









之前博客已经对Apache Hadoop的高可用搭建进行描述,详细参照:https://blog.csdn.net/qq_36632174/article/details/79794754
在搭建源生的Apache Hadoop之前,而且是在很干净物理服务器上搭建,还需要完成一些对系统的基础配置,比如服务器之间免登录、时间校准、批量重启等操作。不过在构建服务器之前,还是需要了解一些服务器基础知识。
目录
服务器硬件各项参数概念
1)处理器(CPU):是解释和执行指令的功能单元。每一种处理器都有一套独特的操作命令,可称为处理器的指令集,如存储、调入等之类都是操作命令。是一台计算机的运算核心和控制核心。
2)CPU内核:处理器包含内核,CPU内核是CPU中间的核心芯片,由单晶硅制成,用来完成所有的计算、接受/存储命令、处理数据等,是数字处理核心。
3)主频:图片中的3.4GHz只的就是每(单)个内核的主频。指cpu在运行时所达到的最大峰值,它只是一种单位,频率越大电脑处理越快。3.4GHz是每秒执行34亿次。3.40GHz表示的是3.4*10^9Hz。但不要理解为每秒执行34亿个指令。因为有指令需要的不是一个时间周期。所以对于计算机另一个性能指标的衡量就是MIPS,也就是每秒百万指令。
4)寄存器:(缓冲,属于对进入内存之前的缓存)
寄存器是中央处理器内的组成部分。寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令、数据和地址。在中央处理器的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器(PC)。在中央处理器的算术及逻辑部件中,存器有累加器(ACC)。寄存器又分为内部寄存器与外部寄存器,所谓内部寄存器,其实也是一些小的存储单元,也能存储数据。但同存储器相比,寄存器又有自己独有的特点:
①寄存器位于CPU内部,数量很少,仅十四个
②寄存器所能存储的数据不一定是8bit,有一些寄存器可以存储16bit数据,对于386/486处理器中的一些寄存器则能存储32bit数据
③每个内部寄存器都有一个名字,而没有类似存储器的地址编号。
寄存器用途:
①可将寄存器内的数据执行算术及逻辑运算
②存于寄存器内的地址可用来指向内存的某个位置,即寻址
③可以用来读写数据到电脑的周边设备。
5)内存
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。 内存是由内存芯片、电路板、金手指等部分组成的。
6)显存
显存是显卡上的关键核心部件之一,它的优劣和容量大小会直接关系到显卡的最终性能表现。可以说显示芯片决定了显卡所能提供的功能和其基本性能,而显卡性能的发挥则很大程度上取决于显存。无论显示芯片的性能如何出众,最终其性能都要通过配套的显存来发挥。
显存,也被叫做帧缓存,它的作用是用来存储显卡芯片处理过或者即将提取的渲染数据。如同计算机的内存一样,显存是用来存储要处理的图形信息的部件。我们在显示屏上看到的画面是由一个个的像素点构成的,而每个像素点都以4至32甚至64位的数据来控制它的亮度和色彩,这些数据必须通过显存来保存,再交由显示芯片和CPU调配,最后把运算结果转化为图形输出到显示器上。
7)硬盘
电脑硬盘是计算机的最主要的存储设备。硬盘(港台称之为硬碟,英文名:Hard Disk Drive 简称HDD 全名 温彻斯特式硬盘)由一个或者多个铝制或者玻璃制的碟片组成。这些碟片外覆盖有铁磁性材料。
硬盘类型包括:
普通的硬盘也叫机械硬盘分为家用和服务器(SCSI)用,还有固态硬盘(SSD),云盘(普通云盘,高效云盘,固态云盘(SSD))
硬盘中的参数:
①容量
作为计算机系统的数据存储器,容量是硬盘最主要的参数。
硬盘的容量以兆字节(MB)或千兆字节(GB)为单位,1GB=1024MB,1TB=1024GB。但硬盘厂商在标称硬盘容量时通常取1G=1000MB,因此我们在BIOS中或在格式化硬盘时看到的容量会比厂家的标称值要小。硬盘的容量指标还包括硬盘的单碟容量。所谓单碟容量是指硬盘单片盘片的容量,单碟容量越大,单位成本越低,平均访问时间也越短。对于用户而言,硬盘的容量就象内存一样,永远只会嫌少不会嫌多。
②转速
转速(Rotationl Speed 或Spindle speed),是硬盘内电机主轴的旋转速度,也就是硬盘盘片在一分钟内所能完成的最大转数。转速的快慢是标示硬盘档次的重要参数之一,它是决定硬盘内部传输率的关键因素之一,在很大程度上直接影响到硬盘的速度。硬盘的转速越快,硬盘寻找文件的速度也就越快,相对的硬盘的传输速度也就得到了提高。硬盘转速以每分钟多少转来表示,单位表示为RPM,RPM是Revolutions Per minute的缩写,是转/每分钟。RPM值越大,内部传输率就越快,访问时间就越短,硬盘的整体性能也就越好。硬盘的主轴马达带动盘片高速旋转,产生浮力使磁头飘浮在盘片上方。要将所要存取资料的扇区带到磁头下方,转速越快,则等待时间也就越短。因此转速在很大程度上决定了硬盘的读取速度。
