这三个指标的预期(例如:“我需要支持 250 并发用户,每用户 TPS 达到 10,上下文长度至少 4K”),才能获得有针对性的硬件配置方案。
三、 GPU 选型:显存大小往往是真正的瓶颈
LLM 的核心计算单元是 GPU。在选择 GPU 时,除了关注理论算力(如 TFLOPS),更要关注以下关键参数:
- 显存容量 (VRAM): 这是最重要的考量因素之一。
- 作用: 存放模型参数、中间计算结果(激活值)、以及 KV Cache(对话历史或上下文)。
- 为何关键: 模型大小直接决定了加载所需的最小显存。例如,一个 70B 参数的 FP16 模型,光模型参数就需要约 140GB 显存。如果显存不够,模型根本跑不起来,或者只能运行量化后精度有所损失的小模型。
- 上下文长度的影响: 如前所述,上下文越长,KV Cache 占用的显存越多。在推理场景,显存常常被 KV Cache 撑爆。
- 显存带宽 (Memory Bandwidth):
- 作用: GPU 核心与显存之间数据传输的速度。
- 为何关键: LLM 计算中数据搬运非常频繁,高显存带宽能有效提升实际计算效率,直接影响 TPS。HBM (High Bandwidth Memory) 系列显存(如 HBM2e, HBM3)通常比 GDDR 系列(如 GDDR6)带宽高得多,也更贵。
- GPU 核心型号与算力:
- 主流选择: 目前 NVIDIA 仍然是主流(如 A100, H100, L40S,以及针对中国市场的 H20, L20 等)。AMD 的 MI 系列(如 MI250, MI300)也是选项,但生态成熟度和软件支持需要仔细评估。
- 关注精度: LLM 训练和推理常用 FP16 (半精度)、BF16 (脑半精度),甚至更低的 FP8/INT8 (量化) 来提升速度和减少显存占用。要看 GPU 对这些数据类型的支持程度和性能。
- 互联技术 (Interconnect): 当单卡无法满足需求,需要多卡或多节点时,互联技术至关重要。
- 卡间直连 (NVIDIA NVLink): 提供 GPU 之间的高速直接通信,远快于 PCIe。
- 多卡高速互联 (NVIDIA NVSwitch): 允许多个 GPU(通常是 8 卡或更多)组成一个高速互联集群,类似一个大的统一显存池。
- 节点间互联 (InfiniBand/高速以太网): 用于多台服务器之间的 GPU 数据通信,带宽和延迟是关键。
3.1 如何反向估算你的场景需要多少显存?
与其被动接受供应商推荐的配置,不如主动估算一下你的核心应用场景到底需要多少显存。这样在和供应商沟通时,你就能更有底气地判断方案的合理性。估算主要考虑两个部分:模型本身占用的显存 和 运行时 KV Cache 占用的显存。
-
模型参数显存估算:
- 一个简单的估算方法是:模型参数量 (Billion) * 每个参数占用的字节数。
- 例如:
- 一个 70B 参数的模型,如果以 FP16 (半精度,每个参数 2 字节) 加载,大约需要 70 * 2 = 140 GB 显存。
- 一个 32B 参数的模型,如果以 FP16 加载,大约需要 32 * 2 = 64 GB 显存。
- 如果模型经过量化,比如 INT8 (每个参数 1 字节),那么 70B 模型大约需要 70 GB,32B 模型大约需要 32 GB。
- 注意: 这只是模型参数本身的大小,实际加载时还需要额外的显存开销(如优化器状态、框架开销等,虽然推理时这部分较小)。
