







我们提出了一个用于分布式机器学习问题的参数服务器框架。数据和工作负载都分布在工作节点上,而服务器节点维护全局共享的参数,这些参数表示为密集或稀疏的向量和矩阵。该框架管理节点之间的异步数据通信,支持灵活的一致性模型、弹性伸缩性和持续的容错。为了演示所提框架的可伸缩性,我们展示了在pb级真实数据上的实验结果,包括数十亿个示例和参数,涉及问题从稀疏逻辑回归到潜在狄利克雷分配和分布式草图。
1 Introduction
分布式优化和推理正在成为解决大规模机器学习问题的先决条件。在规模上,由于数据的增长和由此产生的模型复杂性(通常表现为参数数量的增加),没有任何一台机器能够足够快地解决这些问题。然而,实现有效的分布式算法并不容易。密集的计算工作量和大量的数据通信都要求精心的系统设计。
实际的训练数据量可以在1TB和1PB之间,模型产生大量的参数。这些模型通常被所有工作节点全局共享,当它们执行计算以细化模型时,必须频繁地访问共享的参数。共享带来了三个挑战:
1)访问共享参数,需要大量的范围带宽
2)许多机器学习算法都是顺序的,当在同步机器参数过程中导致机器性能下降,同时同步参数的成本较高
3)在规模上,容错至关重要。学习任务通常在云环境中执行,在云环境中,机器可能不可靠,作业可能被抢占。如图所示,在这里,任务失败主要是由于被抢占或在没有必要的容错机制的情况下丢失了机器。

1.1 Contributions
本文描述了一个参数服务器的第三代开源实现,它关注于分布式推理的系统方面。它存在两个方面的优势,第一个是首先,通过分解出机器学习系统通常需要的组件,它使特定于应用程序的代码保持简洁。
第二次是作为一个以系统级优化为目标的共享平台,它提供了一个健壮的、通用的和高性能的实现,能够处理从稀疏逻辑回归到主题模型和分布式草图的各种算法
该系统的五个主要特征:
1)Efficient communication ,异步通信不会阻碍计算,它针对机器学习任务进行了优化,以减少网络流量和开销。
2)Flexible consistency models 我们允许算法设计者平衡算法收敛速度和系统效率。最好的折衷取决于数据、算法和硬件。
3)Elastic Scalability 无需重新启动正在运行的框架即可添加新节点。
4)Fault Tolerance and Durability 在1秒内从非灾难性机器故障中恢复并修复,不中断计算。矢量时钟确保网络分区和故障后良好的行为。
5)Ease of Use: 全局共享参数被表示为(潜在稀疏)向量和矩阵,以促进机器学习应用程序的开发。
该系统的新颖之处在于,通过选择正确的系统技术,使其适应机器学习算法,并修改机器学习算法,使其更适合系统,从而实现协同作用。特别是,由于相关的机器学习算法对扰动具有相当的容忍度,我们可以放宽一些其他方面的硬系统约束。其结果是第一个通用ML系统能够扩展到工业规模
1.2 Engineering Challenges
在解决分布式数据分析问题时,不同工作节点之间共享参数的读取和更新问题是普遍存在的。参数服务器框架提供了一种高效的机制来聚合和同步模型参数和统计数据。各参数服务器节点保留只是部分参数,每个工作节点在操作时通常只需要这些参数的一个子集。
构建高性能参数服务器系统面临两个关键挑战:
Communication:虽然参数可以在传统的数据存储中作为键值对更新,但天真地使用这种抽象是低效的:值通常很小(浮点数或整数),并且将每次更新作为键值操作发送的开销很大
我们改善这种情况的见解来自于观察到许多学习算法将参数表示为结构化的数学对象,如向量、矩阵或张量。在每个逻辑时间(或迭代),通常是更新对象的一部分。也就是说,工作人员通常发送一个向量的一部分,或者矩阵的一整行。这提供了在参数服务器上自动批处理更新通信及其处理的机会,并允许有效地实现一致性跟踪。
Fault tolerance 如前所述,它在规模上是至关重要的,并且为了高效操作,它必须不需要完全重新启动长时间运行的计算。服务器之间的参数实时复制支持热故障转移。故障转移和自修复分别将机器的移除或添加视为故障或修复,从而支持动态伸缩。
2 Machine Learning
2.1 Goals
许多机器学习算法的目标都可以通过目标函数来表达。这个函数捕获学习到的模型的属性。学习算法通常最小化这个目标函数来获得模型。一般来说,没有封闭形式的解决方案;相反,学习从一个初始模型开始。它通过处理训练数据(可能是多次)迭代地改进这个模型,以接近解决方案。当找到一个(近)最优解或模型被认为是收敛的时候,它就停止。
2.2 Risk Minimization
最直观的机器学习问题是风险最小化