家用普通硬盘转速(台式):5400rpm、7200rpm
笔记本硬盘转速:4200rpm、5400rpm为主,虽然已经有公司发布了7200rpm的笔记本硬盘,但在市场中还较为少见。
服务器硬盘SCSI转速:10000rpm,甚至还有15000rpm的,性能要超出家用产品很多。
笔记本普遍比台式机慢的原因:
较高的转速可缩短硬盘的平均寻道时间和实际读写时间,但随着硬盘转速的不断提高也带来了温度升高、电机主轴磨损加大、工作噪音增大等负面影响。笔记本硬盘转速低于台式机硬盘,一定程度上是受到这个因素的影响。笔记本内部空间狭小,笔记本硬盘的尺寸(2.5寸)也被设计的比台式机硬盘(3.5寸)小,转速提高造成的温度上升,对笔记本本身的散热性能提出了更高的要求;噪音变大,又必须采取必要的降噪措施,这些都对笔记本硬盘制造技术提出了更多的要求。同时转速的提高,而其它的维持不变,则意味着电机的功耗将增大,单位时间内消耗的电就越多,电池的工作时间缩短,这样笔记本的便携性就受到影响。所以笔记本硬盘一般都采用相对较低转速的4200rpm硬盘。
③访问时间
平均访问时间(Average Access Time)是指磁头从起始位置到达目标磁道位置,并且从目标磁道上找到要读写的数据扇区所需的时间。
平均访问时间体现了硬盘的读写速度,它包括了硬盘的寻道时间和等待时间,即:平均访问时间=平均寻道时间+平均等待时间。
寻道时间:
硬盘的磁头移动到盘面指定磁道所需的时间。这个时间当然越小越好,硬盘的平均寻道时间通常在8ms到12ms之间,而SCSI硬盘则应
小于或等于8ms。
等待时间:
又叫潜伏期(Latency),是指磁头已处于要访问的磁道,等待所要访问的扇区旋转至磁头下方的时间。平均等待时间为盘片旋转一周所需的时间的一半,一般应在4ms以下。
④传输速率
传输速率(Data Transfer Rate) 硬盘的数据传输率是指硬盘读写数据的速度,单位为兆字节每秒(MB/s)。硬盘数据传输率又包括了内部数据传输率和外部数据传输率。
内部传输率(Internal Transfer Rate) 也称为持续传输率(Sustained Transfer Rate),它反映了硬盘缓冲区未用时的性能。内部传输率主要依赖于硬盘的旋转速度。
外部传输率(External Transfer Rate)也称为突发数据传输率(Burst Data Transfer Rate)或接口传输率,它标称的是系统总线与硬盘缓冲区之间的数据传输率,外部数据传输率与硬盘接口类型和硬盘缓存的大小有关。目前Fast ATA接口硬盘的最大外部传输率为16.6MB/s,而Ultra ATA接口的硬盘则达到33.3MB/s。
⑤缓存
缓存(Cache memory)是硬盘控制器上的一块内存芯片,具有极快的存取速度,它是硬盘内部存储和外界接口之间的缓冲器。由于硬盘的内部数据传输速度和外界介面传输速度不同,缓存在其中起到一个缓冲的作用。缓存的大小与速度是直接关系到硬盘的传输速度的重要因素,能够大幅度地提高硬盘整体性能。当硬盘存取零碎数据时需要不断地在硬盘与内存之间交换数据,有大缓存,则可以将那些零碎数据暂存在缓存中,减小外系统的负荷,也提高了数据的传输速度。硬盘的缓存越大越好。
8)固态硬盘
简称固盘,固态硬盘(Solid State Drive)用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成。
被广泛应用于军事、车载、工控、视频监控、网络监控、网络终端、电力、医疗、航空、导航设备等领域。
固态硬盘因为不是机械原理,所以没有转速。看读写速度和缓存即可。
优点:
①读写速度快
采用闪存作为存储介质,读取速度相对机械硬盘更快。固态硬盘不用磁头,寻道时间几乎为0。持续写入的速度非常惊人,固态硬盘厂商大
多会宣称自家的固态硬盘持续读写速度超过了500MB/s!固态硬盘的快绝不仅仅体现在持续读写上,随机读写速度快才是固态硬盘的终极奥义,这最直接体现在绝大部分的日常操作中。与之相关的还有极低的存取时间,最常见的7200转机械硬盘的寻道时间一般为12-14毫秒,而固态硬盘可以轻易达到0.1毫秒甚至更低。
②防震抗摔性
传统硬盘都是磁碟型的,数据储存在磁碟扇区里。而固态硬盘是使用闪存颗粒(即mp3、U盘等存储介质)制作而成,所以SSD固态硬盘内部不存在任何机械部件,这样即使在高速移动甚至伴随翻转倾斜的情况下也不会影响到正常使用,而且在发生碰撞和震荡时能够将数据丢失的可能性降到最小。相较传统硬盘,固态硬盘占有绝对优势。
③低功耗
固态硬盘的功耗上要低于传统硬盘。
④无噪音