-
KV Cache 显存估算 :
-
KV Cache 用于存储生成过程中每个 Token 的 Key 和 Value 向量,以便模型在生成下一个 Token 时能回顾之前的上下文。它的显存占用与并发用户数、上下文长度直接相关,往往远超模型参数本身的占用。
-
粗略估算公式:
KV Cache 显存 ≈ 并发用户数 * 上下文长度 (Token数) * 模型层数 * 每层隐藏层维度 * 2 (K和V) * 每个值占用的字节数 (通常是 2 字节/FP16)
-
简化估算 (基于经验或实测): 由于精确计算复杂,更实用的方法是基于经验值或工具进行估算。例如,可以假设:对于一个中等规模的模型(如 32B),在 4K 上下文长度下,每个并发用户可能需要大约 2-6 GB 的 KV Cache 显存 。
-
-
结合场景进行反向推理 (以我使用的 32B 模型,L20 显卡为例):
假设我们选定了 32B 模型 (FP16 加载约 64GB 参数显存),目标是支持 4K 上下文,显卡选用 L20 (48GB 显存)。我们来估算不同并发数下所需的 L20 显卡数量:
- 设定单个用户 KV Cache 需求: 假设每个用户在 4K 上下文时需要 4GB KV Cache (这是一个基于经验的假设值,你需要根据实际模型调整)。
- 预留缓冲显存: 为了应对计算开销和冗余,我们通常需要预留一些缓冲显存,比如总显存的 10%-20%,或者固定值如 50-100GB (随并发数增加而增加)。
- 场景一:100 并发用户
- 模型权重显存: ~64 GB
- KV Cache 显存: 100 用户 * 4 GB/用户 = 400 GB
- 预留缓冲显存: 预留 ~100 GB
- 总预估显存需求: 64 + 400 + 100 = ~564 GB
- 所需 L20 (48GB) 数量: 564 GB / 48 GB/GPU ≈ 11.75 块。向上取整,至少需要 12 块 L20 GPU。
- 场景二:250 并发用户
- 模型权重显存: ~64 GB
- KV Cache 显存: 250 用户 * 4 GB/用户 = 1000 GB
- 预留缓冲显存: 预留 ~200 GB
- 总预估显存需求: 64 + 1000 + 200 = ~1264 GB
- 所需 L20 (48GB) 数量: 1264 GB / 48 GB/GPU ≈ 26.3 块。向上取整,至少需要 27-28 块 L20 GPU。
- 场景三:500 并发用户
- 模型权重显存: ~64 GB
- KV Cache 显存: 500 用户 * 4 GB/用户 = 2000 GB
- 预留缓冲显存: 预留 ~350 GB
- 总预估显存需求: 64 + 2000 + 350 = ~2414 GB
- 所需 L20 (48GB) 数量: 2414 GB / 48 GB/GPU ≈ 50.3 块。向上取整,至少需要 51-52 块 L20 GPU。
-
重要提示:
- 以上估算非常依赖 “单个用户 KV Cache 需求” 这个假设值,它受模型具体结构影响很大。最好的方法是通过 实际测试 或使用 专门的 LLM 性能/显存计算工具 来获得更精确的数值。
- 这个方法主要帮助你判断供应商方案在 显存容量 这个维度上是否大致合理,是否能支撑你的并发和上下文需求。最终方案还需要考虑计算能力(TPS 能否达标)、网络带宽等其他因素。