具体使用的损耗函数和正则化函数对机器学习算法的预测性能很重要。我们使用高性能的分布式学习算法来评估参数服务器。为了简单起见,我们描述一个简单得多的模型称为分布次梯度下降
As shown in Figure 2,训练数据在所有工人之间进行分区,共同学习参数向量w。

该算法进行迭代运算。在每次迭代中,每个工人独立使用自己的训练数据来决定应该对w做什么更改,以便更接近最优值。因为每个工人的更新只反映自己的培训数据,系统需要一种机制来允许这些更新混合。它通过将更新表示为次梯度来实现这一点,然后把所有的次梯度都加起来,然后再把它们加到w上。这些梯度通常是按比例缩小的,在算法设计中相当重视正确的学习率η,应该应用,以确保算法快速收敛。这个任务被分配给所有的worker,每个worker都执行WORKERITERATE。
![]()
正在上传…重新上传取消
虽然w的总大小可能超过一台机器的容量,但特定工人所需的工作条目集可以轻松地缓存到本地。随机分配数据分配给工人,然后计算数据集中每个工人的平均工作集大小
3 Architecture

参数服务器节点被分组到一个服务器组和几个工作组,如图4所示。
1.服务器节点维护全局共享参数的一个分区。1)服务器节点相互通信以复制和/或迁移参数,以提高可靠性和可伸缩性,2)服务器节点相互通信以复制和/或迁移参数,以提高可靠性和可伸缩性 3)服务器节点维护一个服务的原信息,比如节点的生成周期
2. worker节点维护一个应用:1)存储本地的数据,用于在本地进行梯度下降计算 2)worker仅仅和server节点进行通信,update和遍历共同的参数 3)每个工作组都有一个调度节点。它给员工分配任务,并监控他们的进度。如果增加或删除工人,它会重新安排未完成的任务。
3.parameter server 支持独立的参数命名空间,这允许工作组将其共享参数集与其他工作组隔离开来。几个工作组也可以共享同一个名称空间
总结上面这样结构类似 于分布式系统中的主从结构,主节点和从节点之间的关系,参数放置到主节点中实现更新和共享。
3.1 (Key,Value) Vectors
节点之间共享的模型可以表示为一组(键、值)对。模型的每个条目都可以通过其键在本地或远程读取和写入。我们的参数服务器通过承认这些关键值项的潜在含义改进了这种基本方法:机器学习算法通常将模型视为线性代数对象。
为了支持这些优化,我们假设键是有序的。这使我们可以将参数视为(键,值)对,同时赋予它们向量和矩阵语义,
3.2 Range Push and Pull
数据通过push和pull操作在节点之间发送
3.3 User-Defined Functions on the Server
3.4 Asynchronous Tasks and Dependency
任务是异步执行的:调用者可以在发出任务后立即执行进一步的计算。只有当调用方收到被调用方的回复时,调用方才将任务标记为已完成。默认情况下,调用者并行执行任务,以获得最佳性能。希望序列化任务执行的调用者可以在任务之间放置一个完成后执行的依赖关系。
3.5 Flexible Consistency
Independent tasks可能导致节点间数据不一致,这种不一致性可能会减缓收敛的进程。系统效率和算法收敛速度之间的最佳平衡通常取决于多种因素,包括算法对数据不一致性的敏感性、训练数据的特征相关性和容量,硬件组成的差异。
![]()
正在上传…重新上传取消
我们展示了可以通过任务依赖实现的三种不同模型