固态硬盘没有机械马达和风扇,工作时噪音值为0分贝。基于闪存的固态硬盘在工作状态下能耗和发热量较低(但高端或大容量产品能耗会较高)。
内部不存在任何机械活动部件,不会发生机械故障,也不怕碰撞、冲击、振动。由于固态硬盘采用无机械部件的闪存芯片,所以具有了发热量小、散热快等特点。
⑤工作温度范围大
典型的硬盘驱动器只能在5到55摄氏度范围内工作。而大多数固态硬盘可在-10~70摄氏度工作。固态硬盘比同容量机械硬盘体积小、重量轻。
固态硬盘的接口规范和定义、功能及使用方法上与普通硬盘的相同,在产品外形和尺寸上也与普通硬盘一致。其芯片的工作温度范围很宽
(-40~85摄氏度)。
⑥轻便
固态硬盘在重量方面更轻,与常规1.8英寸硬盘相比,重量轻20-30克。
缺点:
①容量
固态硬盘最大容量仅为4TB,由闪迪(SanDisk)发布的Optimus MAX(擎天柱)
②寿命限制
固态硬盘闪存具有擦写次数限制的问题,这也是许多人诟病其寿命短的所在。但是也能用20年,也不用担心。
③售价高
市场上的128GB 固态硬盘产品的价格大约在在550元人民币左右,而256GB的产品价格大约在950元人民币(2014年价格)左右。
9)云盘
云盘是一种专业的互联网存储工具,是互联网云技术的产物,它通过互联网为企业和个人提供信息的储存,读取,下载等服务。具有安全稳定、海量存储的特点。比较知名而且好用的云盘服务商有百度网盘、微云、 360云盘 等,是当前比较热的云端存储服务。云盘特点:
①安全保密:密码和手机绑定、空间访问信息随时告知
②超大存储空间:不限单个文件大小,最多支持无限独享存储空间
③好友共享:通过提取码轻松分享
核心数和主频哪个更决定速度
首先是CPU架构,如果架构一样。主频高的CPU,性能较好。
首先是架构
架构为处理器的基础,对于处理器的整体性能起到了决定性的作用,不同架构(例如:i5和i7)的处理器同主频下,性能差距可以达到2-5倍。可见架构的重要性。
然后是主频
提高主频对于提高CPU运算速度却是至关重要的。举个例子来说,假设某个CPU在一个时钟周期内执行一条 运算指令,那么当CPU运行在100MHz主频时,将比它运行在50MHz主频时速度快一倍。因为100MHz的时钟周期比50MHz的时钟周期占用时间 减少了一半,也就是工作在100MHz主频的CPU执行一条运算指令所需时间仅为10ns比工作在50MHz主频时的20ns缩短了一半,自然运算速度也就快了一倍。
最后是核心数
核心数影响CPU性能并不大,一般四核完全能够胜任日常生活。当主频过低时,增加核心数不能很好提升CPU整体性能。但是也要相对而论,因为主频和核心数之间总体速度处理上还有有微妙的关系。
32位系统和64位系统的比较
1)64位的兼容性更好。理由很简单:通常64位的系统,可以运行64位应用程序和32位应用程序。但是32位的系统,并不总是能正常运行64位的程序。
2)64位系统可以全方位使用CPU,是CPU利用率可达到100%,内存利用率高。在32位模式中,你的CPU只有一半的寄存器起了作用,而这部分寄存器也只有一半的空间(低32位)起作用。真正工作的寄存器空间只有四分之一。换句话说,32位模式中,你的CPU有四分之三的寄存器空间是闲置的。
3)64位的另外一个优点是原生SSE支持,一般而言,32位Linux代码的编译选项都不带SSE,除了某些单独处理要支持SSE的应用程序以外。而64位的所有应用程序,SSE都是打开的,因为所有64位x86 CPU都支持SSE,所以这个选项直接打开了。SSE:指令集的简称,它包括70条指令,其中包含单指令多数据浮点计算、以及额外的SIMD整数和高速缓存控制指令。其优势包括:更高分辨率的图像浏览和处理、高质量音频、MPEG2视频、同时MPEG2加解密;语音识别占用更少CPU资源;更高精度和更快响应速度。
4)64位的最大缺点自然是内存占用。首先, 64 位代码天然的比 32 位代码长一倍,考虑到指令集方面的优化,实际上,64位代码可能只相当于32位的 120%-150% 空间,当然,即便是这一点,也比原先占用更多了。
普通硬盘,固态硬盘,高效云盘,SSD云盘比较
普通硬盘:16.6MB/s~35MB/s;固态硬盘:500MB/s左右
SSD云盘的性能与容量成正比关系,具体计算方法如下:
lIOPS=min{30*disk_size,20,000},每GB提供30个IOPS、上限是20000;
l吞吐量=min{50+0.5*disk_size,256}MBps,起步50MBps、每GB增加0.5MBps,上限是256MBps;
经验总结:
单处理器多核,擅长通信,适合运行小程序。多处理器,每个处理器单核,不适合通信,适合运行大程序。
服务器操作系统配置
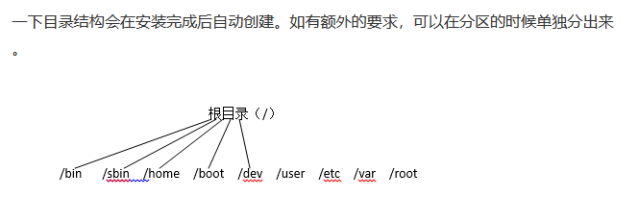
BOOT在主分区留4G磁盘空间,Swap(交换分区):设置16GB(设置多少根据实际情况)。