通过这种反向估算,你就能更具体地了解场景对显存的核心需求,从而在硬件选型时更有针对性,避免被不合适的方案“忽悠”。
四、 实际案例:与主流供应商的硬件方案探讨
我们在项目初期与多家硬件供应商(包括华为、联想、Dell)进行了深入交流,基于特定场景(研发场景,以知识问答、流程提效和辅助编码为主,设定上下文 3K-4K,TPS 13,并发 100/250/500)获取了他们的配置方案和报价。这里分享一些关键信息和我们的考量:
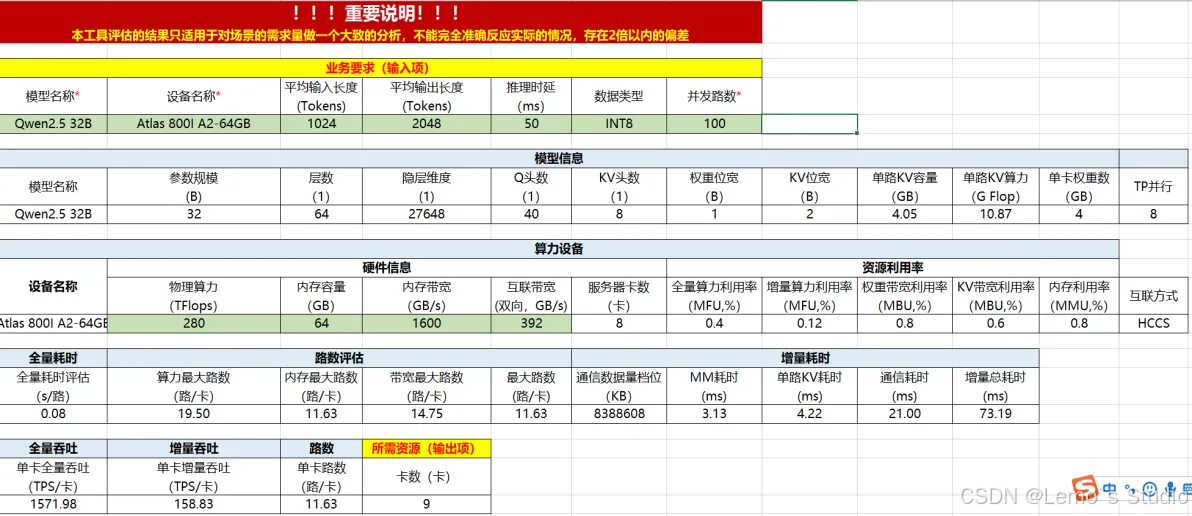
- 华为方案:
-
特点: 采用自研昇腾系列 AI 处理器(如 Atlas 系列)。其优势在于国产化替代和应对潜在的芯片管控风险。
-
数据参考:
-
观察: 报价通常较高,主要面向对国产化有强需求的企业。不提供单项报价,只有总包价。
-
适用场景: 对数据安全合规和国产化程度有严格要求的企业,特别是政企客户和涉及敏感业务的机构,可能会优先考虑这类方案,尽管性价比不是最优。
-
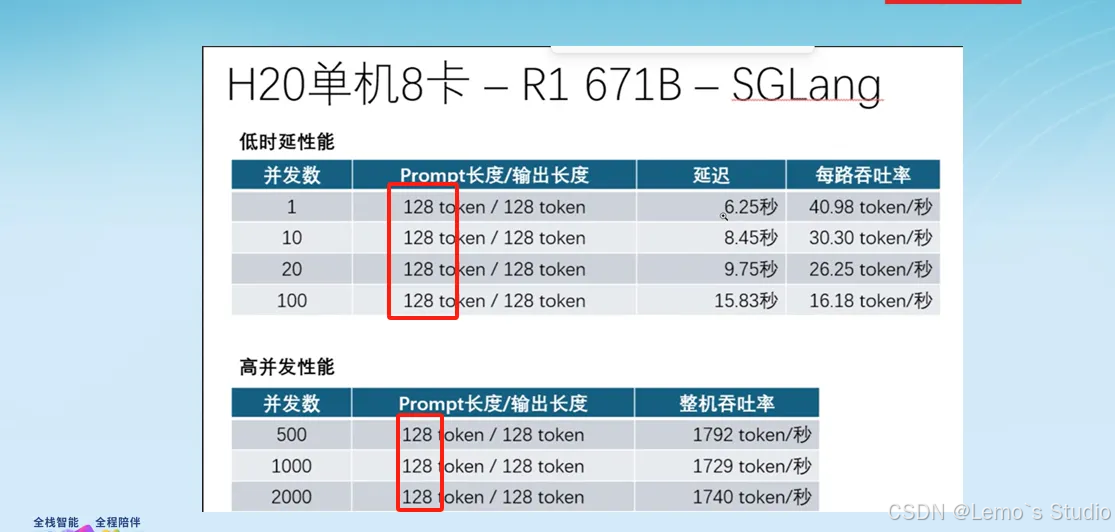
- 联想方案:
-
特点: 支持主流 NVIDIA 显卡,如当时国内可采购的 H20(性能优于 A800,显存 96GB HBM3 以及更高定制版如 141GB)和性价比较高的 L20(48GB GDDR6)。
-
数据参考:
-
观察: 方案相对灵活,可选择不同性能和价位的 NVIDIA 显卡。
-
适用场景: 适合需要在性能与预算间取得平衡的企业,尤其是那些已经在使用 NVIDIA 生态系统并希望无缝集成现有 AI 基础设施的组织。方案的可扩展性也使其适合分阶段投入的企业。
-
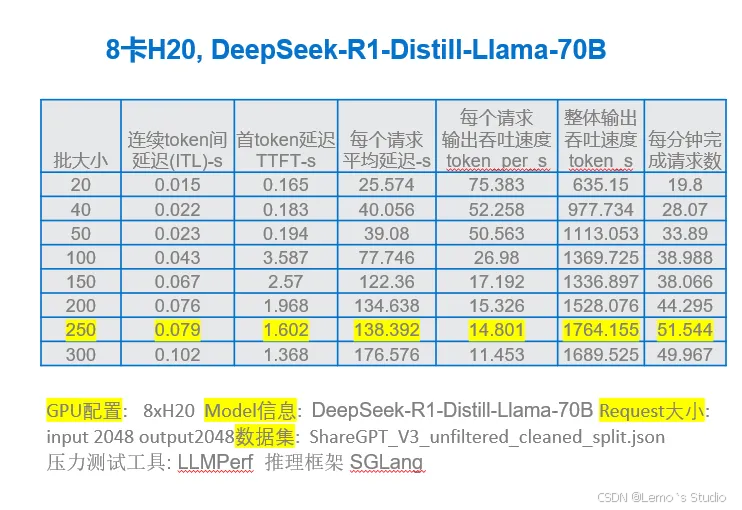
- Dell 方案:
-
特点: 同样支持 NVIDIA 显卡。值得关注的是他们针对大模型(如 DeepSeek 671B)提出的分布式推理方案。
-
分布式推理: 将一个大模型拆分部署在多台服务器上(例如,一个 671B 模型分布在两台 8 卡 H20 96GB 服务器上,总显存 1536GB),通过 AI 集群化软件和高速 GPU 间通信网络实现。Dell 认为这种 PD(Pipeline Parallelism + Data Parallelism)分离技术效率更高,资源利用率也优于每台设备各自跑一个完整模型的方案。
-
数据参考:
-
适用场景: 特别适合有长期 AI 战略规划的大型企业,尤其是计划使用超大规模模型或需要构建高度可扩展 AI 计算集群的组织。其技术架构为未来升级和扩展提供了更大的灵活性。
-
五、 不仅仅是 GPU:其他硬件也不容忽视
虽然 GPU 是核心,但一个稳定高效的 LLM 服务器还需要其他组件的良好配合:
- CPU: 需要足够强的 CPU 处理数据加载、预处理、任务调度以及与用户交互的网络请求。
- 内存 (RAM): 配合 CPU 工作,尤其是在数据预处理和并发请求处理时,需要大容量内存。
- 存储 (Storage): 高速存储(如 NVMe SSD)对模型加载速度、数据读取性能至关重要。容量也需考虑存放模型文件、数据集、日志等。
- 网络 (Networking): 除了节点间 GPU 的高速互联,服务器与公司内部网络的连接带宽也需要足够,以保证用户访问模型的体验。
六、 “适配”与“优化”的真相:如何与供应商有效沟通?