Sequential 顺序一致性是指所有任务依次执行。只有上一个任务完成后,才能启动下一个任务。它产生的结果与单线程实现相同 BSP系统
Eventual 所有任务都可以同时启动 然而,只有在底层算法对延迟具有鲁棒性的情况下,这才是可取的。
Bounded Delay 当设定最大延迟时间τ时,新的任务将被阻塞,直到前几次的所有任务都完成,该模型比前两个模型提供了更灵活的控制:τ = 0是序列一致性模型,无限时滞τ =∞是最终一致性模型。
3.6 User-defined Filters
作为基于调度器的流控制的补充,参数服务器支持用户定义的过滤器来有选择地同步单个(键、值)对,允许细粒度地控制任务中的数据一致性
1. 显著修改的过滤器,它只推送自上次同步以来更改超过阈值的条目
2. KKT
4 Implementation
服务器使用一致的散列[45]存储参数(键-值对)(章节4.3)。对于容错,使用链复制[47]复制条目(第4.4节)。与先前的(键,值)系统不同,参数服务器针对压缩数据(章节4.2)和基于距离的矢量时钟(章节4.1)的基于距离的通信进行了优化。
4.1 Vector Clock
考虑到可能复杂的任务依赖图和快速恢复的需要,每个(键,值)对都与一个矢量时钟[30,15]相关联,它记录了这个(键,值)对上每个节点的时间。由于参数服务器的基于范围的通信模式,许多参数具有相同的时间戳。因此,它们可以被压缩成一个单一的距离矢量时钟。
4.2 Messages
消息由键范围R中的(键,值)对列表和相关的范围向量时钟组成。这是参数服务器的基本通信格式,不仅适用于共享参数,也适用于任务。

消息可能携带r范围内所有可用键的子集。丢失的键被分配相同的时间戳,而不改变它们的值。消息可以按键范围分割。当工作人员向整个服务器组发送消息时,或者当接收节点的键分配发生更改时,就会发生这种情况。
4.3 Consistent Hashing