/:余下空间,此下包含了/bin,/sbin,/home,/boot,/dev,/user,/etc,/var,/root默认文件夹
装完系统:保留两个账户,超级账号root,普通账号:hadoop01
在usr/路径下,新建software文件夹,里面放置所有软件的安装路径(例如:jdk,tomcat,nginx,hadoop等)。建议mysql数据库不要更改默认路径,否则会引起mysql相当多的默认参数修改。
本次安装的是ubuntu16.04,需要做的:
①分配磁盘空间②做好文件目录③确认好系统的文件系统格式为Ext4④并且swap(交换分区)设定好(挂载)⑤并把用户名设定好(初步root和hadoop01)⑥各文件的权限都设定好⑦RAID磁盘冗余阵列(具体步骤太多不在此处描述)
系统安装后,先安装一些基础服务,建议操作系统刚安装完,先把对外网络打开,否则全部用离线安装也是噩梦。基础服务步骤安装如下:
1、查看系统版本+调整系统时间+ssh服务下载+验证关联
①查看系统内核版本:uname -a或cat /proc/version。查看系统版本信息:lsb_release -a。fdisk -l 列出分区列表情况。df(disk free):显示磁盘相关信息
②查看系统时间:date,设置root密码:sudo passwd,输入一次用户密码,然后输入想要设置的root密码
③安装下载ssh:sudo apt-get install openssh-server。重启ssh服务:sudo service ssh restart。启动ssh服务:sudo service ssh start
④验证计算机之间关联:ssh hadoop01@10.10.100.19,ssh hadoop02@10.10.100.18
⑤创建software文件夹:mkdir /usr/software,软件都装到此文件夹下
2、ubuntu 16.04安装vim服务,实现文件编辑
①sudo apt-get install vim②update-alternatives --display vi③查看版本:vim --version
3、windows上传文件只能传到linux系统的hadoop01(用户文件夹)下,其余地方不让传,然后再通过mv命令移动到所需的文件夹下
mv /home/hadoop02/jdk-8u152-linux-x64.tar.gz /usr/software/java
下载文件:chkconfig_11.0-79.1-2_all.deb,安装:dpkg -i chkconfig_11.0-79.1-2_all.deb,
使ubuntu系统能识别chkconfig命令
mv /home/hadoop02/chkconfig_11.0-79.1-2_all.deb /usr/software/
更新ubuntu系统需要更新的包:sudo apt-get update
4、安装配置jdk,jdk1.8
把jdk-8u152-linux-x64.tar.gz压缩包进行解压,tar -zxvf jdk-8u152-linux-x64.tar.gz
解压后配置环境变量:修改/etc文件夹下的profile文件,vim profile, insert
export JAVA_HOME=/usr/software/java/jdk1.8.0_152
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
使修改后的文件生效:source profile,检验jdk安装:java -version,javac
配置java开机自启:
vim /etc/bash.bashrc,在末尾加入。编辑配置文件bashrc (该配置文件只对当前用户有效)
#set jdk Start up
export JAVA_HOME=/usr/software/java/jdk1.8.0_152
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
5、安装配置tomcat,apache-tomcat-8.5.27
下载完tomcat文件,把文件移动到指定文件目录:
mv /home/hadoop01/apache-tomcat-8.5.27.tar.gz /usr/software/java
解压tomcat压缩包sudo tar -zxvf apache-tomcat-8.5.27.tar.gz
给当前apache-tomcat-8.5.27文件夹加当前用户权限:sudo chmod 755 -R apache-tomcat-8.5.27
进入目录/usr/software/java/apache-tomcat-8.5.27/bin,编辑文件startup.sh,在最后一行之前加入如下信息:
#set java environment
export JAVA_HOME=/usr/software/java/jdk1.8.0_152
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#tomcat
export TOMCAT_HOME=/usr/software/java/apache-tomcat-8.5.27
编辑后保存退出,sudo ./startup.sh,出现正确启动信息即启动成功。可以在windows下访问该服务器相对应的8080
端口看到tomcat
如果要关闭tomcat,类似的,需要先在文件shutdown.sh对应位置添加信息:
#set java environment
export JAVA_HOME=/usr/software/java/jdk1.8.0_152
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#tomcat
export TOMCAT_HOME=/usr/software/java/apache-tomcat-8.5.27
然后执行如下命令即可:sudo ./shutdown.sh
如果要设置为tomcat开机自启动,需要编辑文件/etc/rc.local,这里存放着开机自启动的程序。(配置在/etc/profile
和/etc/bash.bashrc文件中的内容是当有用户登录时才起作用,这不符合tomcat需要启动的实际情况)
编辑/etc/rc.local:sudo vi /etc/rc.local
在最后一行之前加入如下信息:(配置你自己的tomcat的startup.sh文件的路径)
#set java environment
export JAVA_HOME=/usr/software/java/jdk1.8.0_152
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
/usr/software/java/apache-tomcat-8.5.27/bin/startup.sh
执行命令reboot重启系统,然后即可通过在windows下访问虚拟机的8080端口验证tomcat服务已启动。
☆☆☆配置完tomcat,启动tomcat成功,但是在本机服务器上无法访问tomcat主页,查看tomcat的logs/
目录下的catalina.out的log信息,可能是端口被占用。
如果启动tomcat正常,在本机服务器上能正常访问tomcat主页,但是在外界浏览器上无法访问,则一般是因为
需要把要访问的端口(例如:8080)在系统防火墙上赋予权限:sudo ufw allow 53打开53端口权限
sudo ufw allow 8080/tcp,打开8080端口权限,打开之后在外界浏览器上即可访问。
sudo ufw delete allow 8080/tcp,禁用8080端口
阿里云服务器启动tomcat超慢方法:
在tomcat/bin/catalina.sh中添加如下语句:
JAVA_OPTS="$JAVA_OPTS -Djava.security.egd=file:/dev/./urandom"
查看已经连接的服务端口(ESTABLISHED)
netstat -a
查看所有的服务端口(LISTEN,ESTABLISHED)
netstat -ap
查看指定端口,可以结合grep命令:
netstat -ap | grep 8080
也可以使用lsof命令:lsof -i:8888
若要关闭使用这个端口的程序,使用kill + 对应的pid
kill -9 PID号
6、域名解析

vim /etc/hosts
10.10.100.19 hadoop01
10.10.100.18 hadoop02
10.10.100.17 hadoop03
10.10.100.16 hadoop04
10.10.100.15 hadoop05
7、ssh免密码登陆配置-本机☆☆☆
hadoop01访问hadoop02密码时,通过ssh hadoop02@10.10.100.18然后输入密码访问
以下均在用户目录下执行:/home/hadoop01
1)下载安装ssh服务后,生成公钥密钥
cd /home/hadoop01/
rm -rf .ssh/
生成密匙: ssh-keygen -t rsa
一路回车

2)将公钥追加到 authorized_keys 文件中
cat .ssh/id_rsa.pub >> .ssh/authorized_keys
赋予 authorized_keys 文件权限
chmod 700 .ssh
chmod 600 .ssh/authorized_keys