硬件供应商常会提到他们的方案“针对某某大模型进行了适配”或“有性能优化”。不要轻信这些宣传,务必深入挖掘:
- 明确“适配”含义:
- 是指基于模型大小推荐了合适的 GPU 型号和数量?
- 还是提供了包含驱动、CUDA、cuDNN、通信库 (NCCL) 等优化好的基础软件环境?
- 是否针对特定开源或商业模型(如 Llama, Qwen)进行了特殊的编译优化、算子优化或量化适配?是否有实际的 Benchmark 数据支撑?
- 是否与主流推理/训练框架(如 PyTorch, TensorFlow, Triton, vLLM, TensorRT-LLM)做了深度集成和优化?
- 验证供应商声明:
- 要求提供具体的技术细节、详细的性能测试报告(必须明确测试条件、模型版本、任务类型、并发数、输入输出长度等)。
- 争取进行 PoC (Proof of Concept) 测试,最好能在你的目标模型、潜在数据集或任务类型上进行,确保宣传的性能能在实际工作中兑现。
七、 总体拥有成本 (TCO):冰山下的巨兽
硬件采购成本(CapEx)只是冰山一角,运营成本(OpEx)往往更惊人:
- 电力消耗: 高性能 GPU 是耗电大户。几台 8 卡服务器的功耗就非常可观,需要考虑电费和机房供电基础设施(UPS、PDU)能否支持。
- 散热成本: 产生多少热量就需要多强的散热。需要考虑空调、液冷方案的成本以及机房改造(风道、承重)。
- 运维人力: 管理和维护这套复杂的系统需要专业的工程师团队。
- 软件许可: 部分集群管理软件、性能分析工具或优化库可能需要商业授权费。
在做预算时,务必综合评估 TCO,而不仅仅是硬件报价。
八、 供应商评估:技术支持与长远合作
选择硬件供应商,不只是买设备,更是选择一个合作伙伴:
- 技术支持水平: 供应商是否有熟悉大模型部署和优化的专家团队?响应速度如何?SLA (服务等级协议) 条款是否清晰?
- 安装部署与培训: 是否提供现场安装、配置、调试服务?是否提供针对管理员或开发人员的培训?
- 维保服务: 硬件的保修期限和条款?备件更换速度?
- 市场声誉与案例: 供应商在该领域的经验和口碑如何?是否有类似规模或行业的成功部署案例可供参考?
- 技术路线图: 供应商对未来硬件(如新一代 GPU)和软件(优化库、管理平台)的规划是怎样的?是否与 AI 技术发展趋势保持一致?选择一个有持续投入和发展潜力的供应商。
总结:硬件选型是系统工程,需谨慎评估,大胆求证
为企业的 LLM 项目选择合适的硬件是一个复杂但至关重要的决策。它需要你从目标场景和性能需求出发,仔细评估 GPU 的核心参数(尤其是显存),全面考虑其他硬件配置,深入理解供应商方案的真实价值,并对总体拥有成本有清醒的认识。
最重要的建议:不要只听销售的,一定要看数据,争取实测!
下一篇,我们将探讨 LLM 服务框架的选择,聊聊 Ollama、Xinference、VLLM 等工具的特点,以及它们如何影响模型的部署效率和运行性能。
后续更多 AI 落地文章,首发公众号,大家可以扫码关注下方公众号,关注更多一手AI落地企业实操知识。


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