keys and server节点id都插入到散列环中
每个服务器节点管理键范围,从它的插入点到其他节点逆时针方向的下一个点。此节点称为此键范围的主节点。
4.4 Replication and Consistency
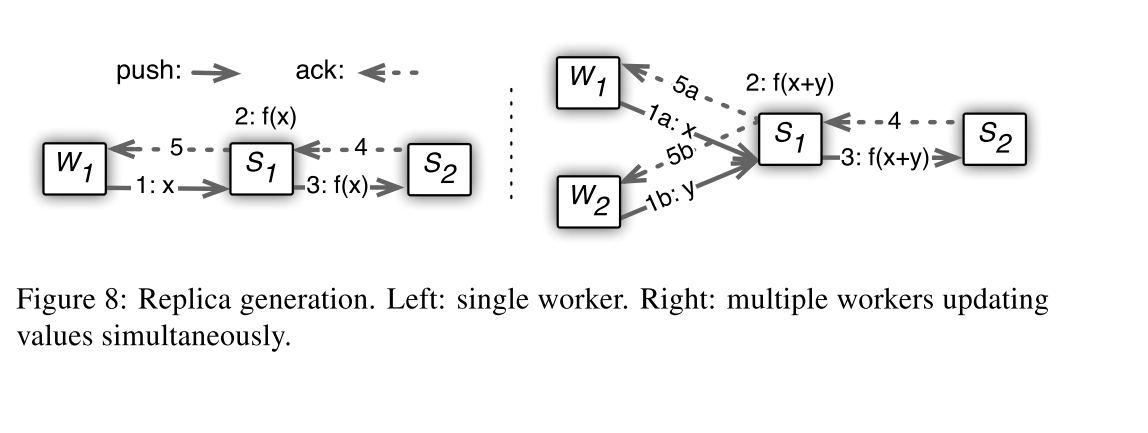
工作节点与键范围的主节点通信,以实现push和pull。对主服务器的任何修改都会连同它的时间戳一起复制到从服务器。对数据的修改被同步地推送到从服务器。
4.5 Server Management
1. 服务管理器为新节点分配一个键范围以充当主节点。这可能导致另一个键范围被分离或从已终止的节点中删除。2. 节点获取作为主节点维护的数据范围和作为从节点保持的另外k个范围。
3.服务器管理器广播节点更改。消息的接收方可以根据不再持有的键范围收缩自己的数据,并将未完成的任务重新提交给新节点。
4.6 Worker Management
1. 任务调度程序为W分配一个数据范围。
2. 该节点从网络文件系统或现有worker加载培训数据范围。训练数据通常是只读的,因此不存在两阶段读取。接下来,W从服务器中提取共享参数。
3.任务调度程序广播更改,可能导致其他工作者释放一些培训数据。
5 Evaluation
我们根据第2节稀疏逻辑回归和潜狄利克雷分配的用例评估我们的参数服务器。我们还展示了草图的结果,以说明我们的框架的一般性。实验是在两个(不同的)大型互联网公司的集群和一个大学研究集群中进行的,以证明我们的方法的多功能性。
5.1 Sparse Logistic Regression
我们收集了一个包含1700亿个样本和650亿个独特功能的广告点击预测数据集。这个数据集是636 TB未压缩(141 TB压缩)。我们在1000台机器上运行参数服务器,每台机器有16个物理核心,192GB DRAM,通过10gb以太网连接,800台机器作为worker, 200台机器是参数服务器。集群在操作期间被其他(不相关的)任务并发使用
Algorithm: 我们用了最先进的分布式回归算法

我们首先通过运行这三个系统来进行比较,以达到相同的客观价值。一个更好的系统可以在更短的时间内实现更低的目标。系统B优于系统A,因为它使用了更好的算法。在使用相同的算法时,参数服务器的性能又优于System B。这是由于它可以有效地减少网络流量和宽松的一致性模型。

宽松一致性模型大大提高了工作节点的利用率。工作者可以开始处理下一个数据块,而无需等待前一个数据块完成,从而隐藏了障碍同步所造成的延迟。

可以看到,允许发送方和接收方缓存密钥可以节省近50%的流量
![]()
正在上传…重新上传取消
首先,1正则化器鼓励使用稀疏模型(w),这样从服务器提取的大多数值都是0。第二,KKT过滤器强制发送到服务器的很大一部分梯度为0。
![]()
正在上传…重新上传取消
Scaling Distributed Machine Learning with the Parameter Server
摘要: 我们提出了一个用于分布式机器学习问题的参数服务器框架。数据和工作负载都分布在工作节点上,而服务器节点维护全局共享的参数,这些参数表示为密集或稀疏的向量和矩阵。该框架管理节点之间的异步数据通信,支持灵活的一致性模型、弹性伸缩性和持续的容错。为了演示所提框架的可伸缩性,我们展示了在pb级真实数据上的实验结果,包括数十亿个示例和参数,涉及问题从稀疏逻辑回归到潜在狄利克雷分配和分布式草图。
1 Introduction
分布式优化和推理正在成为解决大规模机器学习问题的先决条件。在规模上,由于数据的增长和由此产生的模型复杂性(通常表现为参数数量的增加),没有任何一台机器能够足够快地解决这些问题。然而,实现有效的分布式算法并不容易。密集的计算工作量和大量的数据通信都要求精心的系统设计。
实际的训练数据量可以在1TB和1PB之间,模型产生大量的参数。这些模型通常被所有工作节点全局共享,当它们执行计算以细化模型时,必须频繁地访问共享的参数。共享带来了三个挑战:
1)访问共享参数,需要大量的范围带宽
2)许多机器学习算法都是顺序的,当在同步机器参数过程中导致机器性能下降,同时同步参数的成本较高
3)在规模上,容错至关重要。学习任务通常在云环境中执行,在云环境中,机器可能不可靠,作业可能被抢占。如图所示,在这里,任务失败主要是由于被抢占或在没有必要的容错机制的情况下丢失了机器。