cat .ssh/authorized_keys
3)验证本机访问自己是否需要密码:ssh localhost
以上是本机免密码登陆
8、ssh免密码登陆配置-联机
把hadoop01的.ssh目录下的authorized_keys文件cope到其它四台计算机的目录下即可完成
hadoop01对其它四台计算机的免密码访问
免登录意义,使集群故障转移时不用密码
scp /home/hadoop01/.ssh/authorized_keys hadoop02@10.10.100.18:/home/hadoop02/.ssh/
scp /home/hadoop01/.ssh/authorized_keys hadoop03@10.10.100.17:/home/hadoop03/.ssh/
scp /home/hadoop01/.ssh/authorized_keys hadoop04@10.10.100.16:/home/hadoop04/.ssh/
scp /home/hadoop01/.ssh/authorized_keys hadoop05@10.10.100.15:/home/hadoop05/.ssh/
配置完以上步骤之后,hadoop01访问其它几台机器都不需要密码,但是其它几台机器访问hadoop01仍需要以下是配置所有机器之间访问不需要密码:
将其它机器的公匙id_ras.pub拷贝到hadoop01节点中的authorized_keys文件中
cat ~/.ssh/id_rsa.pub | ssh hadoop01@10.10.100.19 'cat >> ~/.ssh/authorized_keys'
然后将hadoop01节点的authorized_keys文件分发到其他4个节点上。
scp -r ~/.ssh/authorized_keys hadoop02@10.10.100.18:~/.ssh/
scp -r ~/.ssh/authorized_keys hadoop03@10.10.100.17:~/.ssh/
scp -r ~/.ssh/authorized_keys hadoop04@10.10.100.16:~/.ssh/
scp -r ~/.ssh/authorized_keys hadoop05@10.10.100.15:~/.ssh/
查看各个节点的authorized_keys内容是否一致cat ~/.ssh/authorized_keys
机器之间互相访问,检验是否需要密码,无需密码则表示成功
9、配置root用户免密码登陆
1)首先把root用户ssh设置为可远程访问
vim /etc/ssh/sshd_config
#PermitRootLogin prohibit-password
PermitRootLogin yes
sudo service ssh restart
2)生成密匙
root用户下生成密匙: ssh-keygen -t rsa
将公钥追加到 authorized_keys 文件中
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
赋予 authorized_keys 文件权限
chmod 700 .ssh
chmod 600 .ssh/authorized_keys
cat .ssh/authorized_keys
验证本机访问自己是否需要密码:ssh localhost
3)若需免密登录到hadoop02的root用户,需将公钥追加到/root/.ssh/authorized_keys文件中;
普通用户公钥在/home/.ssh下,root用户公钥在/root/.ssh下。
将其它机器的公匙id_ras.pub拷贝到hadoop01节点中root用户的authorized_keys文件中
hadoop02机器的root用户:cat /root/.ssh/id_rsa.pub | ssh root@10.10.100.19 'cat >> /root/.ssh/authorized_keys'
hadoop03机器的root用户:cat /root/.ssh/id_rsa.pub | ssh root@10.10.100.19 'cat >> /root/.ssh/authorized_keys'
hadoop04机器的root用户:cat /root/.ssh/id_rsa.pub | ssh root@10.10.100.19 'cat >> /root/.ssh/authorized_keys'
hadoop05机器的root用户:cat /root/.ssh/id_rsa.pub | ssh root@10.10.100.19 'cat >> /root/.ssh/authorized_keys'
然后将hadoop01节点的/root/.ssh/authorized_keys文件分发到其他4个节点上。
scp -r /root/.ssh/authorized_keys root@10.10.100.18:~/.ssh/
scp -r /root/.ssh/authorized_keys root@10.10.100.17:~/.ssh/
scp -r /root/.ssh/authorized_keys root@10.10.100.16:~/.ssh/
scp -r /root/.ssh/authorized_keys root@10.10.100.15:~/.ssh/
查看各个节点的authorized_keys内容是否一致cat ~/.ssh/authorized_keys
机器之间互相访问,检验是否需要密码,无需密码则表示成功
ssh root@hadoop01
ssh root@hadoop02
ssh root@hadoop03
ssh root@hadoop04
ssh root@hadoop05
以上验证后,成功则证明root用户也无需填写密码
10、ubuntu批量重启脚本
①单个重启脚本:hadoop-restart.sh
为该shell添加执行权限:chmod u+x hadoop-restart.sh
u代表所有者,x代表执行权限。 + 表示增加权限。
cd /root
#!/bin/bash
sudo reboot
②批量重启脚本
cd /root
all-restart.sh
chmod u+x all-restart.sh
#!/bin/sh
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
HOME=/
ssh hadoop02@10.10.100.18 "bash /home/hadoop02/hadoop-restart.sh"
ssh hadoop03@10.10.100.17 "bash /home/hadoop03/hadoop-restart.sh"
ssh hadoop04@10.10.100.16 "bash /home/hadoop04/hadoop-restart.sh"
ssh hadoop05@10.10.100.15 "bash /home/hadoop05/hadoop-restart.sh"
ssh hadoop01@10.10.100.19 "bash /home/hadoop01/hadoop-restart.sh"
连接到其它机器后,命令执行开始需要有""(双引号),如果需要执行多个命令,命令之间用;(分号)分割
问题1:sudo: no tty present and no askpass program specified
切换到root下,打开sudoers,vim /etc/sudoers,添加面密码:hadoop01 ALL = NOPASSWD: ALL
11、NTP(Network Time Protocol)服务,网络时间协议:使计算机时间同步化的一种协议
①安装npt配置开机启动
下载ntp服务:apt install ntp
找到ntpd所在路径:find / -name ntpd
/etc/apparmor.d/tunables/ntpd
/usr/sbin/ntpd
找到两个位置,但是实际的启动文件叫ntp,在/etc/init.d路径下
配置开机启动:cd /etc/init.d/之后,执行:chkconfig --add ntp

②主节点设置
在配置之前,先使用ntpdate手动同步一下时间,免得本机与对时中心时间差距太大,是的ntpd不能正常同步
这里选127.127.1.0作为对时中心
cd /usr/share/bash-completion/completions/
添加执行权限:chmod +x ntpdate
./ntpdate -u 127.127.1.0
NTP只有一个配置文件:/etc/ntp.conf
vim /etc/ntp.conf
driftfile /var/lib/ntp/ntp.drift
statistics loopstats peerstats clockstats
filegen loopstats file loopstats type day enable
filegen peerstats file peerstats type day enable
filegen clockstats file clockstats type day enable
server 127.127.1.0 prefer
restrict -4 default kod notrap nomodify nopeer noquery limited