1.1 Contributions
本文描述了一个参数服务器的第三代开源实现,它关注于分布式推理的系统方面。它存在两个方面的优势,第一个是首先,通过分解出机器学习系统通常需要的组件,它使特定于应用程序的代码保持简洁。
第二次是作为一个以系统级优化为目标的共享平台,它提供了一个健壮的、通用的和高性能的实现,能够处理从稀疏逻辑回归到主题模型和分布式草图的各种算法
该系统的五个主要特征:
1)Efficient communication ,异步通信不会阻碍计算,它针对机器学习任务进行了优化,以减少网络流量和开销。
2)Flexible consistency models 我们允许算法设计者平衡算法收敛速度和系统效率。最好的折衷取决于数据、算法和硬件。
3)Elastic Scalability 无需重新启动正在运行的框架即可添加新节点。
4)Fault Tolerance and Durability 在1秒内从非灾难性机器故障中恢复并修复,不中断计算。矢量时钟确保网络分区和故障后良好的行为。
5)Ease of Use: 全局共享参数被表示为(潜在稀疏)向量和矩阵,以促进机器学习应用程序的开发。
该系统的新颖之处在于,通过选择正确的系统技术,使其适应机器学习算法,并修改机器学习算法,使其更适合系统,从而实现协同作用。特别是,由于相关的机器学习算法对扰动具有相当的容忍度,我们可以放宽一些其他方面的硬系统约束。其结果是第一个通用ML系统能够扩展到工业规模
1.2 Engineering Challenges
在解决分布式数据分析问题时,不同工作节点之间共享参数的读取和更新问题是普遍存在的。参数服务器框架提供了一种高效的机制来聚合和同步模型参数和统计数据。各参数服务器节点保留只是部分参数,每个工作节点在操作时通常只需要这些参数的一个子集。
构建高性能参数服务器系统面临两个关键挑战:
Communication:虽然参数可以在传统的数据存储中作为键值对更新,但天真地使用这种抽象是低效的:值通常很小(浮点数或整数),并且将每次更新作为键值操作发送的开销很大
我们改善这种情况的见解来自于观察到许多学习算法将参数表示为结构化的数学对象,如向量、矩阵或张量。在每个逻辑时间(或迭代),通常是更新对象的一部分。也就是说,工作人员通常发送一个向量的一部分,或者矩阵的一整行。这提供了在参数服务器上自动批处理更新通信及其处理的机会,并允许有效地实现一致性跟踪。
Fault tolerance 如前所述,它在规模上是至关重要的,并且为了高效操作,它必须不需要完全重新启动长时间运行的计算。服务器之间的参数实时复制支持热故障转移。故障转移和自修复分别将机器的移除或添加视为故障或修复,从而支持动态伸缩。
2 Machine Learning
2.1 Goals
许多机器学习算法的目标都可以通过目标函数来表达。这个函数捕获学习到的模型的属性。学习算法通常最小化这个目标函数来获得模型。一般来说,没有封闭形式的解决方案;相反,学习从一个初始模型开始。它通过处理训练数据(可能是多次)迭代地改进这个模型,以接近解决方案。当找到一个(近)最优解或模型被认为是收敛的时候,它就停止。
2.2 Risk Minimization
最直观的机器学习问题是风险最小化

具体使用的损耗函数和正则化函数对机器学习算法的预测性能很重要。我们使用高性能的分布式学习算法来评估参数服务器。为了简单起见,我们描述一个简单得多的模型称为分布次梯度下降
As shown in Figure 2,训练数据在所有工人之间进行分区,共同学习参数向量w。