restrict -6 default kod notrap nomodify nopeer noquery limited
restrict 127.0.0.1
restrict ::1
restrict source notrap nomodify noquery
重启ntp服务:/etc/init.d/ntp restart
登陆master服务器hadoop01执行/usr/share/bash-completion/completions/ntpdate -u 127.127.1.0
在其它子计算机上都安装ntp,配置以上操作,每台的/etc/ntp.conf中增加server hadoop01
然后重启客户端的ntp服务,sudo /etc/init.d/ntp restart,这样客户端就能和ntp server 进行时间同步了。
登陆到Slave机器,同步主节点执行命令:
/usr/share/bash-completion/completions/ntpdate -u hadoop01
检查是否成功
watch ntpq -p
执行后对比时间
问题记录
系统安装后,确认每台计算机之间可以互相访问:ssh hadoop02@10.10.100.18,可进入hadoop02服务器ssh hadoop01@10.10.100.19,可以进入hadoop01,之前一直出现错误hadoop01不允许访问

查看家目录的.ssh/know_hosts:cat ~/.ssh/known_hosts,knows_hosts是记录远程主机的公钥的文件,之前重装个系统,而保存的公钥还是未重装系统的系统公钥,在ssh链接的时候首先会验证公钥,如果公钥不对,那么就会报错,解决办法:
方法一:将known_hosts文件中的与登录错误的IP的公钥删除,删除之后再ssh即可。
方法二:将known_hosts文件中的内容清空即可,但不建议使用此方法,里面还保存有其他机子的公钥。
方法三:使用shh-keygen 命令(强烈建议使用此方法)比如我们要将172.16.152.209的公钥信息清除,使用命令(请自己将172.16.152.209替换成自己的IP或域名)
ssh-keygen -R 10.10.100.19
Linux路径空间分配
一般来说我们需要一个swap分区,一个/boot分区,一个/usr分区,一个/home分区
/usr分区,是red hat linux系统存放软件的地方,如有可能应将最大空间分给它。
/home分区,是用户的home目录所在地,这个分区的大小取决于有多少用户。如果是多用户共同使用一台电脑的话,这个分区是完全有必要的,况且根用户也可以很好地控制普通用户使用计算机,如对用户或者用户组实行硬盘限量使用,限制普通用户访问哪些文件等。其实单用户也有建立这个分区的必要,因为没这个分区的话,那么你只能以根用户的身份登陆系统,这样做是危险的,因为根用户对系统有绝对的使用权,可一旦你对系统进行了误操作,麻烦也就来了。/boot分区,它包含了操作系统的内核和在启动系统过程中所要用到的文件,建这个分区是有必要的,因为目前大多数的pc机要受到bios的限制,况且如果有了一个单独的/boot启动分区,即使主要的根分区出现了问题,计算机依然能够 启动。这个分区的大小约在50mb—100mb之间。但是如果想用lilo启动系统的话,含有/boot的分区必须完全在柱面1023以下。又由于8gb后的数据lilo不能读取,所以系统要安装在8gb的区域以内。/var存放在一定的时间内需要经常变换数据的分区
但记住至少要有两个分区,一个swap分区,一个/(跟目录)分区。

"/"(根目录)只存放系统相关文件,网站等业务数据不放在这里,同时它也是最大的根目录,最顶层,除了指定的分区,其余的文件都包含在"/"(根目录)目录下面,并且这些并行的文件没有大小限制,且根目录原带的各文件目录下的空间是共享的,但总体大小不能超过"/"跟目录的大小。
例:如果"/"根目录分配空间150GB,"/"根目录下有/usr,/bin,/etc,/dev,/home等原装目录,如果/bin,/etc/dev,/home等目录现在一共占用空间为20GB,那么/usr目录就有130GB可用。如果此时手动添加一个目录/data,给其分配空间为500GB,把data挂载到"/"根目录的某个目录下,那么/data目录的500GB和"/"根目录的150GB存储空间没有任何关系(自己是自己的仓库),且不相互干扰。当然有些目录比如/lib,/dev,/etc,/usr这些都不能挂载其他分区,因为他们都存放着系统需要的文件,一旦被挂载其他分区,那没OS就无法找到所需的文件,系统就会崩溃。

















 1663
1663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