该算法进行迭代运算。在每次迭代中,每个工人独立使用自己的训练数据来决定应该对w做什么更改,以便更接近最优值。因为每个工人的更新只反映自己的培训数据,系统需要一种机制来允许这些更新混合。它通过将更新表示为次梯度来实现这一点,然后把所有的次梯度都加起来,然后再把它们加到w上。这些梯度通常是按比例缩小的,在算法设计中相当重视正确的学习率η,应该应用,以确保算法快速收敛。这个任务被分配给所有的worker,每个worker都执行WORKERITERATE。

虽然w的总大小可能超过一台机器的容量,但特定工人所需的工作条目集可以轻松地缓存到本地。随机分配数据分配给工人,然后计算数据集中每个工人的平均工作集大小
3 Architecture

参数服务器节点被分组到一个服务器组和几个工作组,如图4所示。
1.服务器节点维护全局共享参数的一个分区。1)服务器节点相互通信以复制和/或迁移参数,以提高可靠性和可伸缩性,2)服务器节点相互通信以复制和/或迁移参数,以提高可靠性和可伸缩性 3)服务器节点维护一个服务的原信息,比如节点的生成周期
2. worker节点维护一个应用:1)存储本地的数据,用于在本地进行梯度下降计算 2)worker仅仅和server节点进行通信,update和遍历共同的参数 3)每个工作组都有一个调度节点。它给员工分配任务,并监控他们的进度。如果增加或删除工人,它会重新安排未完成的任务。
3.parameter server 支持独立的参数命名空间,这允许工作组将其共享参数集与其他工作组隔离开来。几个工作组也可以共享同一个名称空间
总结上面这样结构类似 于分布式系统中的主从结构,主节点和从节点之间的关系,参数放置到主节点中实现更新和共享。
3.1 (Key,Value) Vectors
节点之间共享的模型可以表示为一组(键、值)对。模型的每个条目都可以通过其键在本地或远程读取和写入。我们的参数服务器通过承认这些关键值项的潜在含义改进了这种基本方法:机器学习算法通常将模型视为线性代数对象。
为了支持这些优化,我们假设键是有序的。这使我们可以将参数视为(键,值)对,同时赋予它们向量和矩阵语义,
3.2 Range Push and Pull
数据通过push和pull操作在节点之间发送
3.3 User-Defined Functions on the Server
3.4 Asynchronous Tasks and Dependency
任务是异步执行的:调用者可以在发出任务后立即执行进一步的计算。只有当调用方收到被调用方的回复时,调用方才将任务标记为已完成。默认情况下,调用者并行执行任务,以获得最佳性能。希望序列化任务执行的调用者可以在任务之间放置一个完成后执行的依赖关系。
3.5 Flexible Consistency
Independent tasks可能导致节点间数据不一致,这种不一致性可能会减缓收敛的进程。系统效率和算法收敛速度之间的最佳平衡通常取决于多种因素,包括算法对数据不一致性的敏感性、训练数据的特征相关性和容量,硬件组成的差异。

我们展示了可以通过任务依赖实现的三种不同模型

Sequential 顺序一致性是指所有任务依次执行。只有上一个任务完成后,才能启动下一个任务。它产生的结果与单线程实现相同 BSP系统
Eventual 所有任务都可以同时启动 然而,只有在底层算法对延迟具有鲁棒性的情况下,这才是可取的。
Bounded Delay 当设定最大延迟时间τ时,新的任务将被阻塞,直到前几次的所有任务都完成,该模型比前两个模型提供了更灵活的控制:τ = 0是序列一致性模型,无限时滞τ =∞是最终一致性模型。
3.6 User-defined Filters
作为基于调度器的流控制的补充,参数服务器支持用户定义的过滤器来有选择地同步单个(键、值)对,允许细粒度地控制任务中的数据一致性
1. 显著修改的过滤器,它只推送自上次同步以来更改超过阈值的条目
2. KKT
4 Implementation
服务器使用一致的散列[45]存储参数(键-值对)(章节4.3)。对于容错,使用链复制[47]复制条目(第4.4节)。与先前的(键,值)系统不同,参数服务器针对压缩数据(章节4.2)和基于距离的矢量时钟(章节4.1)的基于距离的通信进行了优化。
4.1 Vector Clock
考虑到可能复杂的任务依赖图和快速恢复的需要,每个(键,值)对都与一个矢量时钟[30,15]相关联,它记录了这个(键,值)对上每个节点的时间。由于参数服务器的基于范围的通信模式,许多参数具有相同的时间戳。因此,它们可以被压缩成一个单一的距离矢量时钟。
4.2 Messages
消息由键范围R中的(键,值)对列表和相关的范围向量时钟组成。这是参数服务器的基本通信格式,不仅适用于共享参数,也适用于任务。

消息可能携带r范围内所有可用键的子集。丢失的键被分配相同的时间戳,而不改变它们的值。消息可以按键范围分割。当工作人员向整个服务器组发送消息时,或者当接收节点的键分配发生更改时,就会发生这种情况。
4.3 Consistent Hashing

keys and server节点id都插入到散列环中
每个服务器节点管理键范围,从它的插入点到其他节点逆时针方向的下一个点。此节点称为此键范围的主节点。
4.4 Replication and Consistency

工作节点与键范围的主节点通信,以实现push和pull。对主服务器的任何修改都会连同它的时间戳一起复制到从服务器。对数据的修改被同步地推送到从服务器。
4.5 Server Management
1. 服务管理器为新节点分配一个键范围以充当主节点。这可能导致另一个键范围被分离或从已终止的节点中删除。2. 节点获取作为主节点维护的数据范围和作为从节点保持的另外k个范围。
3.服务器管理器广播节点更改。消息的接收方可以根据不再持有的键范围收缩自己的数据,并将未完成的任务重新提交给新节点。
4.6 Worker Management
1. 任务调度程序为W分配一个数据范围。
2. 该节点从网络文件系统或现有worker加载培训数据范围。训练数据通常是只读的,因此不存在两阶段读取。接下来,W从服务器中提取共享参数。
3.任务调度程序广播更改,可能导致其他工作者释放一些培训数据。
5 Evaluation
我们根据第2节稀疏逻辑回归和潜狄利克雷分配的用例评估我们的参数服务器。我们还展示了草图的结果,以说明我们的框架的一般性。实验是在两个(不同的)大型互联网公司的集群和一个大学研究集群中进行的,以证明我们的方法的多功能性。
5.1 Sparse Logistic Regression
我们收集了一个包含1700亿个样本和650亿个独特功能的广告点击预测数据集。这个数据集是636 TB未压缩(141 TB压缩)。我们在1000台机器上运行参数服务器,每台机器有16个物理核心,192GB DRAM,通过10gb以太网连接,800台机器作为worker, 200台机器是参数服务器。集群在操作期间被其他(不相关的)任务并发使用
Algorithm: 我们用了最先进的分布式回归算法

我们首先通过运行这三个系统来进行比较,以达到相同的客观价值。一个更好的系统可以在更短的时间内实现更低的目标。系统B优于系统A,因为它使用了更好的算法。在使用相同的算法时,参数服务器的性能又优于System B。这是由于它可以有效地减少网络流量和宽松的一致性模型。

宽松一致性模型大大提高了工作节点的利用率。工作者可以开始处理下一个数据块,而无需等待前一个数据块完成,从而隐藏了障碍同步所造成的延迟。

可以看到,允许发送方和接收方缓存密钥可以节省近50%的流量

首先,1正则化器鼓励使用稀疏模型(w),这样从服务器提取的大多数值都是0。第二,KKT过滤器强制发送到服务器的很大一部分梯度为0。

最后,我们分析了有界时滞一致性模型。不同最大允许时滞(τ)下实现相同收敛准则的工作器时间分解
最后,我们分析了有界时滞一致性模型。不同最大允许时滞(τ)下实现相同收敛准则的工作器时间分解














 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









